







En el entorno digital moderno, la estabilidad no es un lujo; es una necesidad fundamental. Las organizaciones enfrentan un constante bombardeo de interrupciones, que van desde amenazas cibernéticas y fallos de infraestructura hasta cambios geopolíticos e interrupciones en las cadenas de suministro.Arquitectura Empresarial Resilientese erige como el plano maestro para navegar estas incertidumbres. Es la práctica de diseñar sistemas que no solo sobreviven a los impactos, sino que continúan operando de manera efectiva durante y después de eventos adversos.
Esta guía explora los componentes fundamentales para construir una arquitectura capaz de mantener las operaciones del negocio. Avanzaremos más allá de la redundancia básica para abordar la alineación estratégica, la gestión de riesgos y la integración de la planificación de continuidad en la misma esencia del diseño técnico. El objetivo es crear sistemas robustos, adaptables y alineados con los objetivos organizativos a largo plazo.
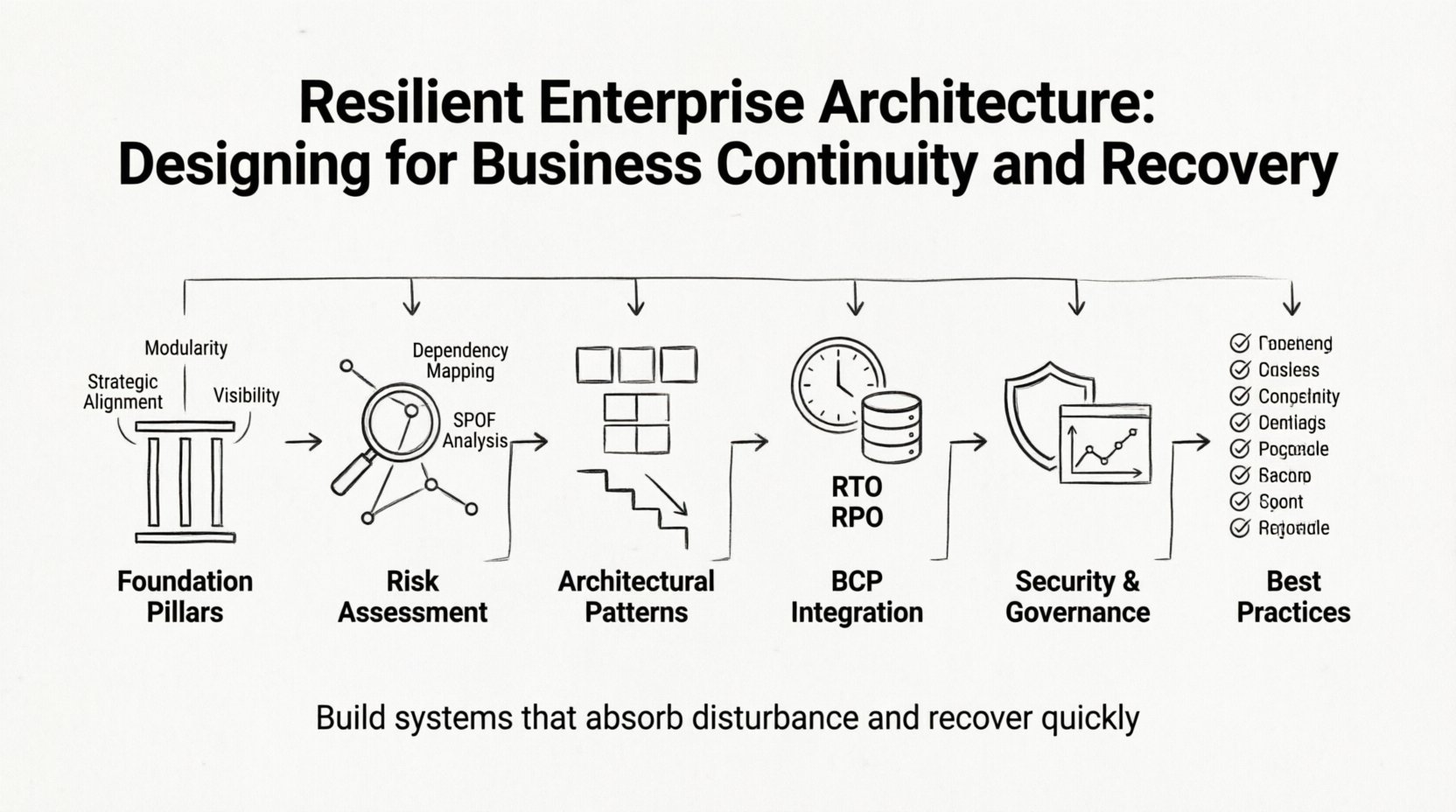
🧱 Las Fundaciones de la Arquitectura Resiliente
La resiliencia difiere de la confiabilidad. La confiabilidad garantiza que un sistema funcione cuando debe hacerlo. La resiliencia garantiza que un sistema funcione incluso cuando las cosas salen mal. Es la capacidad de absorber perturbaciones y recuperarse rápidamente. Para lograr esto, los arquitectos deben ver a la organización como un ecosistema holístico, y no como una colección de silos aislados.
Pilares Fundamentales de la Resiliencia
Construir un marco resiliente requiere atención a tres áreas distintas pero interconectadas:
- Alineación Estratégica:Las decisiones tecnológicas deben respaldar los objetivos del negocio. Si el negocio prioriza la confianza del cliente, la arquitectura debe priorizar la seguridad y disponibilidad de los datos.
- Modularidad:Los sistemas deben dividirse en componentes independientes. Esto evita que un fallo en un módulo se propague por todo el entorno.
- Visibilidad:No puedes gestionar lo que no puedes ver. La supervisión y el registro exhaustivos son esenciales para detectar anomalías a tiempo.
Comprender la Disposición al Riesgo
Cada organización tiene una tolerancia diferente al riesgo. Algunos sectores requieren tiempos de inactividad casi nulos, mientras que otros pueden tolerar interrupciones breves. Definir estadisposición al riesgoes el primer paso en el diseño arquitectónico. Determina la inversión necesaria para la redundancia, las estrategias de copia de seguridad y los objetivos de tiempo de recuperación.
| Categoría de Riesgo | Nivel de Impacto | Respuesta Arquitectónica |
|---|---|---|
| Fallo en Infraestructura Crítica | Alto | Redundancia Active-Active a través de geografías |
| Corrupción de Datos | Medio | Copias de seguridad inmutables con versionado |
| Latencia de Red | Bajo | Estrategias de equilibrio de carga y almacenamiento en caché |
| Error humano | Medio | Protectoras automatizadas y flujos de aprobación |
📊 Identificación y evaluación de vulnerabilidades
Antes de diseñar defensas, uno debe comprender las amenazas. Una evaluación exhaustiva revela dónde se encuentran los puntos débiles. Este proceso implica mapear dependencias y comprender cómo fluye la información a través de la organización.
Mapeo de dependencias
Los sistemas complejos a menudo dependen de servicios subyacentes que no son inmediatamente evidentes. Una falla en una API de terceros, una instancia específica de base de datos o un punto de integración heredado puede detener las operaciones. Los arquitectos deben crear mapas detallados de estas relaciones.
- Dependencias de entrada: ¿Qué alimenta al sistema? (por ejemplo, fuentes de datos, proveedores de autenticación).
- Dependencias de salida: ¿Qué depende del sistema? (por ejemplo, herramientas de informes, aplicaciones para clientes).
- Dependencias horizontales: Otros servicios dentro del mismo entorno que comparten recursos.
Análisis del punto único de falla (SPOF)
Un punto único de falla es un componente cuya falla detiene todo el proceso. Identificar los SPOF es un ejercicio crítico en la ingeniería de resiliencia. Las áreas comunes de preocupación incluyen:
- Bases de datos centralizadas sin replicación.
- Aplicaciones monolíticas que no pueden escalar de forma independiente.
- Puntos de intervención manual que introducen errores humanos.
- Puntos de cuello de botella de red que limitan el ancho de banda o el acceso.
Una vez identificados, estos puntos deben abordarse mediante redundancia, automatización o reingeniería arquitectónica. El objetivo es distribuir el riesgo para que ninguna falla individual provoque una interrupción catastrófica.
🛡️ Patrones arquitectónicos para la continuidad
Ciertos patrones de diseño se han demostrado efectivos para mantener la disponibilidad durante interrupciones. Estos patrones deben considerarse durante la fase de planificación para asegurar que la arquitectura sea inherentemente resiliente.
Desacoplamiento de servicios
El acoplamiento estrecho genera fragilidad. Cuando los componentes dependen en gran medida de los detalles internos de implementación de otros, los cambios o fallas se propagan rápidamente. El desacoplamiento permite que los servicios funcionen de forma independiente. Esto generalmente se logra mediante:
- Colas de mensajes: La comunicación asíncrona garantiza que si un consumidor está fuera de línea, los mensajes esperan en la cola en lugar de perderse.
- Pasarelas de API: Actúan como intermediarios, gestionando el enrutamiento del tráfico, el control de tasa y la autenticación sin exponer la lógica del backend.
- Arquitectura basada en eventosLos sistemas reaccionan a los cambios de estado en lugar de esperar solicitudes, lo que permite un procesamiento más flexible.
Redundancia y conmutación por fallo
La redundancia significa tener copias de seguridad. La conmutación por fallo es el proceso de cambiar automáticamente a esas copias de seguridad. Existen varias estrategias para implementar esto:
- Activo-Pasivo:Un sistema maneja el tráfico mientras otro permanece en espera. Esto es rentable, pero introduce cierta demora durante el cambio.
- Activo-Activo:Varios sistemas manejan el tráfico simultáneamente. Si uno falla, los demás absorben la carga. Esto ofrece una mayor disponibilidad, pero requiere más recursos.
- Geo-redundancia:Desplegar la infraestructura en ubicaciones físicas diferentes protege contra desastres regionales como eventos naturales o fallas en la red eléctrica.
Degradación gradual
Cuando un sistema no puede funcionar a su capacidad máxima, debería degradarse de forma gradual en lugar de fallar por completo. Esto significa desactivar las funciones no esenciales para preservar la funcionalidad principal. Por ejemplo, si el motor de recomendaciones falla, el usuario aún debería poder navegar por productos, aunque no vea sugerencias personalizadas.
📋 Integración de la planificación de continuidad del negocio (BCP)
La planificación de continuidad del negocio a menudo se trata como un documento separado, pero debe integrarse en la arquitectura. Los controles técnicos deben hacer cumplir las reglas del negocio definidas en la BCP.
Definición de RTO y RPO
Dos métricas clave guían los esfuerzos de continuidad:
- Objetivo de tiempo de recuperación (RTO):El tiempo máximo aceptable de inactividad. ¿Cuánto tiempo puede sobrevivir el negocio sin este sistema?
- Objetivo de punto de recuperación (RPO):La pérdida máxima aceptable de datos. ¿Cuántos datos pueden perderse antes de que afecten las operaciones?
| Criticidad del sistema | RTO objetivo | RPO objetivo | Estrategia |
|---|---|---|---|
| Transacción con el cliente | < 5 minutos | < 1 minuto | Replicación en tiempo real, Activo-Activo |
| Informes internos | < 24 horas | < 24 horas | Copia de seguridad remota, restauración programada |
| Entorno de desarrollo | < 1 semana | < 1 semana | Restauración de instantánea, intervención manual |
Automatización de la recuperación
Los procesos de recuperación manual son lentos y propensos a errores. En una crisis, los niveles de estrés son altos, y los procedimientos deben ejecutarse rápidamente. Automatizar los pasos de recuperación garantiza consistencia y velocidad. Esto incluye:
- Activación automática del failover basada en comprobaciones de estado.
- Provisionamiento automatizado de nuevos recursos.
- Gestión de configuración para garantizar que los entornos sean idénticos.
🔄 Estrategias y ejecución de recuperación
Tener un plan no es suficiente. La capacidad de ejecutar ese plan es lo que define la resiliencia. Las estrategias de recuperación deben probarse regularmente para asegurarse de que funcionen según lo previsto.
Protocolos de prueba
Las pruebas regulares validan la capacidad de la arquitectura para resistir fallos. Tipos diferentes de pruebas cumplen propósitos distintos:
- Ejercicios en mesa: Los miembros del equipo discuten escenarios y recorren las respuestas sin realizar cambios técnicos.
- Simulación: Simular un fallo en un entorno no productivo para verificar los procesos.
- Ingeniería de caos: Inyectar intencionalmente fallos en un sistema productivo para observar cómo reacciona y detectar debilidades.
Canalizaciones de comunicación
Durante un incidente, el flujo de información es crítico. Los arquitectos deben diseñar sistemas que permitan la comunicación incluso cuando los canales principales fallen. Esto incluye:
- Herramientas de comunicación fuera de banda (por ejemplo, SMS, canales de alerta dedicados).
- Roles y responsabilidades de incidente predefinidos.
- Páginas de estado que ofrecen transparencia a los interesados y clientes.
🔒 Seguridad como pilar de la resiliencia
La seguridad y la resiliencia son inseparables. Un ataque cibernético es una causa principal de interrupción. Por lo tanto, los controles de seguridad deben diseñarse para apoyar la continuidad.
Arquitectura de Confianza Cero
El modelo tradicional de seguridad basado en perímetro es insuficiente para los entornos modernos. La confianza cero asume que las amenazas existen tanto dentro como fuera de la red. Cada solicitud de acceso se verifica, independientemente de su origen. Esto limita la propagación de malware o el acceso no autorizado.
- Verificación de identidad: Autenticación multifactor para todos los usuarios y servicios.
- Menor privilegio:Los usuarios y servicios solo tienen acceso a los recursos específicos que necesitan.
- Microsegmentación:Dividir la red en pequeñas zonas para contener las brechas.
Protección de datos y cifrado
Proteger los datos garantiza que, incluso si los sistemas se ven comprometidos, la información permanezca segura. El cifrado debe aplicarse en reposo y en tránsito. Las copias de seguridad deben ser inmutables, lo que significa que no pueden alterarse ni eliminarse, protegiéndose así contra el ransomware que ataca los archivos de copia de seguridad.
📈 Gobernanza y gestión del ciclo de vida
La resiliencia no es un proyecto único; es una disciplina continua. La gobernanza garantiza que se mantengan los estándares de resiliencia a medida que evoluciona la arquitectura.
Gestión de cambios
Los cambios son la causa más común de interrupciones. Un proceso sólido de gestión de cambios revisa cada modificación en busca de posibles impactos en la resiliencia. Esto incluye:
- Revisar las dependencias antes de la implementación.
- Garantizar que existan planes de reintegración.
- Validar los cambios de configuración frente a las bases de seguridad.
Monitoreo continuo
El monitoreo proporciona los datos necesarios para mantener la salud. Va más allá de las comprobaciones de disponibilidad para incluir métricas de rendimiento, tasas de errores y eventos de seguridad. Las prácticas clave incluyen:
- Alertas en tiempo real:Notificando a los equipos de inmediato cuando se superen los umbrales.
- Agregación de registros:Centralizar los registros para facilitar su análisis durante los incidentes.
- Límites de rendimiento:Comprender el comportamiento normal para detectar anomalías de forma rápida.
🚀 Futuro de la arquitectura
El panorama cambia rápidamente. Aparecen nuevas amenazas y las tecnologías evolucionan. Una arquitectura resiliente debe ser lo suficientemente flexible como para adaptarse.
Adaptabilidad y escalabilidad
Diseñar para el crecimiento y el cambio. Los sistemas deben escalar horizontalmente para manejar una carga aumentada sin necesidad de un rediseño completo. Esto implica el uso de patrones nativos de nube que permiten agregar o eliminar recursos dinámicamente.
- Contenedorización:Empaqueta las aplicaciones con sus dependencias, garantizando consistencia entre los entornos.
- Orquestación:Gestiona automáticamente el despliegue y escalado de contenedores.
- Computación sin servidor: Elimina la carga de gestión de servidores, permitiendo centrarse en la lógica.
Gestión del conocimiento
La gente abandona las organizaciones. El conocimiento institucional debe preservarse. La documentación de la arquitectura, los procedimientos de recuperación y las razones detrás de las decisiones garantizan que los nuevos equipos puedan mantener y mejorar el sistema sin depender del conocimiento tribal.
📌 Resumen de las mejores prácticas
Para resumir el camino hacia una arquitectura empresarial resiliente, considere la siguiente lista de verificación:
- ✅ Mapa todas las dependencias e identifica puntos únicos de fallo.
- ✅ Establece objetivos claros de RTO y RPO basados en la criticidad del negocio.
- ✅ Implementa mecanismos de redundancia y conmutación por fallos adecuados al riesgo.
- ✅ Automatiza los procesos de recuperación para reducir errores humanos y tiempos de inactividad.
- ✅ Integra los controles de seguridad directamente en el diseño.
- ✅ Prueba los planes de recuperación con regularidad mediante simulaciones y ejercicios.
- ✅ Monitorea los sistemas de forma continua y alerta ante anomalías.
- ✅ Documenta todos los procesos y mantiene el control de versiones.
Construir resiliencia requiere inversión, tiempo y disciplina. No se trata de prevenir cada fallo, ya que eso es imposible. Se trata de garantizar que, cuando ocurran fallos, la organización pueda continuar sirviendo a sus clientes y partes interesadas. Al integrar estos principios en el núcleo de la Arquitectura Empresarial, los líderes pueden asegurar que sus organizaciones permanezcan estables, seguras y listas para enfrentar cualquier desafío que se presente.
El camino hacia la resiliencia es continuo. A medida que cambia el entorno, también debe cambiar la arquitectura. Revisiones, actualizaciones y mejoras regulares mantienen al sistema robusto. Este enfoque proactivo transforma la arquitectura de un plano estático en un activo dinámico que impulsa el valor empresarial y la estabilidad.

