











Business Process Model and Notation (BPMN) dient als universelle Sprache für die Prozessmodellierung. Ein Diagramm, das nur Aufgaben und Gateways enthält, erfasst jedoch oft nicht die volle Wirklichkeit, wie ein Unternehmen funktioniert. Der Kern eines Prozesses liegt in den Daten, die durch ihn fließen. Ohne die Visualisierung von Daten-Eingaben und -Ausgaben bleibt ein BPMN-Diagramm eine skelettartige Struktur statt eines funktionalen Bauplans. Dieser Leitfaden untersucht, wie Sie den Datenfluss effektiv darstellen können, um Klarheit, Genauigkeit und Nutzbarkeit in Ihren Prozessmodellen sicherzustellen.
Beim Modellieren komplexer Workflows müssen Stakeholder nicht nur verstehen, dass was geschieht, sondern auch, dass welche Informationen diese Aktionen antreibt. Eine korrekte Visualisierung von Daten vermeidet Unklarheiten während der Implementierung und unterstützt die Systemintegration. Durch Einhaltung der BPMN 2.0-Standards können Sie Diagramme erstellen, die gleichzeitig Logik und Datenanforderungen vermitteln.
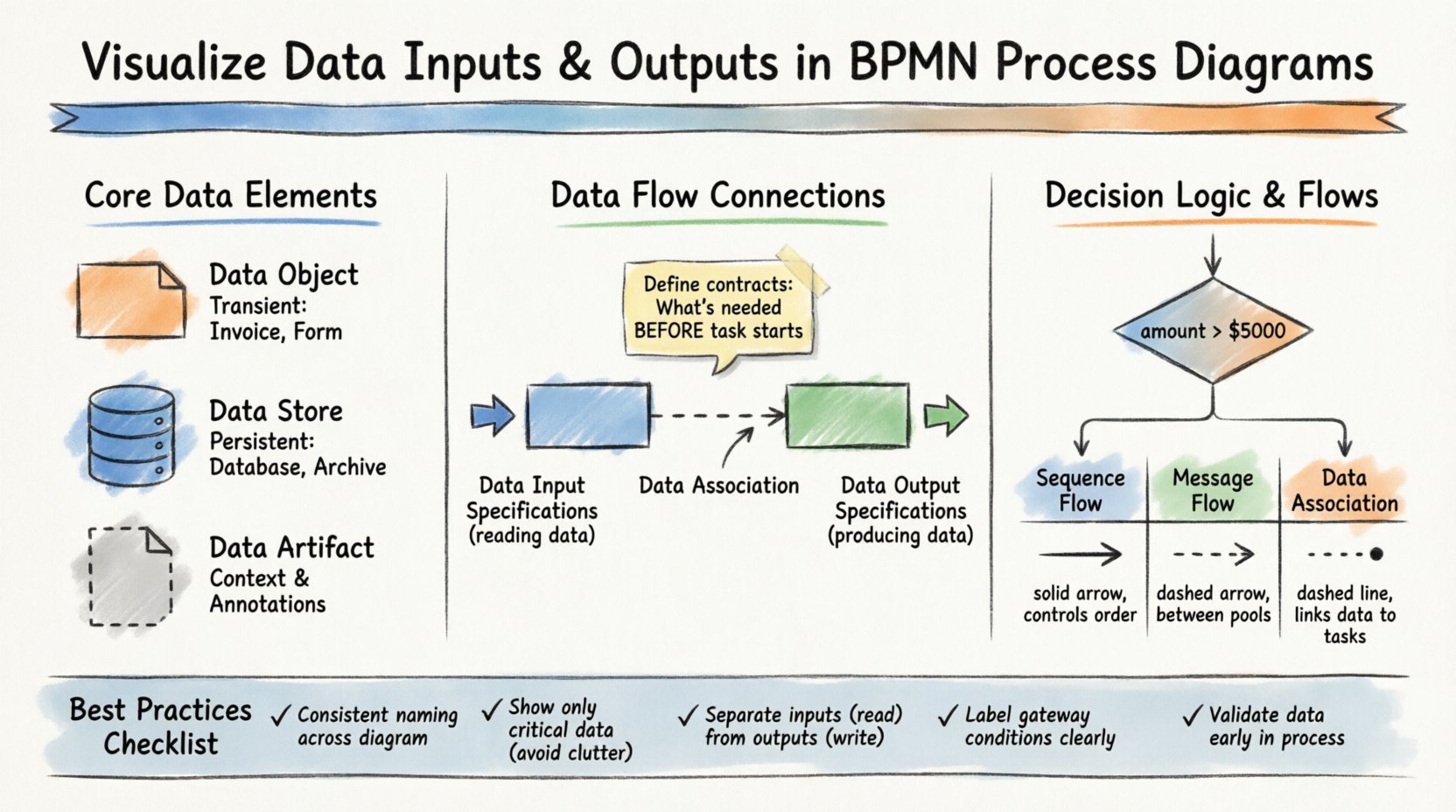
🏗️ Verständnis der zentralen Daten-Elemente in BPMN
Um Daten korrekt zu visualisieren, muss man zwischen den verschiedenen Arten von Daten-Artefakten in der Notation unterscheiden. Die Verwechslung dieser Elemente kann zu Missverständnissen darüber führen, wo Informationen gespeichert werden, wie sie weitergegeben werden oder wann sie erzeugt werden.
📄 Datenobjekte
Datenobjekte stellen Informationen dar, die während der Ausführung eines Prozesses erstellt oder verbraucht werden. Sie sind temporär und existieren typischerweise nur für die Dauer einer Prozessinstanz. Stellen Sie sich sie als Dokumente, Formulare oder Akten vor, die während einer Besprechung auf einem Schreibtisch liegen.
- Definition: Ein Symbol, das anzeigt, dass Daten an einer bestimmten Aufgabe oder einem Ereignis beteiligt sind.
- Verwendung: An Aufgaben anhängen, um anzugeben, was gelesen oder geschrieben wird.
- Visueller Stil: Ein Rechteck mit einem umgeklappten Eck.
- Beispiel: Eine „Rechnung“, die von einer „Zahlung bearbeiten“-Aufgabe erzeugt wird.
Datenobjekte sind entscheidend, um die unmittelbaren Anforderungen einer Aufgabe zu zeigen. Wenn eine Aufgabe eine Kundensignatur erfordert, sollte ein Datenobjekt, das den „Unterschriebenen Vertrag“ darstellt, sichtbar sein. Dies signalisiert dem Leser, dass die Aufgabe ohne diese spezifische Eingabe nicht abgeschlossen werden kann.
🗃️ Datenbanken
Im Gegensatz zu Datenobjekten stellen Datenbanken dauerhafte Speicherorte dar. Es handelt sich um Datenbanken, Dateisysteme oder externe Systeme, in denen Informationen für die langfristige Aufbewahrung gespeichert werden. In einem Diagramm zeigen sie an, wo Daten entstehen oder archiviert werden.
- Definition: Ein Symbol, das eine Datenbank oder Speichermechanismus anzeigt.
- Verwendung: An Aufgaben oder Pools anbinden, um Datenpersistenz zu zeigen.
- Visueller Stil: Eine zylindrische Form.
- Beispiel: Eine „Kunden-Datenbank“ oder „Bestell-Archiv“.
Die richtige Verwendung von Datenspeichern hilft, zwischen temporären Informationen und dauerhaften Aufzeichnungen zu unterscheiden. Diese Unterscheidung ist für die Datenverwaltung und Compliance-Anforderungen von entscheidender Bedeutung.
📋 Datenartefakte
Obwohl Datenartefakte nicht streng genommen Daten sind, liefern sie zusätzlichen Kontext über die verwendeten Daten. Sie werden häufig verwendet, um die Quelle oder das Ziel eines Datensatzes zu erklären, ohne eine direkte Datenflussbeziehung zu implizieren.
- Definition:Anmerkungen, die Datenanforderungen beschreiben.
- Verwendung:Klärung von Datenformaten oder Quellen.
- Visueller Stil:Ein Dokument-Symbol mit einer gestrichelten Verbindungslinie.
🔗 Verbindung von Daten mit Aufgaben: Eingaben und Ausgaben
Der wichtigste Aspekt der Visualisierung von Daten innerhalb von BPMN ist die Verknüpfung mit den Aktivitäten, die sie verbrauchen oder erzeugen. Dies wird erreicht durchDaten-Eingabespezifikationen und Daten-Ausgabespezifikationen. Diese sind nicht nur dekorative Elemente; sie definieren den Vertrag zwischen dem Prozess und den Daten.
📥 Daten-Eingabespezifikationen
Jede Aufgabe, die Informationen verarbeitet, benötigt Eingaben. In BPMN wird dies explizit modelliert, um sicherzustellen, dass nichts implizit angenommen wird. Eine Aufgabe sollte niemals auf implizite Daten angewiesen sein. Sie müssen definieren, welche Daten vor Beginn der Aufgabe erforderlich sind.
- Rolle:Definiert die Daten, die benötigt werden, um eine Aufgabe zu starten.
- Zuordnung:Verbunden mit der Aufgabe über eine Daten-Zuordnungsverbindung.
- Validierung:Stellt sicher, dass die Aufgabe alle notwendigen Variablen vor der Ausführung besitzt.
- Beispiel:Eine Aufgabe „Antrag prüfen“ erfordert „Antragsformular“ als Eingabe.
Bei der Modellierung von Eingaben sollten Sie berücksichtigen, ob die Daten obligatorisch oder optional sind. Wenn eine Aufgabe ohne bestimmte Daten nicht fortgesetzt werden kann, muss dies deutlich gekennzeichnet werden. Dies reduziert Fehler bei der Entwicklung automatisierter Workflows.
📤 Daten-Ausgabespezifikationen
Aufgaben erzeugen ebenfalls Ergebnisse. Diese Ergebnisse können neue Datenobjekte oder Aktualisierungen bestehender Datenspeicher sein. Die Visualisierung von Ausgaben stellt sicher, dass nachfolgende Aufgaben wissen, welche Informationen für sie verfügbar sind.
- Rolle:Definiert die Daten, die von einer Aufgabe erzeugt werden.
- Zuordnung: Verbunden mit der Aufgabe über eine Datenzuordnungsleitung.
- Weiterleitung: Stellt die Daten für nachfolgende Aufgaben oder Ereignisse zur Verfügung.
- Beispiel: Eine Aufgabe „Darlehen genehmigen“ erzeugt ein „Genehmigtes Darlehensdokument“.
Klare Ausgabedefinitionen verhindern Dateninseln. Wenn eine Aufgabe ein Dokument erzeugt, sollte die nächste Aufgabe dieses Dokument explizit referenzieren. Dadurch entsteht eine nachvollziehbare Kette der Verantwortung für Informationen innerhalb des Prozesses.
⚖️ Datenlogik in Gateways und Entscheidungen
Daten fließen nicht nur linear; sie bestimmen oft den Verlauf eines Prozesses. Gateways treffen Entscheidungen basierend auf Datenwerten. Die Visualisierung dieser Bedingungen ist entscheidend, um zu verstehen, wie Daten die Verzweigung des Prozesses steuern.
🔢 Exklusive Gateways und Datenbedingungen
Ein exklusiver Gateway (die rautenförmige Form) teilt den Prozess in eine der mehreren möglichen Pfade auf. Der gewählte Pfad hängt von der Auswertung von Daten ab. Um dies zu visualisieren, müssen Sie die ausgehenden Ablauflinien mit datenbasierten Bedingungen versehen.
- Bedingung: Ein boolescher Ausdruck (z. B.
Betrag > 5000). - Quelle: Die Daten müssen am Punkt des Gateways verfügbar sein.
- Klarheit: Kennzeichnen Sie jeden Pfad mit dem spezifischen Datenwert, der ihn auslöst.
Zum Beispiel muss ein Gateway, das Aufträge basierend auf ihrem Wert weiterleitet, die Schwelle deutlich anzeigen. Wenn sich der Datenwert ändert, ändert sich auch der Pfad. Diese Logik muss für Stakeholder sichtbar sein, die den zugrundeliegenden Code möglicherweise nicht verstehen.
🔄 Inklusive und parallele Gateways
Während exklusive Gateways einen Pfad wählen, können inklusive Gateways mehrere Pfade basierend auf Daten auswählen. Parallele Gateways teilen und vereinigen Abläufe unabhängig von Daten, arbeiten aber oft mit Datensätzen, die von vorherigen Aufgaben erstellt wurden.
- Inklusiver Gateway: Aktiviert Pfade, bei denen die Datenbedingungen als wahr bewertet werden.
- Paralleler Gateway: Aktiviert alle Pfade gleichzeitig; die Datenflüsse sind synchronisiert.
Bei der Visualisierung von Daten in diesen Szenarien stellen Sie sicher, dass die für jeden parallelen Zweig erforderlichen Daten eindeutig definiert sind. Wenn Zweig A die „Kunden-ID“ und Zweig B die „Bestell-ID“ benötigt, sollten beide Eingaben vor der parallelen Aufspaltung sichtbar sein.
💬 Nachrichtenflüsse im Vergleich zu Datenflüssen
Ein häufiger Verwirrungspunkt in BPMN ist der Unterschied zwischen Ablaufflüssen, Nachrichtenflüssen und Datenzuordnungen. Das Verständnis dieses Unterschieds ist entscheidend für eine korrekte Visualisierung.
| Flussart | Umfang | Funktion | Visuelle Darstellung |
|---|---|---|---|
| Ablauffluss | Innerhalb eines Pools | Steuerung der Aufgabenreihenfolge | Vollständiger Pfeil |
| Nachrichtenfluss | Zwischen Pools/Teilnehmern | Austausch von Nachrichten | Punktiertes Pfeil |
| Datenassoziation | Innerhalb eines Pools | Verknüpft Daten mit Aufgaben | Punktierte Linie (richtungsunabhängig) |
Nachrichtenflüsse tragen die Daten selbst über Grenzen hinweg. Wenn ein Kunde eine Bestellung sendet, trägt der Nachrichtenfluss die Bestelldaten. Ablaufflüsse tragen Steuerung, keine Daten. Datenassoziationen verknüpfen abstrakte Datenobjekte mit den Aufgaben, die sie verarbeiten.
Bei der Modellierung externer Interaktionen verwenden Sie Nachrichtenflüsse, um anzuzeigen, dass Daten die Prozessgrenze verlassen. Verwenden Sie Datenassoziationen, um anzuzeigen, dass eine Aufgabe aus einer lokalen Datenbank liest. Die Verwechslung dieser Elemente kann Entwickler verwirren, die die Integrationspunkte erstellen.
🛡️ Best Practices für die Datenvisualisierung
Um hochwertige Diagramme zu gewährleisten, sollten diese etablierten Praktiken befolgt werden. Konsistenz verringert die kognitive Belastung für alle, die das Modell überprüfen.
- Konsistente Benennung:Verwenden Sie immer denselben Namen für ein Datenobjekt über das gesamte Diagramm hinweg. Wenn es in Aufgabe A als „Rechnung“ bezeichnet wird, nennen Sie es in Aufgabe B nicht „Rechnung“.
- Minimale Verwirrung:Hängen Sie nicht jedes einzelne Feld an eine Aufgabe. Zeigen Sie nur Daten, die für das Verständnis des Prozesses entscheidend sind.
- Logische Gruppierung:Ordnen Sie verwandte Datenobjekte zusammen. Wenn eine Aufgabe „Versandadresse“ und „Rechnungsadresse“ beinhaltet, halten Sie sie visuell nahe beieinander.
- Versionskontrolle:Wenn sich die Datenstruktur ändert, aktualisieren Sie das Diagramm. Veraltete Datenmodelle führen zu fehlgeschlagenen Implementierungen.
- Trennung von Eingabe/Ausgabe:Unterscheiden Sie deutlich zwischen dem, was gelesen wird (Eingabe), und dem, was geschrieben wird (Ausgabe). Dies hilft dabei, schreibgeschützte Aufgaben von schreibintensiven Aufgaben zu unterscheiden.
🚧 Häufige Fehler, die vermieden werden sollten
Selbst erfahrene Modelleure machen Fehler, wenn sie Daten darstellen. Die Erkennung dieser häufigen Fehler hilft, Ihre Diagramme zu verfeinern.
🕵️ Fehlende Datenassoziationen
Ein häufiges Problem ist die Annahme, dass Daten existieren, ohne sie darzustellen. Wenn eine Aufgabe eine Summe berechnet, woher kommt dann der Preis? Wenn das Datenobjekt im Diagramm fehlt, ist die Prozesslogik unvollständig.
🔁 Zirkuläre Datenabhängigkeiten
Stellen Sie sicher, dass die Datenflüsse logisch sind. Eine Aufgabe sollte sich nicht auf Daten stützen, die von einer zukünftigen Aufgabe in derselben Ablauffolge erzeugt werden. Dies erzeugt einen logischen Widerspruch, der nicht ausgeführt werden kann.
🧩 Überbestimmung
Modellieren Sie nicht jedes einzelne Datenbankfeld. Konzentrieren Sie sich auf die geschäftlich relevanten Daten. Wenn eine Aufgabe eine „Bestellung“ verarbeitet, müssen Sie nicht jedes interne ID-Feld auflisten, es sei denn, es beeinflusst den Ablauf.
🔗 Verwechslung von Nachrichten- und Ablaufflüssen
Verwenden Sie niemals einen Nachrichtenfluss, um die Steuerung innerhalb eines einzelnen Pools darzustellen. Nachrichtenflüsse sind ausschließlich für die Kommunikation zwischen Teilnehmern vorgesehen. Ihre falsche Verwendung verletzt die semantischen Regeln der Notation.
📋 Detaillierter Vergleich von Datenangaben
Die folgende Tabelle erläutert die spezifischen Attribute, die in den Daten-Eingabe- und -Ausgabespezifikationen innerhalb einer Aufgabenbeschreibung enthalten sind. Das Verständnis dieser Attribute ermöglicht eine präzise Modellierung.
| Attribut | Daten-Eingabespezifikation | Daten-Ausgabespezifikation |
|---|---|---|
| Richtung | Lesen / Verbrauchen | Schreiben / Erzeugen |
| Zeitpunkt | Vor der Aufgabenausführung | Nach der Aufgabenausführung |
| Transformation | Kann eine Zuordnung von der Quelle erfordern | Kann eine Zuordnung zur Zielstelle erfordern |
| Abhängigkeit | Muss beim Start vorhanden sein | Ergebnis der Fertigstellung |
Durch das Verständnis dieser Unterschiede können Sie Diagramme erstellen, die den Datenlebenszyklus genau widerspiegeln. Diese Genauigkeit ist besonders wichtig, wenn ein Modell in ausführbaren Workflow-Code übersetzt wird.
🔄 Integration von Daten in ereignisgesteuerte Prozesse
Prozesse beginnen oft mit Ereignissen. Diese Ereignisse tragen häufig Daten mit sich. Zum Beispiel könnte ein „Nachrichten-Startereignis“ ausgelöst werden, wenn eine bestimmte XML-Nutzlast empfangen wird.
- Startereignisse: Kann Daten-Eingaben definieren. Der Prozess kann nicht starten, bis die Daten vorhanden sind.
- Zwischenereignisse: Kann Daten während der Ausführung erfassen, beispielsweise ein „Timer-Ereignis“, das nach einem bestimmten Datum startet.
- Ende-Ereignisse: Kann Daten-Ausgaben erzeugen, beispielsweise ein „Beenden-Ereignis“, das einen Endstatus-Protokoll speichert.
Die Visualisierung von Daten auf Ereignisebene stellt sicher, dass die Prozessgrenzen klar sind. Sie definiert genau, welche Informationen in das System eintreten und welche verlassen. Dies ist entscheidend für die API-Entwicklung und die Systemintegration.
📈 Messung der Effizienz des Datenflusses
Sobald Ihr Diagramm abgeschlossen ist, können Sie die visualisierten Daten nutzen, um die Prozesseffizienz zu analysieren. Suchen Sie nach Engpässen, an denen Daten feststecken oder dupliziert werden.
- Redundante Eingaben: Wenn mehrere Aufgaben dasselbe Datenobjekt lesen, überlegen Sie, ob dieses Datenobjekt gecacht oder direkt weitergeleitet werden könnte.
- Ausgabe-Latenz: Wenn eine Aufgabe Daten erzeugt, die vom nächsten Task nicht sofort genutzt werden, verbleibt die Daten untätig.
- Validierungsstellen: Stellen Sie sicher, dass die Datenvalidierung früh erfolgt. Wenn eine Aufgabe ungültige Daten erzeugt, werden nachfolgende Aufgaben fehlschlagen.
Durch die Analyse des Datenflusses können Sie den Prozess optimieren, bevor er überhaupt codiert wird. Dieser proaktive Ansatz spart erhebliche Entwicklungszeit und reduziert Laufzeitfehler.
🔍 Zusammenfassung der Umsetzungsschritte
Um diese Visualisierungstechniken in Ihren eigenen Modellierungsarbeiten umzusetzen, folgen Sie diesem strukturierten Ansatz.
- Identifizieren Sie Datenentitäten: Listen Sie alle Dokumente, Datensätze und Variablen auf, die im Prozess verwendet werden.
- Zuordnung zu Aufgaben: Weisen Sie Datenobjekte basierend auf ihrem Lebenszyklus spezifischen Aufgaben zu.
- Definieren Sie Spezifikationen: Kennzeichnen Sie Aufgaben als Eingabe, Ausgabe oder Eingabe/Ausgabe.
- Verbinden Sie Flüsse: Verwenden Sie Datenzuordnungen, um Objekte mit Aufgaben zu verknüpfen.
- Überprüfen Sie Bedingungen: Stellen Sie sicher, dass Gateways klare datenbasierte Bedingungen haben.
- Überprüfen Sie die Konsistenz: Stellen Sie sicher, dass Namen und Typen über das gesamte Diagramm hinweg übereinstimmen.
Diese systematische Methode stellt sicher, dass keine Datenanforderung übersehen wird. Sie verwandelt ein einfaches Flussdiagramm in ein umfassendes Spezifikationsdokument.
🤝 Zusammenarbeit und Kommunikation mit Stakeholdern
Denken Sie zuletzt daran, dass BPMN ein Kommunikationswerkzeug ist. Ziel ist es, sicherzustellen, dass Business Analysten, Entwickler und Manager den Prozess alle auf die gleiche Weise verstehen.
- Geschäftsstakeholder: Konzentrieren Sie sich auf die Datenobjekte (Dokumente), die sie erkennen.
- Entwickler: Konzentrieren Sie sich auf die Datenbeschreibungen und die Eingabe-/Ausgabemapping.
- Manager: Konzentrieren Sie sich auf die Datenspeicher und wo Informationen gespeichert werden.
Durch Anpassung des Datendetaillierungsgrads an die Zielgruppe stellen Sie sicher, dass das Diagramm für alle Beteiligten nützlich bleibt. Klare Visualisierung schließt die Lücke zwischen geschäftlichem Ziel und technischer Umsetzung.
Wenn Sie die Visualisierung von Daten-Eingaben und -Ausgaben priorisieren, erstellen Sie Modelle, die robust, genau und ausführbar sind. Der Prozess wird nicht nur zu einer Abfolge von Schritten, sondern zu einem kohärenten Informationsfluss. Diese Detailtiefe unterscheidet ein theoretisches Modell von einer praktischen Lösung.
Die Einführung dieser Praktiken erfordert Disziplin, aber das Ergebnis ist ein klareres Verständnis dafür, wie Ihr Unternehmen tatsächlich funktioniert. Jede Aufgabe, Entscheidung und Nachricht wird nachvollziehbar. Diese Nachvollziehbarkeit ist die Grundlage für moderne Prozessexzellenz.

