











El Modelo y Notación de Procesos de Negocio (BPMN) sirve como el lenguaje universal para el modelado de procesos. Sin embargo, un diagrama que contiene únicamente tareas y puertas de decisión a menudo no logra capturar la realidad completa de cómo opera un negocio. La esencia de un proceso reside en los datos que lo recorren. Sin visualizar las entradas y salidas de datos, un diagrama BPMN permanece como una estructura esquelética en lugar de un plano funcional. Esta guía explora cómo representar de forma efectiva el flujo de datos, asegurando claridad, precisión y utilidad en sus modelos de procesos.
Al modelar flujos de trabajo complejos, los interesados necesitan comprender no soloquéocurre, sino tambiénqué informaciónimpulsa esas acciones. Una visualización adecuada de los datos evita ambigüedades durante la implementación y facilita la integración del sistema. Al adherirse a las normas BPMN 2.0, puede crear diagramas que comuniquen simultáneamente la lógica y los requisitos de datos.
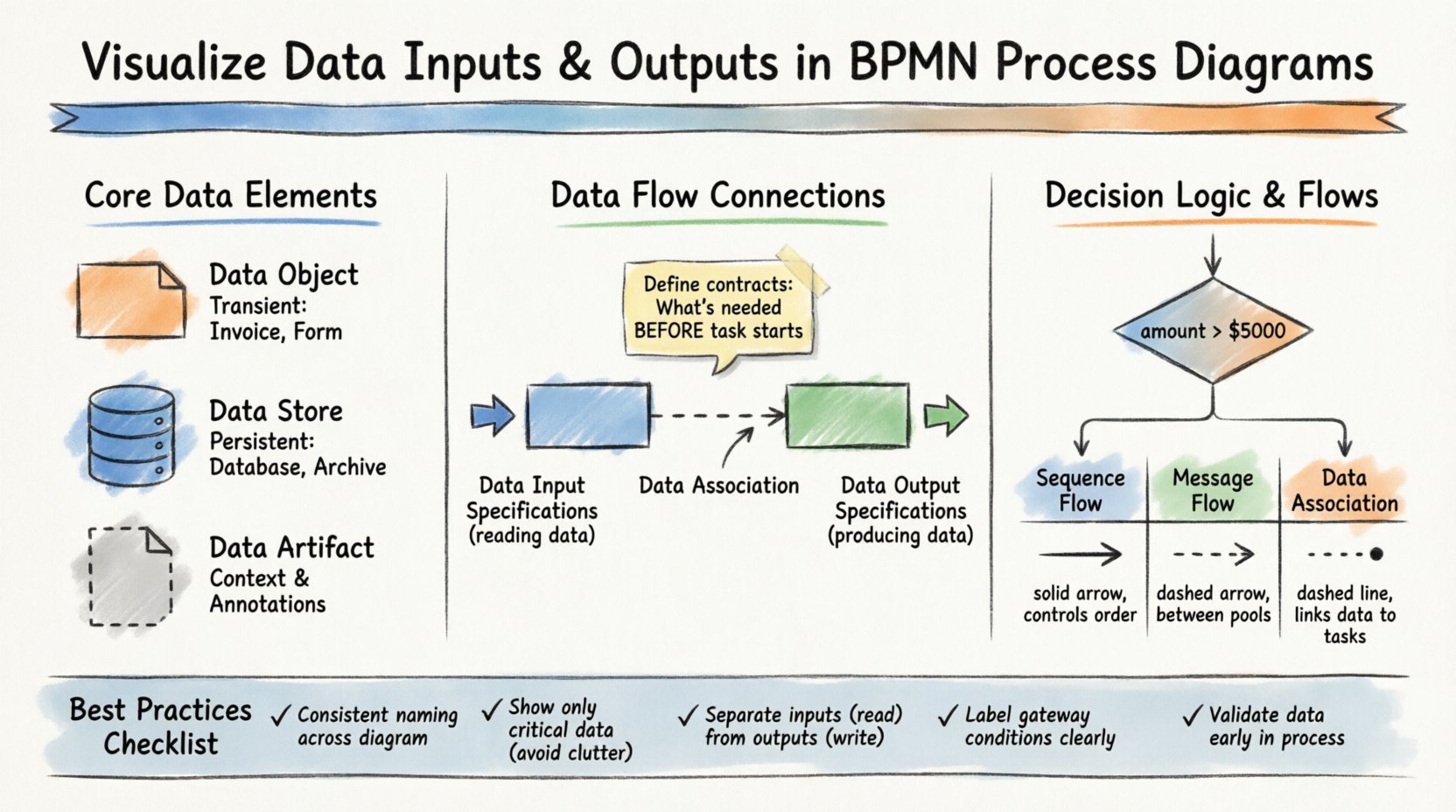
🏗️ Comprender los elementos de datos principales en BPMN
Para visualizar correctamente los datos, es necesario distinguir entre los diferentes tipos de artefactos de datos disponibles en la notación. Confundir estos elementos puede generar malentendidos sobre dónde se almacena la información, cómo se transfiere o cuándo se genera.
📄 Objetos de datos
Los objetos de datos representan información que se crea o consume durante la ejecución de un proceso. Son transitorios y normalmente existen solo durante la duración de una instancia del proceso. Piénselos como documentos, formularios o registros que aparecen sobre una mesa durante una reunión.
- Definición:Un símbolo que indica que los datos están involucrados en una tarea o evento específico.
- Uso:Adjúntelos a tareas para mostrar qué se lee o se escribe.
- Estilo visual:Un rectángulo con una esquina doblada.
- Ejemplo:Una “Factura” generada por una tarea “Procesar pago”.
Los objetos de datos son cruciales para mostrar las necesidades inmediatas de una tarea. Si una tarea requiere una firma del cliente, debe ser visible un objeto de datos que represente el “Contrato firmado”. Esto indica al lector que la tarea no puede completarse sin esta entrada específica.
🗃️ Almacenes de datos
A diferencia de los objetos de datos, los almacenes de datos representan repositorios persistentes. Estos son bases de datos, sistemas de archivos o sistemas externos donde la información se guarda para su retención a largo plazo. En un diagrama, indican dónde proviene la data o dónde se archiva.
- Definición:Un símbolo que indica una base de datos o un mecanismo de almacenamiento.
- Uso:Conéctelos a tareas o grupos para mostrar la persistencia de datos.
- Estilo visual:Una forma cilíndrica.
- Ejemplo:Una “Base de datos de clientes” o “Archivo de pedidos”.
Utilizar correctamente los almacenes de datos ayuda a distinguir entre la información temporal y los registros permanentes. Esta distinción es vital para los requisitos de gobernanza de datos y cumplimiento.
📋 Artefactos de datos
Aunque no son estrictamente datos, los artefactos de datos proporcionan contexto adicional sobre los datos que se están utilizando. A menudo se utilizan para explicar la fuente o el destino de un conjunto de datos sin implicar un flujo directo.
- Definición:Anotaciones que describen los requisitos de datos.
- Uso:Aclarar formatos de datos o fuentes.
- Estilo visual:Un icono de documento con una conexión de línea punteada.
🔗 Conectando datos a tareas: Entradas y salidas
El aspecto más crítico de visualizar datos dentro de BPMN es vincularlos a las actividades que los consumen o producen. Esto se logra medianteEspecificaciones de entrada de datos y Especificaciones de salida de datos. Estos no son solo elementos decorativos; definen el contrato entre el proceso y los datos.
📥 Especificaciones de entrada de datos
Cada tarea que procesa información necesita entrada. En BPMN, esto se modela explícitamente para asegurar que no se asuma nada. Una tarea nunca debe depender de datos implícitos. Debe definirse qué datos son necesarios antes de que comience la tarea.
- Rol:Define los datos necesarios para iniciar una tarea.
- Asociación:Conectado a la tarea mediante una línea de asociación de datos.
- Validación:Asegura que la tarea tenga todas las variables necesarias antes de su ejecución.
- Ejemplo:Una tarea de «Revisar solicitud» requiere el «Formulario de solicitud» como entrada.
Al modelar entradas, considere si los datos son obligatorios o opcionales. Si una tarea no puede continuar sin datos específicos, debe marcarse claramente. Esto reduce los errores durante el desarrollo de flujos de trabajo automatizados.
📤 Especificaciones de salida de datos
Las tareas también producen resultados. Estos resultados pueden ser nuevos objetos de datos o actualizaciones a almacenes de datos existentes. Visualizar las salidas asegura que las tareas posteriores sepan qué información está disponible para ellas.
- Rol:Define los datos producidos por una tarea.
- Asociación:Conectado a la tarea mediante una línea de asociación de datos.
- Propagación:Hace que los datos estén disponibles para tareas o eventos posteriores.
- Ejemplo:Una tarea de «Aprobar préstamo» genera un «Documento de préstamo aprobado».
Las definiciones claras de salida evitan los silos de datos. Si una tarea crea un documento, la siguiente tarea debe referirse a ese documento explícitamente. Esto crea una cadena trazable de custodia de la información dentro del proceso.
⚖️ Lógica de datos en puertas y decisiones
Los datos no solo fluyen de forma lineal; a menudo determinan el camino de un proceso. Las puertas toman decisiones basadas en valores de datos. Visualizar estas condiciones es esencial para comprender cómo los datos impulsan el bifurcación del proceso.
🔢 Puertas exclusivas y condiciones de datos
Una puerta exclusiva (forma de diamante) divide el proceso en una de varias rutas. La ruta que se sigue depende de la evaluación de los datos. Para visualizar esto, debe anotar los flujos de secuencia salientes con condiciones basadas en datos.
- Condición: Una expresión booleana (por ejemplo,
monto > 5000). - Origen:Los datos deben estar disponibles en el punto de la puerta.
- Claridad:Etiquete cada ruta con el valor de datos específico que la desencadena.
Por ejemplo, si un proceso enruta pedidos según su valor, la puerta debe mostrar claramente el umbral. Si el valor de datos cambia, la ruta también cambia. Esta lógica debe ser visible para los interesados que podrían no entender el código subyacente.
🔄 Puertas inclusivas y paralelas
Mientras que las puertas exclusivas eligen una ruta, las puertas inclusivas pueden elegir múltiples rutas basadas en datos. Las puertas paralelas dividen y unen flujos independientemente de los datos, pero a menudo operan sobre conjuntos de datos creados por tareas anteriores.
- Puerta inclusiva:Activa las rutas donde las condiciones de datos se evalúan como verdaderas.
- Puerta paralela:Activa todas las rutas simultáneamente; los flujos de datos están sincronizados.
Al visualizar datos en estos escenarios, asegúrese de que los datos requeridos para cada rama paralela estén claramente definidos. Si la rama A necesita «ID de cliente» y la rama B necesita «ID de pedido», ambos entradas deben ser visibles antes de la división paralela.
💬 Flujos de mensajes frente a flujos de datos
Un punto común de confusión en BPMN es la distinción entre flujos de secuencia, flujos de mensajes y asociaciones de datos. Comprender esta diferencia es clave para una visualización precisa.
| Tipo de flujo | Alcance | Función | Representación visual |
|---|---|---|---|
| Flujo de secuencia | Dentro de un Pool | Controla el orden de las tareas | Flecha sólida |
| Flujo de mensaje | Entre pools/participantes | Intercambia mensajes | Flecha punteada |
| Asociación de datos | Dentro de un Pool | Enlaza datos a tareas | Línea punteada (no direccional) |
Los flujos de mensaje transportan los datos en sí mismos a través de los límites. Cuando un cliente envía un pedido, el flujo de mensaje transporta los datos del pedido. Los flujos de secuencia transportan el control, no los datos. Las asociaciones de datos vinculan los objetos de datos abstractos con las tareas que los procesan.
Al modelar interacciones externas, use flujos de mensaje para mostrar que los datos están saliendo del límite del proceso. Use asociaciones de datos para mostrar que una tarea está leyendo desde una base de datos local. Confundir estos elementos puede generar confusión en los desarrolladores que están construyendo los puntos de integración.
🛡️ Mejores prácticas para la visualización de datos
Para mantener diagramas de alta calidad, siga estas prácticas establecidas. La consistencia reduce la carga cognitiva para cualquier persona que revise el modelo.
- Nomenclatura consistente:Siempre use el mismo nombre para un objeto de datos en todo el diagrama. Si se llama «Factura» en la Tarea A, no lo llame «Factura» en la Tarea B.
- Mínimo desorden:No adjunte cada variable individual a una tarea. Muestre solo los datos que son críticos para comprender el proceso.
- Agrupación lógica:Agrupe los objetos de datos relacionados juntos. Si una tarea implica «Dirección de envío» y «Dirección de facturación», manténgalos visualmente cercanos.
- Control de versiones:Si la estructura de datos cambia, actualice el diagrama. Los modelos de datos desactualizados conducen a implementaciones fallidas.
- Separación de entrada/salida:Distinga claramente entre lo que se lee (entrada) y lo que se escribe (salida). Esto ayuda a identificar tareas de solo lectura frente a tareas con alta carga de escritura.
🚧 Errores comunes que deben evitarse
Incluso los modeladores con experiencia cometen errores al representar datos. Reconocer estos errores comunes ayuda a perfeccionar sus diagramas.
🕵️ Asociaciones de datos faltantes
Uno de los problemas frecuentes es asumir que los datos existen sin mostrarlos. Si una tarea calcula un total, ¿de dónde proviene el precio? Si el objeto de datos falta en el diagrama, la lógica del proceso es incompleta.
🔁 Dependencias circulares de datos
Asegúrese de que los datos fluyan lógicamente. Una tarea no debe depender de datos que sean producidos por una tarea futura en el mismo flujo de secuencia. Esto crea un paradoja lógica que no puede ejecutarse.
🧩 Sobredeterminación
No modele cada campo de base de datos individualmente. Enfóquese en los datos relevantes para el negocio. Si una tarea procesa una “Orden”, no necesita listar cada campo de ID interno a menos que afecte el flujo del proceso.
🔗 Confundir flujos de mensaje y flujos de secuencia
Nunca use un flujo de mensaje para mostrar el flujo de control dentro de un solo pool. Los flujos de mensaje están reservados para la comunicación entre participantes. Usarlos incorrectamente rompe las reglas semánticas de la notación.
📋 Comparación detallada de especificaciones de datos
La siguiente tabla desglosa los atributos específicos encontrados en las especificaciones de entrada y salida de datos dentro de una definición de tarea. Comprender estos atributos permite un modelado preciso.
| Atributo | Especificación de entrada de datos | Especificación de salida de datos |
|---|---|---|
| Dirección | Lectura / Consumo | Escritura / Producción |
| Tiempo | Antes de la ejecución de la tarea | Después de la ejecución de la tarea |
| Transformación | Puede requerir mapeo desde la fuente | Puede requerir mapeo hacia el destino |
| Dependencia | Obligatorio para el inicio | Resultado de la finalización |
Al comprender estas diferencias, puede crear diagramas que reflejen con precisión el ciclo de vida de los datos. Esta precisión es especialmente importante al traducir un modelo en código de flujo de trabajo ejecutable.
🔄 Integración de datos en procesos impulsados por eventos
Los procesos a menudo comienzan con eventos. Estos eventos a menudo llevan datos. Por ejemplo, un “Evento de inicio por mensaje” podría activarse cuando se recibe una carga útil XML específica.
- Eventos de inicio: Puede tener entradas de datos definidas. El proceso no puede comenzar hasta que los datos estén presentes.
- Eventos intermedios: Puede capturar datos durante la ejecución, como un “Evento de temporizador” que comienza después de una fecha específica.
- Eventos finales: Puede generar salidas de datos, como un “Evento de finalización” que guarda un registro de estado final.
Visualizar los datos a nivel de evento asegura que los límites del proceso sean claros. Define exactamente qué información entra al sistema y qué sale de él. Esto es fundamental para el diseño de API y la integración de sistemas.
📈 Medición de la eficiencia del flujo de datos
Una vez que tu diagrama esté completo, puedes usar los datos visualizados para analizar la eficiencia del proceso. Busca cuellos de botella donde los datos se queden atrapados o se dupliquen.
- Entradas redundantes: Si múltiples tareas leen el mismo objeto de datos, considera si esos datos podrían almacenarse en caché o pasarse directamente.
- Latencia de salida: Si una tarea produce datos que no son utilizados inmediatamente por la siguiente tarea, los datos permanecen inactivos.
- Puntos de validación: Asegúrate de que la validación de datos ocurra temprano. Si una tarea produce datos inválidos, las tareas posteriores fallarán.
Al analizar el flujo de datos, puedes optimizar el proceso antes de que se codifique. Este enfoque proactivo ahorra tiempo de desarrollo significativo y reduce los errores en tiempo de ejecución.
🔍 Resumen de los pasos de implementación
Para implementar estas técnicas de visualización en tus propios esfuerzos de modelado, sigue este enfoque estructurado.
- Identificar entidades de datos: Lista todos los documentos, registros y variables utilizados en el proceso.
- Asignar a tareas: Asigna objetos de datos a tareas específicas según su ciclo de vida.
- Definir especificaciones: Marca las tareas como Entrada, Salida o Entrada/Salida.
- Conectar flujos: Usa asociaciones de datos para vincular objetos a tareas.
- Revisar condiciones: Verifica que las puertas tengan condiciones claras basadas en datos.
- Validar consistencia: Comprueba que los nombres y tipos coincidan en todo el diagrama.
Este método sistemático asegura que ninguna necesidad de datos se pase por alto. Transforma un diagrama de flujo simple en un documento de especificaciones completo.
🤝 Colaboración y comunicación con partes interesadas
Por último, recuerda que BPMN es una herramienta de comunicación. El objetivo es garantizar que analistas de negocios, desarrolladores y gerentes entiendan el proceso de la misma manera.
- Partes interesadas del negocio: Enfóquese en los objetos de datos (documentos) que reconocen.
- Desarrolladores: Enfóquese en las especificaciones de datos y los mapeos de entrada/salida.
- Gerentes: Enfóquese en los almacenes de datos y dónde se conserva la información.
Al adaptar el nivel de detalle de los datos al público objetivo, garantizas que el diagrama siga siendo útil para todos los involucrados. Una visualización clara cierra la brecha entre la intención del negocio y la ejecución técnica.
Cuando priorizas la visualización de entradas y salidas de datos, creas modelos robustos, precisos y listos para su ejecución. El proceso deja de ser solo una secuencia de pasos y se convierte en un flujo coherente de información. Este nivel de detalle es lo que diferencia un modelo teórico de una solución práctica.
Adoptar estas prácticas requiere disciplina, pero el resultado es una comprensión más clara de cómo funciona realmente tu negocio. Cada tarea, decisión y mensaje se vuelve trazable. Esta trazabilidad es la base de la excelencia en procesos modernos.

