











ビジネスプロセスモデルと表記法(BPMN)は、プロセスモデリングのための普遍的な言語として機能します。しかし、タスクとゲートウェイだけを含む図では、企業が実際にどのように運営されているかの全貌を捉えるのが難しくなります。プロセスの本質は、その中を移動するデータにあります。データの入力と出力を可視化しない限り、BPMN図は機能的な設計図ではなく、骨格的な構造に留まります。このガイドでは、データフローを効果的に表現する方法を検討し、プロセスモデルにおける明確性、正確性、および使いやすさを確保します。
複雑なワークフローをモデル化する際、関係者は単に何が起こっているかを理解するだけでなく、どのような情報がその行動を引き起こしているかを理解する必要があります。データの適切な可視化は、実装段階での曖昧さを防ぎ、システム統合を支援します。BPMN 2.0の基準に従うことで、論理とデータ要件の両方を同時に伝える図を構築できます。
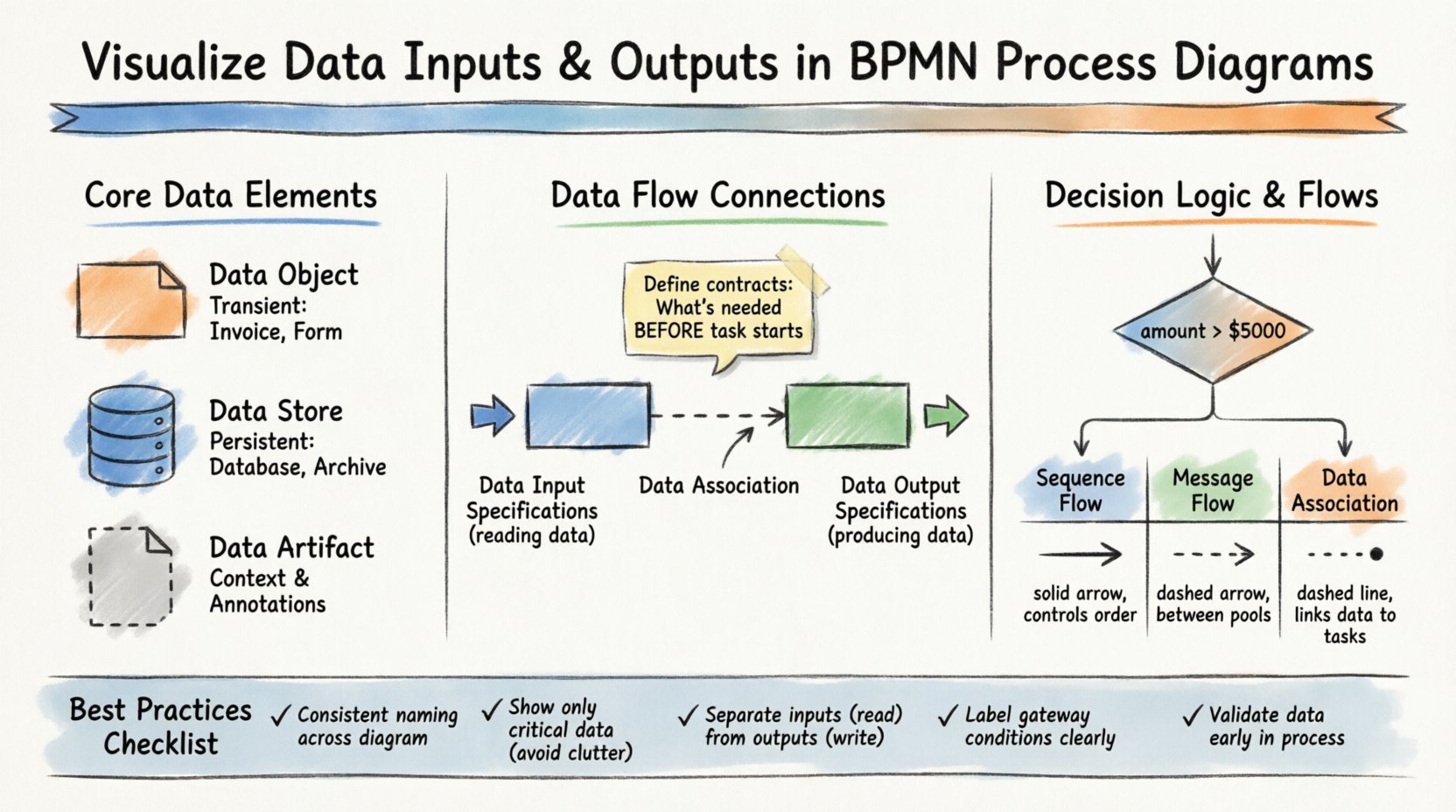
🏗️ BPMNにおけるコアデータ要素の理解
データを正しく可視化するためには、表記法で利用可能なさまざまな種類のデータアーティファクトを区別する必要があります。これらの要素を混同すると、情報がどこに保存されているか、どのように渡されるか、またはいつ生成されるかについての誤解が生じる可能性があります。
📄 データオブジェクト
データオブジェクトは、プロセスの実行中に作成または消費される情報を表します。これらは一時的であり、通常はプロセスインスタンスの期間中だけ存在します。会議中に机の上に現れる文書、フォーム、または記録を想像してください。
- 定義:特定のタスクまたはイベントに関連するデータが存在することを示す記号。
- 使用法:タスクに接続して、読み取りまたは書き込み対象の内容を示す。
- 視覚的スタイル:折り返しのある角を持つ長方形。
- 例:「支払い処理」タスクによって生成される「請求書」。
データオブジェクトは、タスクの即時的な要件を示すために不可欠です。たとえば、タスクに顧客の署名が必要な場合、「署名済み契約」を表すデータオブジェクトが可視化されるべきです。これにより、読者はこの特定の入力がなければタスクが完了できないことを明確に理解できます。
🗃️ データストア
データオブジェクトとは異なり、データストアは永続的なリポジトリを表します。これらは、情報が長期保存のために保存されるデータベース、ファイルシステム、または外部システムです。図では、データがどこから来ているか、またはどこにアーカイブされているかを示します。
- 定義:データベースまたはストレージメカニズムを示す記号。
- 使用法:タスクやプールに接続して、データの永続性を示す。
- 視覚的スタイル:円筒形。
- 例:「顧客データベース」または「注文アーカイブ」。
データストアを正しく使用することで、一時的な情報と恒久的な記録の違いを明確にできます。この区別は、データガバナンスおよびコンプライアンス要件において極めて重要です。
📋 データアーティファクト
厳密にはデータではないが、データアーティファクトは使用されているデータに関する追加的な文脈を提供します。データセットのソースや宛先を説明するためによく使用され、直接的な流れを示すものではないことを意図しています。
- 定義:データ要件を説明する注釈。
- 使用法:データ形式やソースを明確にする。
- 視覚スタイル:破線で接続されたドキュメントアイコン。
🔗 データをタスクに接続する:入力と出力
BPMN内でデータを可視化する上で最も重要な点は、それを消費または生成する活動にリンクすることです。これはデータ入力仕様 および データ出力仕様によって実現されます。これらは装飾的な要素ではなく、プロセスとデータの間の契約を定義します。
📥 データ入力仕様
情報を処理するすべてのタスクには入力が必要です。BPMNでは、何も仮定しないように明示的にモデル化されています。タスクは絶対に暗黙のデータに依存してはいけません。タスクを開始する前に、必要なデータを明確に定義しなければなりません。
- 役割:タスクの開始に必要なデータを定義する。
- 関連:データ関連線を介してタスクに接続される。
- 検証:実行前にタスクがすべての必要な変数を持っていることを保証する。
- 例:「申請書のレビュー」タスクは、「申請書」を入力として必要とする。
入力をモデル化する際には、データが必須かオプションかを検討してください。特定のデータがなければタスクが進行できない場合は、明確にマークする必要があります。これにより、自動ワークフローの開発中に発生するエラーを減らすことができます。
📤 データ出力仕様
タスクは結果も生成します。これらの結果は新しいデータオブジェクトである場合もあれば、既存のデータストアの更新である場合もあります。出力を可視化することで、下流のタスクが利用可能な情報を把握できるようになります。
- 役割:タスクによって生成されるデータを定義する。
- 関連:データ関連線を通じてタスクに接続されている。
- 伝播:データを次のタスクやイベントで利用可能にする。
- 例:「ローン承認」タスクは「承認済みローン文書」を生成する。
明確な出力定義はデータの島(データ・サイロ)を防ぐ。タスクが文書を作成する場合、次のタスクはその文書を明示的に参照すべきである。これにより、プロセス内の情報について追跡可能な所有権の連鎖が構築される。
⚖️ ゲートウェイと意思決定におけるデータ論理
データは単に線形に流れることだけではなく、プロセスの経路を決定する場合も多い。ゲートウェイはデータの値に基づいて意思決定を行う。これらの条件を可視化することは、データがプロセスの分岐をどのように駆動しているかを理解するために不可欠である。
🔢 排他的ゲートウェイとデータ条件
排他的ゲートウェイ(ダイヤモンド型)はプロセスを複数の経路のうちの一つに分岐させる。選ばれる経路はデータの評価に依存する。これを可視化するには、出力されるシーケンスフローにデータに基づく条件を注釈する必要がある。
- 条件: ブール式(例:
金額 > 5000). - ソース:データはゲートウェイの位置で利用可能でなければならない。
- 明確さ:各経路に、その経路をトリガーする特定のデータ値をラベル付けする。
例えば、プロセスが金額に基づいて注文をルーティングする場合、ゲートウェイは明確にしきい値を示さなければならない。データ値が変化すれば、経路も変化する。この論理は、下層のコードを理解できないステークホルダーにも可視化されなければならない。
🔄 包含的および並行ゲートウェイ
排他的ゲートウェイが一つの経路を選択するのに対し、包含的ゲートウェイはデータに基づいて複数の経路を選択できる。並行ゲートウェイはデータにかかわらずフローを分岐・結合するが、しばしば前のタスクによって作成されたデータセットを扱う。
- 包含的ゲートウェイ:データ条件が真と評価される経路を有効化する。
- 並行ゲートウェイ:すべての経路を同時に有効化する。データの流れは同期される。
これらのシナリオでデータを可視化する際は、各並行ブランチに必要なデータが明確に定義されていることを確認する。Branch Aが「顧客ID」を必要とし、Branch Bが「注文ID」を必要とする場合、並行分岐の前に両方の入力が可視化されているべきである。
💬 メッセージフローとデータフローの違い
BPMNにおけるよくある混乱のポイントは、シーケンスフロー、メッセージフロー、データ関連の違いである。この違いを理解することが、正確な可視化の鍵となる。
| フローの種類 | 範囲 | 機能 | 視覚的表現 |
|---|---|---|---|
| シーケンスフロー | プール内 | タスクの順序を制御する | 実線矢印 |
| メッセージフロー | プール/参加者間 | メッセージを交換する | 破線矢印 |
| データ関連 | プール内 | データをタスクに関連付ける | 破線(方向性なし) |
メッセージフローはデータそのものを境界を越えて伝達します。顧客が注文を送信するとき、メッセージフローは注文データを伝達します。シーケンスフローはデータではなく制御を伝達します。データ関連は抽象的なデータオブジェクトをそれらを処理するタスクにリンクします。
外部の相互作用をモデル化する際は、メッセージフローを使用してデータがプロセス境界を越えて出ることを示してください。タスクがローカルデータベースから読み取っていることを示すにはデータ関連を使用してください。これらを混同すると、統合ポイントを構築している開発者が混乱する可能性があります。
🛡️ データ可視化のベストプラクティス
高品質な図を維持するためには、これらの確立された実践を守ってください。一貫性があることで、モデルを確認する誰にとっても認知負荷が軽減されます。
- 一貫した命名:図全体でデータオブジェクトに同じ名前を使用してください。Task Aで「Invoice」と呼ばれているものについては、Task Bでは「Bill」とは呼びません。
- 最小限のごちゃごちゃ:すべての変数をタスクに接続しないでください。プロセスの理解に不可欠なデータのみを表示してください。
- 論理的なグループ化:関連するデータオブジェクトを一緒にグループ化してください。タスクが「配送先住所」と「請求先住所」を扱う場合、視覚的に近くに配置してください。
- バージョン管理:データ構造が変更された場合は、図を更新してください。古くなったデータモデルは実装の失敗を招きます。
- 入力/出力の分離:読み込まれるもの(入力)と書き込まれるもの(出力)を明確に区別してください。これにより、読み取り専用のタスクと書き込みが重いタスクを識別しやすくなります。
🚧 避けるべき一般的な落とし穴
経験豊富なモデラーでさえ、データを表現する際に誤りを犯すことがあります。こうした一般的な誤りを認識することで、図の精度を高めることができます。
🕵️ データ関連の欠落
よくある問題の一つは、データが存在すると仮定してそれを表示しないことです。たとえば、タスクが合計を計算する場合、価格はどこから来るのでしょうか?データオブジェクトが図に存在しない場合、プロセスの論理は不完全になります。
🔁 データ依存関係の循環
データの流れが論理的であることを確認してください。同じシーケンスフロー内の将来のタスクによって生成されるデータに依存してはいけません。これにより、実行できない論理的パラドックスが生じます。
🧩 過剰な仕様化
すべてのデータベースフィールドをモデル化する必要はありません。ビジネスに関連するデータに注目してください。たとえばタスクが「注文」を処理する場合、プロセスフローに影響を与えない限り、すべての内部IDフィールドを列挙する必要はありません。
🔗 メッセージフローとシーケンスフローの混同
単一のプール内の制御フローを示すために、メッセージフローを使用してはいけません。メッセージフローは参加者間の通信にのみ使用されます。誤って使用すると、記法の意味論的なルールが破られます。
📋 データ仕様の詳細な比較
以下の表は、タスク定義内のデータ入力および出力仕様に含まれる具体的な属性を分解しています。これらの属性を理解することで、正確なモデリングが可能になります。
| 属性 | データ入力仕様 | データ出力仕様 |
|---|---|---|
| 方向 | 読み取り / 消費 | 書き込み / 生産 |
| タイミング | タスク実行前 | タスク実行後 |
| 変換 | ソースからのマッピングが必要になる可能性がある | 宛先へのマッピングが必要になる可能性がある |
| 依存関係 | 開始に必須 | 完了の結果 |
これらの違いを理解することで、データライフサイクルを正確に反映する図を構築できます。この正確さは、モデルを実行可能なワークフローコードに変換する際に特に重要です。
🔄 イベント駆動型プロセスへのデータ統合
プロセスはしばしばイベントから始まります。これらのイベントは頻繁にデータを伴います。たとえば、「メッセージスタートイベント」は特定のXMLペイロードが受信されたときに発動する可能性があります。
- スタートイベント: データ入力を定義できる。データが存在するまでプロセスは開始できない。
- 中間イベント: 実行中にデータをキャプチャできる。たとえば、特定の日付後に開始する「タイマーイベント」などがある。
- 終了イベント: データ出力を生成できる。たとえば、最終ステータス記録を保存する「終了イベント」などがある。
イベントレベルでのデータ可視化により、プロセスの境界が明確になる。システムに入力される情報と、システムから出力される情報が正確に定義される。これはAPI設計およびシステム統合において極めて重要である。
📈 データフロー効率の測定
図が完成したら、可視化されたデータを使ってプロセスの効率を分析できる。データが停止している、または重複しているボトルネックを確認する。
- 重複する入力: 複数のタスクが同じデータオブジェクトを読み込む場合、そのデータをキャッシュするか、直接渡すようにするか検討する。
- 出力遅延: タスクが次のタスクによって直ちに使用されないデータを生成する場合、そのデータは無駄に待機する。
- 検証ポイント: データ検証を早期に行うことを確保する。タスクが無効なデータを生成すると、下流のタスクは失敗する。
データフローを分析することで、コード化する前からプロセスを最適化できる。この予防的なアプローチにより、開発時間を大幅に節約し、実行時エラーを削減できる。
🔍 実装手順の要約
これらの可視化技術を自身のモデリング作業に実装するには、この構造的なアプローチに従う。
- データエンティティの特定: プロセスで使用されるすべての文書、レコード、変数をリストアップする。
- タスクへのマッピング: データオブジェクトをライフサイクルに基づいて、特定のタスクに割り当てる。
- 仕様の定義: タスクに「入力」「出力」「入力/出力」のいずれかをマークする。
- フローの接続: データ関連を使用してオブジェクトをタスクに接続する。
- 条件の確認: ゲートウェイが明確なデータに基づく条件を持っていることを確認する。
- 一貫性の検証: 図全体で名前と型が一致しているか確認する。
この体系的な方法により、データ要件が見逃されることがない。単なるフローチャートを包括的な仕様書に変換する。
🤝 コラボレーションとステークホルダーとのコミュニケーション
最後に、BPMNはコミュニケーションツールであることを忘れないでください。目的は、ビジネスアナリスト、開発者、マネージャーがすべて同じようにプロセスを理解することを確実にすることです。
- ビジネス関係者: データオブジェクト(文書)に注目する。彼らが認識しているもの。
- 開発者: データ仕様および入出力のマッピングに注目する。
- マネージャー: データストアおよび情報が保持される場所に注目する。
データの詳細度を対象となる audience に合わせることで、図がすべての関係者にとって有用であることを保証します。明確な可視化は、ビジネスの意図と技術的実行の間のギャップを埋めます。
データの入力と出力を可視化することを優先することで、堅牢で正確かつ実行可能なモデルを作成できます。プロセスは単なるステップの連続ではなく、一貫した情報の流れになります。この詳細度こそが、理論的なモデルと実用的なソリューションを分ける要因です。
これらの実践を採用するには、自制心が必要ですが、その結果、あなたのビジネスが実際にどのように機能しているかをより明確に理解できるようになります。すべてのタスク、意思決定、メッセージが追跡可能になります。この追跡可能性こそが、現代のプロセスエクセレンスの基盤です。

