







In der modernen digitalen Landschaft ist Stabilität kein Luxus; sie ist eine grundlegende Voraussetzung. Organisationen stehen ständig vor einer Vielzahl von Störungen, die von Cyberbedrohungen und Infrastrukturausfällen über geopolitische Veränderungen bis hin zu Unterbrechungen der Lieferketten reichen.Resiliente Unternehmensarchitektur dient als Grundriss für die Bewältigung dieser Unsicherheiten. Es handelt sich um die Praxis der Gestaltung von Systemen, die nicht nur Schocks überstehen, sondern auch effektiv während und nach ungünstigen Ereignissen weiterarbeiten.
Dieser Leitfaden untersucht die zentralen Bausteine für die Schaffung einer Architektur, die die Geschäftstätigkeit aufrechterhalten kann. Wir gehen über einfache Redundanz hinaus, um strategische Ausrichtung, Risikomanagement und die Integration von Kontinuitätsplänen in das Fundament der technischen Gestaltung zu diskutieren. Ziel ist es, Systeme zu schaffen, die robust, anpassungsfähig und mit langfristigen organisatorischen Zielen ausgerichtet sind.
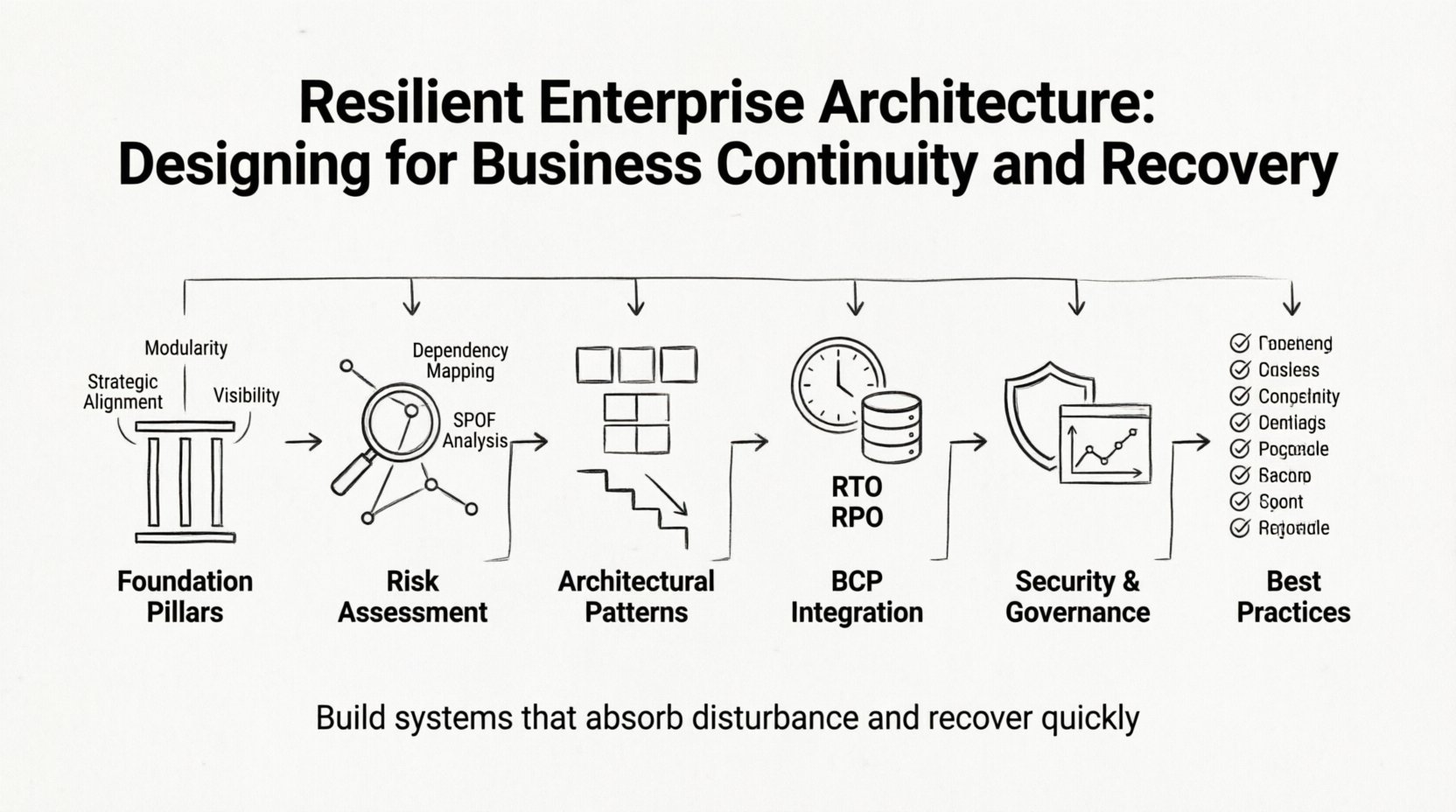
🧱 Die Grundlagen der resilienten Architektur
Resilienz unterscheidet sich von Zuverlässigkeit. Zuverlässigkeit stellt sicher, dass ein System funktioniert, wenn es soll. Resilienz stellt sicher, dass ein System auch dann funktioniert, wenn Dinge schief laufen. Es ist die Fähigkeit, Störungen zu absorbieren und schnell wiederherzustellen. Um dies zu erreichen, müssen Architekten die Organisation als ganzheitliches Ökosystem betrachten, anstatt als Sammlung isolierter Schubladen.
Wesentliche Säulen der Resilienz
Der Aufbau eines resilierten Rahmens erfordert Aufmerksamkeit für drei unterschiedliche, aber miteinander verbundene Bereiche:
- Strategische Ausrichtung:Technologische Entscheidungen müssen den Geschäftszielen dienen. Wenn das Unternehmen Vertrauen der Kunden priorisiert, muss die Architektur Datensicherheit und Verfügbarkeit priorisieren.
- Modularität:Systeme sollten in unabhängige Komponenten zerlegt werden. Dadurch wird verhindert, dass ein Ausfall in einem Modul sich über die gesamte Umgebung ausbreitet.
- Sichtbarkeit:Sie können nicht managen, was Sie nicht sehen können. Umfassende Überwachung und Protokollierung sind entscheidend, um Anomalien frühzeitig zu erkennen.
Verständnis der Risikobereitschaft
Jede Organisation hat eine unterschiedliche Risikobereitschaft. Einige Branchen erfordern nahezu keine Ausfallzeiten, während andere kurze Unterbrechungen tolerieren können. Die Definition dieserRisikobereitschaft ist der erste Schritt bei der architektonischen Gestaltung. Sie bestimmt den erforderlichen Investitionsaufwand für Redundanz, Backup-Strategien und Wiederherstellungs-Zielzeiten.
| Risikokategorie | Auswirkungsniveau | Architektonische Reaktion |
|---|---|---|
| Ausfall kritischer Infrastruktur | Hoch | Active-Active-Redundanz über Geografien hinweg |
| Datenschädigung | Mittel | Unveränderliche Backups mit Versionsverwaltung |
| Netzwerk-Latenz | Niedrig | Lastverteilungs- und Caching-Strategien |
| Menschliches Versagen | Mittel | Automatisierte Schutzmaßnahmen und Genehmigungsabläufe |
📊 Identifizieren und Bewerten von Schwachstellen
Bevor Verteidigungsmaßnahmen entworfen werden, muss man die Bedrohungen verstehen. Eine gründliche Bewertung zeigt auf, wo die Schwachstellen liegen. Dieser Prozess beinhaltet das Abbilden von Abhängigkeiten und das Verständnis, wie Daten durch die Organisation fließen.
Abhängigkeitsabbildung
Komplexe Systeme verlassen sich oft auf zugrundeliegende Dienste, die nicht sofort erkennbar sind. Ein Ausfall einer Drittanbieter-API, einer bestimmten Datenbankinstanz oder eines veralteten Integrationspunkts kann die Operationen stoppen. Architekten müssen detaillierte Karten dieser Beziehungen erstellen.
- Abhängigkeiten von oben (Upstream): Was speist das System? (z. B. Datenquellen, Authentifizierungsanbieter).
- Abhängigkeiten von unten (Downstream): Was hängt vom System ab? (z. B. Berichtswerkzeuge, Kunden-Apps).
- Horizontale Abhängigkeiten: Andere Dienste innerhalb derselben Umgebung, die Ressourcen teilen.
Die Analyse des Single Point of Failure (SPOF)
Ein Single Point of Failure ist eine Komponente, deren Ausfall den gesamten Prozess stoppt. Die Identifizierung von SPOFs ist eine entscheidende Aufgabe im Bereich der Resilienztechnik. Häufige Bereiche der Sorge sind:
- Zentralisierte Datenbanken ohne Replikation.
- Monolithische Anwendungen, die sich nicht unabhängig skalieren lassen.
- Manuelle Eingriffspunkte, die menschliche Fehler verursachen.
- Netzwerkengpässe, die die Bandbreite oder den Zugriff einschränken.
Sobald diese Punkte identifiziert wurden, müssen sie durch Redundanz, Automatisierung oder architektonische Neugestaltung behoben werden. Das Ziel ist es, das Risiko zu verteilen, sodass kein einzelner Ausfall einen katastrophalen Ausfall verursacht.
🛡️ Architektonische Muster für Kontinuität
Bestimmte Gestaltungsprinzipien haben sich als wirksam erwiesen, um die Verfügbarkeit während Störungen aufrechtzuerhalten. Diese Muster sollten bereits in der Planungsphase berücksichtigt werden, um sicherzustellen, dass die Architektur inhärent widerstandsfähig ist.
Entkopplung von Diensten
Enge Kopplung erzeugt Fragilität. Wenn Komponenten stark von den internen Implementierungsdetails der anderen abhängen, breiten sich Änderungen oder Ausfälle schnell aus. Die Entkopplung ermöglicht es Diensten, unabhängig zu funktionieren. Dies wird oft erreicht durch:
- Nachrichtenwarteschlangen: Asynchrone Kommunikation stellt sicher, dass Nachrichten in der Warteschlange warten, wenn ein Empfänger ausgefallen ist, anstatt verloren zu gehen.
- API-Gateways: Diese fungieren als Vermittler, die die Datenverkehrssteuerung, Rate Limiting und Authentifizierung übernehmen, ohne die Backend-Logik preiszugeben.
- Ereignisgesteuerte Architektur Systeme reagieren auf Zustandsänderungen anstatt auf Anfragen zu warten, was eine flexiblere Verarbeitung ermöglicht.
Redundanz und Failover
Redundanz bedeutet, dass Backups vorhanden sind. Failover ist der Prozess, automatisch auf diese Backups umzuschalten. Es gibt mehrere Strategien zur Umsetzung dieses Verfahrens:
- Aktiv-Passiv: Ein System verarbeitet den Datenverkehr, während ein anderes bereitsteht. Dies ist kosteneffizient, führt aber bei einem Wechsel zu einer gewissen Verzögerung.
- Aktiv-Aktiv: Mehrere Systeme verarbeiten den Datenverkehr gleichzeitig. Wenn eines ausfällt, übernehmen die anderen die Last. Dies bietet eine höhere Verfügbarkeit, erfordert aber mehr Ressourcen.
- Geo-Redundanz: Die Bereitstellung der Infrastruktur an verschiedenen physischen Standorten schützt vor regionalen Katastrophen wie Naturereignissen oder Stromnetzausfällen.
Geschmeidige Degradation
Wenn ein System nicht mit voller Kapazität arbeiten kann, sollte es sich geschmeidig herabstufen, anstatt abzustürzen. Das bedeutet, nicht essentielle Funktionen abzuschalten, um die Kernfunktionen zu erhalten. Zum Beispiel sollte der Benutzer auch dann Produkte durchsuchen können, wenn der Empfehlungsmotor ausfällt, auch wenn er keine personalisierten Vorschläge sieht.
📋 Integration der Business Continuity Planning (BCP)
Die Business Continuity Planning wird oft als separates Dokument behandelt, muss aber in die Architektur integriert werden. Technische Steuerungen sollten die in der BCP definierten Geschäftsregeln durchsetzen.
Definition von RTO und RPO
Zwei entscheidende Metriken leiten die Kontinuitätsmaßnahmen an:
- Recovery Time Objective (RTO): Die maximal akzeptable Ausfallzeit. Wie lange kann das Unternehmen ohne dieses System überleben?
- Recovery Point Objective (RPO): Die maximal akzeptable Datenverlustmenge. Wie viel Daten dürfen verloren gehen, bevor dies die Abläufe beeinträchtigt?
| Systemkritikalität | Ziel-RTO | Ziel-RPO | Strategie |
|---|---|---|---|
| Kundenorientierte Transaktion | < 5 Minuten | < 1 Minute | Echtzeit-Replikation, Aktiv-Aktiv |
| Interne Berichterstattung | < 24 Stunden | < 24 Stunden | Externe Sicherung, Geplante Wiederherstellung |
| Entwicklungsumgebung | < 1 Woche | < 1 Woche | Wiederherstellung von Momentaufnahmen, Manuelle Intervention |
Automatisierung der Wiederherstellung
Manuelle Wiederherstellungsprozesse sind langsam und fehleranfällig. In einer Krise sind die Stresslevel hoch, und die Verfahren müssen schnell ausgeführt werden. Die Automatisierung der Wiederherstellungsschritte gewährleistet Konsistenz und Geschwindigkeit. Dazu gehören:
- Automatischer Failover, ausgelöst durch Gesundheitsprüfungen.
- Skriptgesteuerte Bereitstellung neuer Ressourcen.
- Konfigurationsmanagement, um sicherzustellen, dass Umgebungen identisch sind.
🔄 Wiederherstellungsstrategien und Umsetzung
Ein Plan zu haben, reicht nicht aus. Die Fähigkeit, diesen Plan umzusetzen, definiert die Resilienz. Wiederherstellungsstrategien müssen regelmäßig getestet werden, um sicherzustellen, dass sie wie vorgesehen funktionieren.
Testprotokolle
Regelmäßige Tests bestätigen die Fähigkeit der Architektur, Ausfällen standzuhalten. Verschiedene Testarten dienen unterschiedlichen Zwecken:
- Tabletop-Übungen:Teammitglieder besprechen Szenarien und gehen Reaktionen ohne technische Änderungen durch.
- Simulation:Simulieren eines Ausfalls in einer Nicht-Produktionsumgebung, um Prozesse zu überprüfen.
- Chaos Engineering:Gezielt Ausfälle in ein Produktionssystem einbringen, um dessen Reaktion zu beobachten und Schwachstellen zu identifizieren.
Kommunikationskanäle
Während eines Vorfalls ist der Informationsfluss entscheidend. Architekten müssen Systeme gestalten, die auch dann die Kommunikation unterstützen, wenn primäre Kanäle ausfallen. Dazu gehören:
- Out-of-band-Kommunikationsmittel (z. B. SMS, spezielle Warnkanäle).
- Vordefinierte Rollen und Verantwortlichkeiten bei Vorfällen.
- Statusseiten, die Transparenz für Stakeholder und Kunden bieten.
🔒 Sicherheit als Säule der Resilienz
Sicherheit und Resilienz sind untrennbar miteinander verbunden. Ein Cyberangriff ist eine Hauptursache für Störungen. Daher müssen Sicherheitsmaßnahmen so gestaltet werden, dass sie die Kontinuität unterstützen.
Zero-Trust-Architektur
Das traditionelle perimetrische Sicherheitsmodell ist für moderne Umgebungen nicht ausreichend. Zero Trust geht davon aus, dass Bedrohungen sowohl innerhalb als auch außerhalb des Netzwerks bestehen. Jeder Zugriffsversuch wird unabhängig vom Ursprung überprüft. Dadurch wird die Verbreitung von Malware oder unbefugtem Zugriff eingeschränkt.
- Identitätsprüfung: Mehrfaktor-Authentifizierung für alle Benutzer und Dienste.
- Minimale Berechtigungen: Benutzer und Dienste haben nur Zugriff auf die spezifischen Ressourcen, die sie benötigen.
- Mikro-Segmentierung: Aufteilung des Netzwerks in kleine Zonen, um Ausfälle zu begrenzen.
Datenschutz und Verschlüsselung
Der Schutz von Daten stellt sicher, dass selbst wenn Systeme kompromittiert werden, die Informationen sicher bleiben. Die Verschlüsselung sollte sowohl im Ruhezustand als auch im Transitschutz angewendet werden. Sicherungen müssen unveränderlich sein, was bedeutet, dass sie nicht verändert oder gelöscht werden können, und schützen so vor Ransomware, die Sicherungsdateien angreift.
📈 Governance und Lebenszyklus-Management
Resilienz ist kein einmaliger Projekt; es ist eine kontinuierliche Disziplin. Die Governance stellt sicher, dass Resilienzstandards beibehalten werden, während die Architektur sich weiterentwickelt.
Änderungsmanagement
Änderungen sind die häufigste Ursache für Ausfälle. Ein robustes Änderungsmanagement-Verfahren prüft jede Änderung auf mögliche Auswirkungen auf die Resilienz. Dazu gehören:
- Überprüfung von Abhängigkeiten vor der Bereitstellung.
- Sicherstellen, dass Rückgängigmachungspläne vorhanden sind.
- Validierung von Konfigurationsänderungen anhand von Sicherheitsbaselines.
Kontinuierliche Überwachung
Die Überwachung liefert die Daten, die zur Aufrechterhaltung des Gesundheitszustands benötigt werden. Sie geht über die Verfügbarkeitsprüfungen hinaus und umfasst Leistungsmetriken, Fehlerquoten und Sicherheitsereignisse. Wichtige Praktiken umfassen:
- Echtzeit-Warnungen: Sofortige Benachrichtigung der Teams, wenn Schwellenwerte überschritten werden.
- Log-Aggregation:Zentralisierung von Protokollen zur erleichterten Analyse während Vorfälle.
- Leistungs-Baselines:Verständnis des normalen Verhaltens, um Anomalien schnell zu erkennen.
🚀 Zukunftssicherung der Architektur
Die Landschaft ändert sich schnell. Neue Bedrohungen entstehen und Technologien entwickeln sich weiter. Eine resiliente Architektur muss flexibel genug sein, um sich anzupassen.
Anpassungsfähigkeit und Skalierbarkeit
Für Wachstum und Veränderung gestalten. Systeme sollten horizontal skalieren, um erhöhte Lasten zu bewältigen, ohne eine vollständige Neugestaltung zu erfordern. Dazu gehören die Nutzung von cloud-nativen Mustern, die es ermöglichen, Ressourcen dynamisch hinzuzufügen oder zu entfernen.
- Containerisierung:Paketiert Anwendungen mit ihren Abhängigkeiten und stellt Konsistenz über Umgebungen hinweg sicher.
- Orchestrierung:Verwaltet die Bereitstellung und Skalierung von Containern automatisch.
- Serverless Computing: Entfernt die Belastung der Serververwaltung und ermöglicht die Konzentration auf die Logik.
Wissensmanagement
Mitarbeiter verlassen Organisationen. Institutionelles Wissen muss erhalten bleiben. Die Dokumentation der Architektur, Wiederherstellungsverfahren und Entscheidungsgrundlagen stellt sicher, dass neue Teams das System aufrechterhalten und verbessern können, ohne sich auf traditionelles Wissen zu verlassen.
📌 Zusammenfassung der Best Practices
Zusammenfassend den Weg hin zu einer resistenten Unternehmensarchitektur betrachtet, sollten Sie die folgende Prüfliste berücksichtigen:
- ✅ Dokumentieren Sie alle Abhängigkeiten und identifizieren Sie Einzelpunkte des Versagens.
- ✅ Definieren Sie klare RTO- und RPO-Ziele basierend auf der Geschäftskritikalität.
- ✅ Implementieren Sie Redundanz- und Failover-Mechanismen, die dem Risiko angemessen sind.
- ✅ Automatisieren Sie Wiederherstellungsprozesse, um menschliche Fehler und Ausfallzeiten zu reduzieren.
- ✅ Integrieren Sie Sicherheitskontrollen direkt in die Gestaltung.
- ✅ Testen Sie Wiederherstellungspläne regelmäßig durch Simulationen und Übungen.
- ✅ Überwachen Sie Systeme kontinuierlich und melden Sie Anomalien.
- ✅ Dokumentieren Sie alle Prozesse und führen Sie Versionskontrolle durch.
Die Schaffung von Resilienz erfordert Investitionen, Zeit und Disziplin. Es geht nicht darum, jeden Ausfall zu verhindern, was unmöglich ist. Es geht vielmehr darum sicherzustellen, dass die Organisation auch bei Ausfällen weiterhin ihre Kunden und Stakeholder versorgen kann. Indem diese Prinzipien in das Herzstück der Unternehmensarchitektur eingebettet werden, können Führungskräfte sicherstellen, dass ihre Organisationen stabil, sicher und bereit für die Herausforderungen bleiben, die vor ihnen liegen.
Die Reise hin zu Resilienz ist kontinuierlich. Sobald sich die Umgebung ändert, muss auch die Architektur sich anpassen. Regelmäßige Überprüfungen, Aktualisierungen und Verbesserungen halten das System robust. Dieser proaktive Ansatz verwandelt die Architektur von einer statischen Bauplan in ein dynamisches Asset, das Geschäftswert und Stabilität schafft.

