











Le modèle et la notation des processus métiers (BPMN) servent de langue universelle pour la modélisation des processus. Toutefois, un diagramme ne contenant que des tâches et des passerelles échoue souvent à capturer la réalité complète du fonctionnement d’une entreprise. La substance d’un processus réside dans les données qui le traversent. Sans visualiser les entrées et sorties de données, un diagramme BPMN reste une structure squelettique plutôt qu’un plan fonctionnel. Ce guide explore comment représenter efficacement le flux de données, assurant ainsi clarté, précision et utilité dans vos modèles de processus.
Lors de la modélisation de flux de travail complexes, les parties prenantes doivent comprendre non seulement ce qui se produit, mais quelles informations qui motive ces actions. Une visualisation appropriée des données évite toute ambiguïté lors de la mise en œuvre et facilite l’intégration des systèmes. En respectant les normes BPMN 2.0, vous pouvez créer des diagrammes qui communiquent simultanément la logique et les exigences de données.
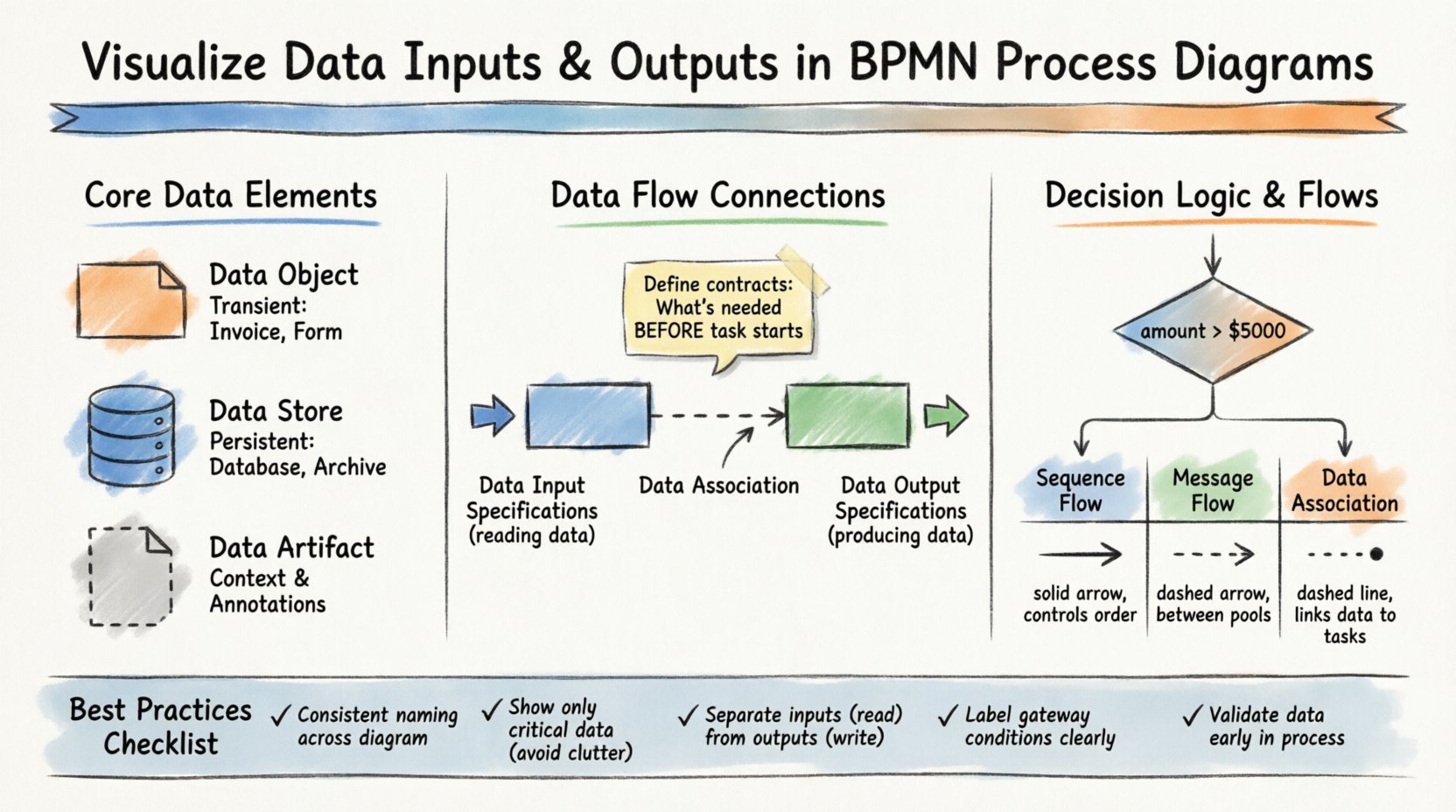
🏗️ Comprendre les éléments de données fondamentaux dans BPMN
Pour visualiser correctement les données, il faut distinguer les différents types d’artefacts de données disponibles dans la notation. Confondre ces éléments peut entraîner des malentendus sur l’emplacement du stockage des informations, la manière dont elles sont transmises ou le moment où elles sont générées.
📄 Objets de données
Les objets de données représentent des informations créées ou consommées lors de l’exécution d’un processus. Ils sont temporaires et existent généralement uniquement pendant la durée de l’instance du processus. Pensez-y comme des documents, formulaires ou dossiers qui apparaissent sur un bureau pendant une réunion.
- Définition : Un symbole indiquant que des données sont impliquées dans une tâche ou un événement spécifique.
- Utilisation : Attachez-le aux tâches pour montrer ce qui est lu ou écrit.
- Style visuel : Un rectangle avec un coin plié.
- Exemple : Une « facture » générée par une tâche « Traiter le paiement ».
Les objets de données sont essentiels pour montrer les besoins immédiats d’une tâche. Si une tâche nécessite une signature client, un objet de données représentant le « contrat signé » doit être visible. Cela signale au lecteur que la tâche ne peut pas être achevée sans cette entrée spécifique.
🗃️ Magasins de données
Contrairement aux objets de données, les magasins de données représentent des répertoires persistants. Ce sont des bases de données, des systèmes de fichiers ou des systèmes externes où les informations sont conservées à long terme. Dans un diagramme, ils indiquent d’où proviennent les données ou où elles sont archivées.
- Définition : Un symbole indiquant une base de données ou un mécanisme de stockage.
- Utilisation : Connectez-le aux tâches ou aux pools pour montrer la persistance des données.
- Style visuel : Une forme cylindrique.
- Exemple : Une « base de données clients » ou un « archivage des commandes ».
Utiliser correctement les magasins de données permet de faire la distinction entre les informations temporaires et les enregistrements permanents. Cette distinction est essentielle pour la gouvernance des données et les exigences de conformité.
📋 Artifacts de données
Bien qu’il ne s’agisse pas strictement de données, les artifacts de données fournissent un contexte supplémentaire sur les données utilisées. Ils sont souvent utilisés pour expliquer la source ou la destination d’un jeu de données sans impliquer un flux direct.
- Définition :Annotations qui décrivent les exigences de données.
- Utilisation :Préciser les formats de données ou les sources.
- Style visuel :Une icône de document avec une connexion en pointillés.
🔗 Connecter les données aux tâches : entrées et sorties
L’aspect le plus critique de la visualisation des données dans BPMN est de les relier aux activités qui les consomment ou les produisent. Cela est réalisé grâce àSpécifications d’entrée de données et Spécifications de sortie de données. Ce ne sont pas simplement des éléments décoratifs ; ils définissent le contrat entre le processus et les données.
📥 Spécifications d’entrée de données
Toute tâche traitant des informations nécessite une entrée. Dans BPMN, cela est explicitement modélisé pour s’assurer qu’aucune hypothèse n’est faite. Une tâche ne doit jamais dépendre de données implicites. Vous devez définir quelles données sont nécessaires avant le début de la tâche.
- Rôle :Définit les données nécessaires pour démarrer une tâche.
- Association :Connecté à la tâche via une ligne d’association de données.
- Validation :Assure que la tâche dispose de toutes les variables nécessaires avant son exécution.
- Exemple :Une tâche « Examiner la demande » nécessite le « Formulaire de demande » en entrée.
Lors de la modélisation des entrées, considérez si les données sont obligatoires ou facultatives. Si une tâche ne peut pas progresser sans données spécifiques, elles doivent être clairement marquées. Cela réduit les erreurs lors du développement des flux automatisés.
📤 Spécifications de sortie de données
Les tâches produisent également des résultats. Ces résultats peuvent être de nouveaux objets de données ou des mises à jour de magasins de données existants. Visualiser les sorties garantit que les tâches en aval savent quelles informations sont disponibles pour elles.
- Rôle :Définit les données produites par une tâche.
- Association : Connecté à la tâche par une ligne d’association de données.
- Propagation : Rend les données disponibles pour les tâches ou événements ultérieurs.
- Exemple : Une tâche « Approuver un prêt » produit un « Document de prêt approuvé ».
Des définitions de sortie claires empêchent les silos de données. Si une tâche crée un document, la tâche suivante doit faire référence à ce document de manière explicite. Cela crée une chaîne de custody traçable pour les informations au sein du processus.
⚖️ Logique des données dans les passerelles et les décisions
Les données ne circulent pas uniquement de manière linéaire ; elles dictent souvent le parcours d’un processus. Les passerelles prennent des décisions en fonction des valeurs des données. Visualiser ces conditions est essentiel pour comprendre comment les données pilotent les branches du processus.
🔢 Passerelles exclusives et conditions sur les données
Une passerelle exclusive (forme de losange) divise le processus en un seul chemin parmi plusieurs. Le chemin suivi dépend de l’évaluation des données. Pour visualiser cela, vous devez annoter les flux de séquence sortants avec des conditions basées sur les données.
- Condition : Une expression booléenne (par exemple,
montant > 5000). - Source : Les données doivent être disponibles au niveau de la passerelle.
- Clarté : Étiquetez chaque chemin avec la valeur de données spécifique qui le déclenche.
Par exemple, si un processus achemine les commandes en fonction de leur valeur, la passerelle doit clairement indiquer le seuil. Si la valeur des données change, le chemin change. Cette logique doit être visible pour les parties prenantes qui pourraient ne pas comprendre le code sous-jacent.
🔄 Passerelles inclusives et parallèles
Alors que les passerelles exclusives choisissent un seul chemin, les passerelles inclusives peuvent en choisir plusieurs en fonction des données. Les passerelles parallèles divisent et regroupent les flux indépendamment des données, mais elles opèrent souvent sur des jeux de données créés par des tâches précédentes.
- Passerelle inclusive : Active les chemins où les conditions sur les données sont évaluées à vrai.
- Passerelle parallèle : Active tous les chemins simultanément ; les flux de données sont synchronisés.
Lors de la visualisation des données dans ces scénarios, assurez-vous que les données nécessaires pour chaque branche parallèle sont clairement définies. Si la branche A nécessite « ID client » et la branche B « ID commande », les deux entrées doivent être visibles avant la séparation parallèle.
💬 Flux de messages vs. flux de données
Un point courant de confusion dans BPMN est la distinction entre les flux de séquence, les flux de messages et les associations de données. Comprendre cette différence est essentiel pour une visualisation précise.
| Type de flux | Portée | Fonction | Représentation visuelle |
|---|---|---|---|
| Flux de séquence | Dans un pool | Contrôle l’ordre des tâches | Flèche pleine |
| Flux de message | Entre des pools/participants | Échange des messages | Flèche pointillée |
| Association de données | Dans un pool | Lie les données aux tâches | Ligne pointillée (non directionnelle) |
Les flux de message transportent les données elles-mêmes à travers les frontières. Lorsqu’un client envoie une commande, le flux de message transporte les données de la commande. Les flux de séquence transportent le contrôle, pas les données. Les associations de données relient les objets de données abstraits aux tâches qui les traitent.
Lors de la modélisation des interactions externes, utilisez les flux de message pour montrer que les données quittent la frontière du processus. Utilisez les associations de données pour montrer qu’une tâche lit dans une base de données locale. Mélanger ces éléments peut induire en erreur les développeurs qui mettent en œuvre les points d’intégration.
🛡️ Meilleures pratiques pour la visualisation des données
Pour maintenir des diagrammes de haute qualité, suivez ces pratiques établies. La cohérence réduit la charge cognitive pour quiconque examine le modèle.
- Nommage cohérent :Utilisez toujours le même nom pour un objet de données dans l’ensemble du diagramme. Si c’est « Facture » dans la tâche A, ne l’appelez pas « Bon » dans la tâche B.
- Encombrement minimal :N’attachez pas chaque variable individuelle à une tâche. Montrez uniquement les données essentielles à la compréhension du processus.
- Regroupement logique :Regroupez les objets de données liés ensemble. Si une tâche implique « Adresse de livraison » et « Adresse de facturation », gardez-les visuellement proches.
- Contrôle de version :Si la structure des données change, mettez à jour le diagramme. Les modèles de données obsolètes entraînent des mises en œuvre infructueuses.
- Séparation entrée/sortie :Distinguez clairement ce qui est lu (entrée) et ce qui est écrit (sortie). Cela aide à identifier les tâches en lecture seule par rapport aux tâches intensives en écriture.
🚧 Pièges courants à éviter
Même les modélisateurs expérimentés commettent des erreurs lors de la représentation des données. Reconnaître ces erreurs courantes aide à affiner vos diagrammes.
🕵️ Associations de données manquantes
Un problème fréquent est de supposer que les données existent sans les montrer. Si une tâche calcule un total, d’où provient le prix ? Si l’objet de données est absent du diagramme, la logique du processus est incomplète.
🔁 Dépendances circulaires de données
Assurez-vous que les données circulent logiquement. Une tâche ne doit pas dépendre de données produites par une tâche future dans le même flux de séquence. Cela crée un paradoxe logique qui ne peut pas être exécuté.
🧩 Sur-spécification
Ne modélisez pas chaque champ de base de données. Concentrez-vous sur les données pertinentes pour l’entreprise. Si une tâche traite une « commande », vous n’avez pas besoin de lister chaque champ d’identifiant interne, sauf s’il affecte le flux du processus.
🔗 Confusion entre les flux de message et les flux de séquence
N’utilisez jamais un flux de message pour représenter un flux de contrôle au sein d’un seul pool. Les flux de message sont réservés à la communication entre participants. Leur utilisation incorrecte viole les règles sémantiques de la notation.
📋 Comparaison détaillée des spécifications de données
Le tableau suivant détaille les attributs spécifiques trouvés dans les spécifications d’entrée et de sortie de données au sein d’une définition de tâche. Comprendre ces attributs permet une modélisation précise.
| Attribut | Spécification d’entrée de données | Spécification de sortie de données |
|---|---|---|
| Direction | Lire / Consommer | Écrire / Produire |
| Moment | Avant l’exécution de la tâche | Après l’exécution de la tâche |
| Transformation | Peut nécessiter un mappage à partir de la source | Peut nécessiter un mappage vers la destination |
| Dépendance | Obligatoire au démarrage | Résultat de la complétion |
En comprenant ces distinctions, vous pouvez créer des diagrammes qui reflètent fidèlement le cycle de vie des données. Cette précision est particulièrement importante lors de la traduction d’un modèle en code de workflow exécutable.
🔄 Intégration des données dans les processus pilotés par des événements
Les processus commencent souvent par des événements. Ces événements portent fréquemment des données. Par exemple, un « événement de démarrage par message » peut être déclenché lorsqu’une charge utile XML spécifique est reçue.
- Événements de démarrage : Peut avoir des entrées de données définies. Le processus ne peut pas démarrer tant que les données ne sont pas présentes.
- Événements intermédiaires :Peut capturer des données pendant l’exécution, par exemple un « événement minuterie » qui démarre après une date spécifique.
- Événements de fin :Peut générer des sorties de données, par exemple un « événement d’arrêt » qui enregistre un état final.
Visualiser les données au niveau de l’événement garantit que les limites du processus sont claires. Elle définit précisément les informations qui entrent dans le système et celles qui en sortent. Cela est crucial pour la conception d’API et l’intégration système.
📈 Mesure de l’efficacité du flux de données
Une fois votre diagramme terminé, vous pouvez utiliser les données visualisées pour analyser l’efficacité du processus. Recherchez les goulets d’étranglement où les données sont bloquées ou dupliquées.
- Entrées redondantes :Si plusieurs tâches lisent le même objet de données, envisagez si ces données pourraient être mises en cache ou transmises directement.
- Latence des sorties :Si une tâche produit des données qui ne sont pas utilisées immédiatement par la tâche suivante, ces données restent inactives.
- Points de validation :Assurez-vous que la validation des données se fait tôt. Si une tâche produit des données non valides, les tâches suivantes échoueront.
En analysant le flux de données, vous pouvez optimiser le processus avant même qu’il ne soit codé. Cette approche proactive permet d’économiser un temps de développement important et de réduire les erreurs en temps d’exécution.
🔍 Résumé des étapes de mise en œuvre
Pour mettre en œuvre ces techniques de visualisation dans vos propres travaux de modélisation, suivez cette approche structurée.
- Identifier les entités de données :Listez tous les documents, enregistrements et variables utilisés dans le processus.
- Mapper aux tâches :Attribuez les objets de données à des tâches spécifiques en fonction de leur cycle de vie.
- Définir les spécifications :Marquez les tâches comme Entrée, Sortie ou Entrée/Sortie.
- Connecter les flux :Utilisez des associations de données pour relier les objets aux tâches.
- Vérifier les conditions :Vérifiez que les passerelles ont des conditions claires basées sur les données.
- Valider la cohérence :Vérifiez que les noms et les types sont cohérents sur l’ensemble du diagramme.
Cette méthode systématique garantit que aucune exigence de données n’est négligée. Elle transforme un simple organigramme en un document de spécification complet.
🤝 Collaboration et communication avec les parties prenantes
Enfin, rappelez-vous que BPMN est un outil de communication. L’objectif est de garantir que les analystes métiers, les développeurs et les gestionnaires comprennent tous le processus de la même manière.
- Parties prenantes métiers : Concentrez-vous sur les objets de données (documents) qu’ils reconnaissent.
- Développeurs : Concentrez-vous sur les spécifications de données et les mappages d’entrée/sortie.
- Gestionnaires : Concentrez-vous sur les magasins de données et sur l’emplacement où les informations sont conservées.
En adaptant le niveau de détail des données au public cible, vous assurez que le diagramme reste utile pour tous les participants. Une visualisation claire comble le fossé entre l’intention métier et l’exécution technique.
Lorsque vous privilégiez la visualisation des entrées et sorties de données, vous créez des modèles solides, précis et prêts à être exécutés. Le processus devient bien plus qu’une simple suite d’étapes : il devient un flux cohérent d’informations. C’est ce niveau de détail qui distingue un modèle théorique d’une solution concrète.
Adopter ces pratiques exige de la discipline, mais le résultat est une compréhension plus claire de la manière dont votre entreprise fonctionne réellement. Chaque tâche, décision et message devient traçable. Cette traçabilité est la fondation de l’excellence moderne des processus.

