











Geschäftsprozesse sind selten linear. In der realen Welt ist die Datenbasis unvollständig, Systeme fallen aus, und menschliche Urteile variieren. Beim Modellieren von Workflows mit der Business Process Model and Notation (BPMN) ist es eine Rezept für Produktionsausfälle, anzunehmen, dass alles immer gelingen wird. Die Behandlung von Ausnahmen und Fehlerpfade sind keine optionalen Funktionen, sondern grundlegende Bestandteile einer widerstandsfähigen Prozessarchitektur. Dieser Leitfaden erläutert, wie Sie die Fehlerverwaltung effektiv in Ihren Prozessmodellen strukturieren können.
🛑 Warum die Ausnahmebehandlung in BPMN wichtig ist
Ein Prozessmodell ohne definierte Fehlerpfade ist unvollständig. Es beschreibt den „glücklichen Pfad“ – die Situation, in der jeder Schritt perfekt gelingt. Doch die operative Realität ist viel komplexer. Wenn eine Aufgabe in einer Live-Umgebung fehlschlägt, benötigt der Workflow-Engine explizite Anweisungen, wie sie reagieren soll. Ohne klare Modellierung:
- Hängende Instanzen:Prozesse können unbegrenzt anhalten, warten auf eine Bedingung, die niemals erfüllt wird.
- Datenverlust:Kritische Informationen könnten verworfen werden, wenn der Ablauf abrupt beendet wird.
- Operative Blindstellen:Teams wissen möglicherweise nicht, welche Fehler kritisch sind und welche nur Warnungen darstellen.
- Manuelle Eingriffe:Benutzer könnten gezwungen sein, fehlgeschlagene Instanzen manuell neu zu starten, ohne einen strukturierten Wiederherstellungsplan.
Durch die explizite Modellierung von Ausnahmen verwandeln Sie ein zerbrechliches Skript in ein robustes System. Dieser Ansatz stellt sicher, dass das System genau weiß, was zu tun ist, wen es zu benachrichtigen hat und wie das Ergebnis protokolliert wird, wenn Dinge schief laufen.
🧩 Verständnis der BPMN-Fehlerereignistypen
BPMN 2.0 bietet spezifische Elemente zur Darstellung von Fehlern. Das Verständnis der Unterschiede zwischen diesen Elementen ist entscheidend für eine genaue Modellierung. Fehler sind nicht einfach „Stopp“-Anweisungen; sie sind Ereignisse, die spezifische Verhaltensweisen auslösen.
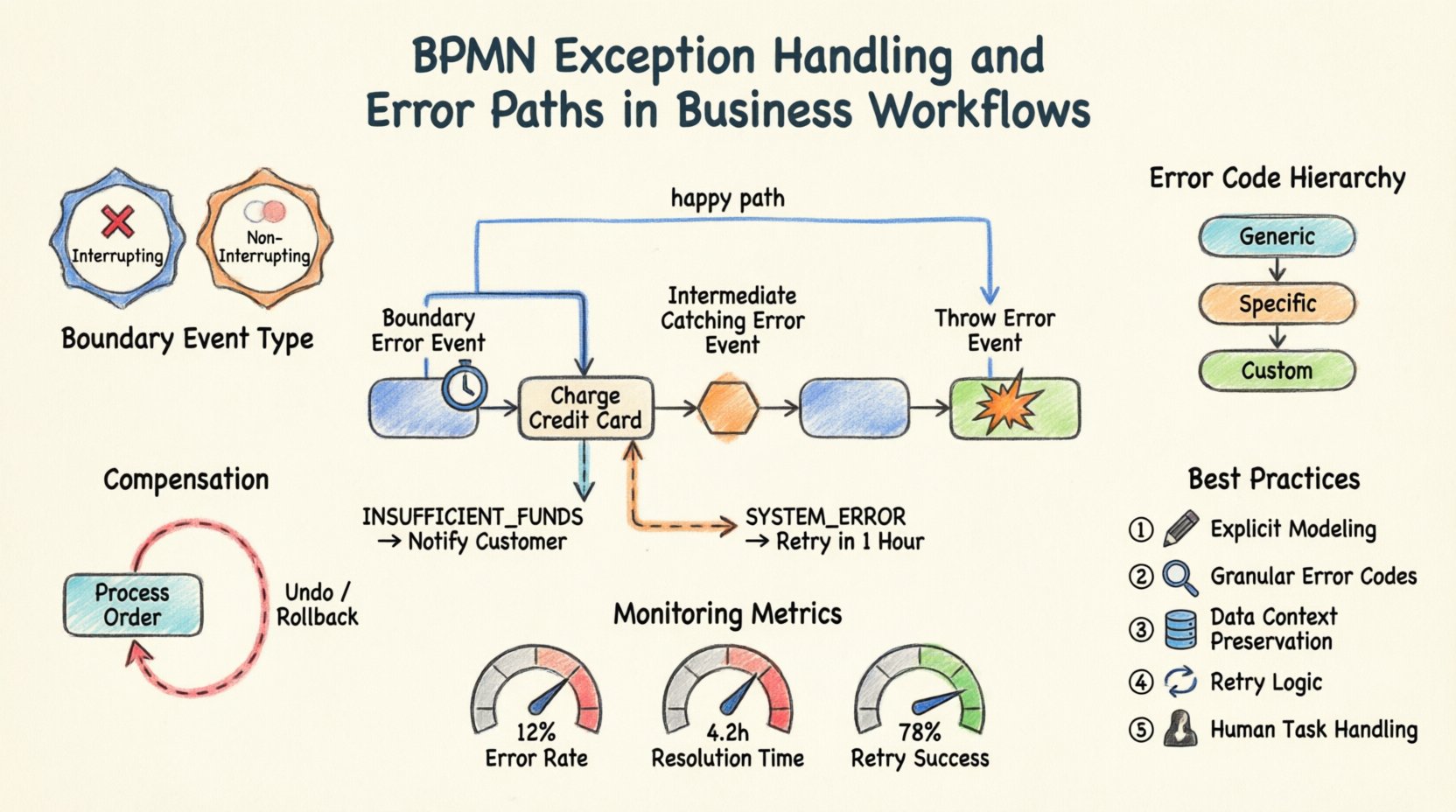
1. Grenz-Fehlerereignisse ⏱️
Ein Grenz-Fehlerereignis ist an der Grenze einer Aktivität (Aufgabe oder Unterprozess) angebracht. Es stellt einen Fehler dar, der während der Ausführung dieser Aktivität auftritt.währendder Ausführung dieser Aktivität. Wenn die Aktivität einen Fehler auslöst, wird der Ablauf zum Grenz-Fehlerereignis umgeleitet, wodurch eine sofortige Behandlung möglich ist, ohne den Hauptablauf vorzeitig zu unterbrechen.
- Anwendungsfall:Eine Zahlungsaufgabe schlägt aufgrund eines Timeouts fehl. Das Grenz-Fehlerereignis erfasst dies und ermöglicht es Ihnen, die Zahlung erneut zu versuchen oder den Benutzer zu informieren.
- Verhalten:Die Hauptaktivität kann so konfiguriert werden, dass sie weiterläuft oder angehalten wird. Wenn sie weiterläuft, löst das Grenz-Fehlerereignis einen parallelen Pfad aus.
2. Zwischenzeitliche Fehler-Ereignisse, die Fehler erfassen 🛑
Diese Ereignisse befinden sich innerhalb des Ablaufs eines Prozesses und sind nicht an einer Aktivitätsgrenze angebracht. Sie erfassen einen Fehler, der von einer vorherigen Aktivität oder einem vorhergehenden Prozess ausgelöst wurde. Sie fungieren als Prüfpunkt im Ablauffluss.
- Anwendungsfall:Nach einer Reihe von Überprüfungs-Schritten erfasst ein zwischenzeitliches Fehlerereignis einen Überprüfungsfehler, bevor der Prozess in die Ausführungsphase übergeht.
- Verhalten:Der Prozess pausiert an diesem Ereignis, bis der Fehler behandelt wurde, und geht dann zum nächsten Schritt über.
3. Fehler auslösende Ereignisse 💥
Diese Ereignisse werden innerhalb einer Aktivität verwendet, um anzugeben, dass ein Fehler aufgetreten ist. Sie sind die Quelle der Ausnahme. Eine Aktivität kann eine spezifische Bedingung definieren, unter der sie einen Fehler auslöst, anstatt normal abzuschließen.
- Anwendungsfall: Eine Dienstintegrationsaufgabe erkennt einen 500-Internal-Server-Fehler und wirft einen spezifischen Fehler-Token.
- Verhalten: Es propagiert den Fehler bis zum nächsten Grenzfehlerereignis oder intermediären Fehlerfangereignis nach oben.
⚙️ Tiefenblick: Grenzfehlerereignisse
Grenzfehlerereignisse sind das häufigste Werkzeug zur Fehlerbehandlung in BPMN. Sie ermöglichen es Ihnen, den Hauptablauf sauber zu halten, während Sie Ausnahmen lokal verwalten.
Konfigurationsoptionen
Wenn Sie ein Grenzfehlerereignis einer Aufgabe anhängen, müssen Sie spezifische Verhaltensweisen definieren:
- Unterbrechend vs. Nicht-Unterbrechend:
- Unterbrechend: Die Hauptaufgabe wird sofort gestoppt. Es wird kein weiterer Arbeitsschritt auf der Aufgabe durchgeführt.
- Nicht-Unterbrechend: Die Aufgabe läuft im Hintergrund weiter. Der Fehlerbehandlungs-Pfad läuft parallel. Dies ist nützlich für Protokollierung oder Benachrichtigung, ohne die Arbeit zu stoppen.
- Fehlerdefinition: Sie müssen den Fehlercode angeben. Dadurch können verschiedene Grenzfehlerereignisse unterschiedliche Fehlerarten erfassen (z. B. „PAYMENT_TIMEOUT“ gegenüber „PAYMENT_DECLINED“).
Praktisches Szenario: Die Zahlungsabwicklung
Betrachten Sie einen Prozess zur Auftragsbearbeitung. Eine Aufgabe namens „Kreditkarte belasten“ ist zentral für diesen Ablauf.
- Hauptpfad: Wenn erfolgreich, geht der Prozess zu „Auftrag versenden“.
- Fehlerpfad: Hängen Sie ein Grenzfehlerereignis an „Kreditkarte belasten“ an.
- Logik: Wenn der Fehlercode „INSUFFICIENT_FUNDS“ ist, geht der Ablauf zu „Kunde benachrichtigen“.
- Logik: Wenn der Fehlercode „SYSTEM_ERROR“ ist, geht der Ablauf zu „In einer Stunde erneut versuchen“.
Diese Struktur verhindert, dass der Prozess abstürzt. Sie leitet den Benutzer basierend auf der spezifischen Art des Fehlers an den richtigen Behebungs-Pfad weiter.
🔄 Intermediäre Fehlerereignisse und Propagation
Nicht alle Fehler werden sofort an der Quelle erfasst. Manchmal müssen Fehler nach oben in die Prozesshierarchie propagiert werden. Intermediäre Fehlerfangereignisse erleichtern dies.
Fehlerbehandlung in Unterprozessen
Beim Verwenden eines eingebetteten Unterprozesses können Fehler, die innerhalb des Unterprozesses auftreten, auf zwei Arten behandelt werden:
- Interne Behandlung: Fehler werden innerhalb des Unterprozesses mithilfe von Grenzereignissen erfasst. Der Unterprozess wird normal (oder mit einem bestimmten Abschlusszustand) abgeschlossen, ohne einen Fehler an den übergeordneten Prozess zu werfen.
- Externe Weiterleitung: Fehler werden aus dem Unterprozess herausgeworfen. Der übergeordnete Prozess erfasst sie mithilfe eines Grenzereignisses am Unterprozess selbst oder eines Zwischenfehlerereignisses im Hauptfluss.
Fehlercodes und Hierarchie
Um die Weiterleitung effektiv zu steuern, definieren Sie eine Hierarchie von Fehlercodes:
- Generische Fehler:Allgemeine Ereignisse für unerwartete Systemausfälle.
- Spezifische Fehler:Ereignisse für bekannte Geschäftslogik-Fehler (z. B. „Ungültige Adresse“).
- Benutzerdefinierte Codes:Spezifische Codes, die von Ihrer Integrations-Schicht definiert werden.
Die Verwendung spezifischer Codes stellt sicher, dass der richtige Handler ausgelöst wird. Ein generischer Allgemeinfall sollte als letzte Möglichkeit, nicht als erste, verwendet werden.
💸 Kompensation und Rückgängigmachungsstrategien
Manchmal wird ein Fehler entdeckt, nachdem bereits eine Reihe von Aktionen abgeschlossen wurde. In solchen Fällen reicht es nicht aus, den Prozess einfach zu stoppen. Möglicherweise müssen Änderungen rückgängig gemacht werden. Hier kommen Kompensationsereignisse ins Spiel.
Was ist Kompensation?
Kompensation ist die Handlung, eine abgeschlossene Aktivität rückgängig zu machen. Sie unterscheidet sich von der Fehlerbehandlung, da sie sich mit den Folgen eines Erfolgs befasst, dem ein Fehler in einem nachfolgenden Schritt folgt.
- Anwendungsfall: Sie haben eine Flugbuchung erfolgreich abgeschlossen, aber die Hotelbuchung schlägt fehl. Die Flugbuchung muss storniert werden, um Gebühren zu vermeiden.
- Modellierung: Sie definieren eine Kompensationsaktivität, die mit der ursprünglichen Aktivität verknüpft ist.
Wann sollte Kompensation verwendet werden
Verwenden Sie Kompensationsereignisse, wenn:
- Der Prozess ist langlaufend.
- Externe Systeme können nicht leicht rückgängig gemacht werden.
- Die Datenintegrität muss über mehrere Schritte hinweg gewährleistet werden.
Ohne Kompensation hinterlässt Ihr Prozessmodell verwaiste Datensätze oder inkonsistente Zustände im System der Wahrheit.
📊 Vergleichsmatrix zur Fehlerbehandlung
Um die Unterschiede zwischen verschiedenen Mechanismen zur Fehlerbehandlung zu klären, ziehen Sie diese strukturierte Vergleichstabelle heran.
| Element | Ort | Auslöser | Primärer Anwendungsfall |
|---|---|---|---|
| Grenzfehlerereignis | An Aufgabe angehängt | Aufgabenausfall | Sofortige Wiederholung oder Benachrichtigung des Benutzers |
| Zwischenfehlerereignis | Innerhalb des Flows | Fehler im vorherigen Schritt | Fehler nach einer Folge von Aufgaben abfangen |
| Fehlerereignis auslösen | Innerhalb der Aufgabe | Logische Bedingung | Fehler an vorherige Handler signalisieren |
| Kompensationsereignis | Verknüpft mit abgeschlossener Aufgabe | Nachfolgender Ausfall | Vorherige Aktionen rückgängig machen (Rollback) |
🗂️ Verwaltung des Datenkontexts während Fehler
Wenn ein Fehler auftritt, ist der Datenzustand entscheidend. Nur zu wissen, dass ein Fehler aufgetreten ist, reicht oft nicht aus. Sie müssen wissen, warum und wasDaten haben ihn verursacht.
Fehlervariablen
BPMN-Engines ermöglichen es Ihnen, Variablen an Fehlerhandler weiterzuleiten. Stellen Sie sicher, dass Ihr Modell erfasst:
- Fehlercode: Ein standardisierter Bezeichner (z. B. „ERR_101“).
- Fehlermeldung: Eine lesbare Beschreibung für Protokolle.
- Kontextdaten: Relevante Geschäftsinformationen (z. B. Auftrags-ID, Kundename), um die Fehlersuche zu unterstützen.
Datenpersistenz
Stellen Sie sicher, dass die vor dem Fehler gesammelten Daten persistiert werden. Verlassen Sie sich nicht auf temporären Speicher. Wenn eine Prozessinstanz aufgrund eines Fehlers beendet wird, muss die nächste Instanz Zugriff auf denselben Datenkontext haben, um die Verarbeitung fortzusetzen.
🧪 Testen und Validieren von Fehlerpfaden
Das Modellieren von Fehlerpfaden ist nur die halbe Arbeit. Sie müssen sicherstellen, dass sie im Laufzeitumfeld korrekt funktionieren. Das Testen von Fehlerpfaden erfordert einen anderen Ansatz als das Testen der normalen Pfade.
Validierungs-Checkliste ✅
- Unerreichbare Logik: Stellen Sie sicher, dass Fehlerpfade keine Deadlocks oder unerreichbare Knoten erzeugen.
- Abdeckung: Stellen Sie sicher, dass jeder potenzielle Fehlerpunkt über einen entsprechenden Fehlerhandler verfügt.
- Zeitüberschreitungen: Testen Sie, was geschieht, wenn eine Aufgabe ihre Zeitgrenze überschreitet.
- Integrationsfehler: Simulieren Sie eine API-Ausfallzeit, um sicherzustellen, dass das Grenzereignis ausgelöst wird.
- Datenintegrität: Bestätigen Sie, dass nach einer Rücksetzung keine teilweise Daten verbleiben.
Simulationswerkzeuge
Verwenden Sie Prozess-Simulationswerkzeuge, um Fehler in den Ablauf einzuführen. Dadurch können Sie beobachten, wie der Prozess unter Belastung reagiert, ohne Produktionsdaten zu beeinflussen. Achten Sie auf:
- Unerwartete Prozessbeendigung.
- Falsche Fehlermeldungen werden protokolliert.
- Fehlende Benachrichtigung der richtigen Beteiligten.
🚧 Häufige Fehlerquellen, die vermieden werden sollten
Sogar erfahrene Modelleure machen Fehler beim Entwerfen der Fehlerbehandlung. Seien Sie sich dieser häufigen Fallen bewusst.
1. Ignorieren des „Normalpfads“
Vermeiden Sie es, den Hauptpfad mit Fehlerbehandlungslogik zu belasten. Halten Sie den Hauptpfad sauber. Verwenden Sie Grenzereignisse und Unterprozesse, um die Fehlerlogik zu isolieren. Dadurch wird das Modell leichter lesbar und wartbar.
2. Übermäßige Verwendung von Grenzereignissen
Die Anwendung eines Grenzereignisses auf jede einzelne Aufgabe kann das Diagramm unübersichtlich und verwirrend machen. Hängen Sie sie nur an Aufgaben an, bei denen ein Ausfall erhebliche Auswirkungen hat oder spezifische Behandlungslogik erfordert.
3. Schwammige Fehlermeldungen
Vermeiden Sie generische Fehlermeldungen wie „Etwas ist schiefgelaufen.“ Verwenden Sie spezifische Codes und Nachrichten, die Entwickler und Geschäftsanwender verstehen können. Dies unterstützt eine schnellere Behebung.
4. Fehlende Wiederholungslogik
Vorübergehende Fehler (wie Netzwerkstörungen) sollten erneut versucht werden. Modellieren Sie Wiederholungsmechanismen explizit mithilfe von Zeitern oder Schleifen. Lassen Sie einen vorübergehenden Fehler nicht zu einem dauerhaften Fehler werden.
5. Vergessen menschlicher Aufgaben
Menschliche Aufgaben können ebenfalls fehlschlagen. Ein Benutzer könnte eine Aufgabe ignorieren oder ungültige Daten eingeben. Definieren Sie, was geschieht, wenn eine menschliche Aufgabe aufgegeben oder abgelehnt wird. Dies erfordert oft einen anderen Fehlerpfad als Systemaufgaben.
🔍 Überwachung und Betriebsbereitschaft
Sobald der Prozess live ist, werden die Fehlerpfade Ihre erste Verteidigungslinie. Die Überwachung ist entscheidend, um sicherzustellen, dass diese Pfade wie vorgesehen funktionieren.
Wichtige Metriken
- Fehlerquote: Der Prozentsatz der Prozessinstanzen, die einen Fehlerpfad erreichen.
- Beseitigungszeit: Wie lange es dauert, sich von einem Fehler zu erholen.
- Erfolgsrate bei Wiederholungen: Wie oft automatische Wiederholungen das Problem lösen.
Benachrichtigungen
Konfigurieren Sie Benachrichtigungen für kritische Fehlerpfade. Wenn ein bestimmter Fehlercode stark ansteigt, deutet dies auf ein systemisches Problem hin, das sofortige Aufmerksamkeit erfordert. Behandeln Sie nicht alle Fehler gleich; priorisieren Sie jene, die Umsatz oder Compliance beeinträchtigen.
📝 Zusammenfassung der Best Practices
Um sicherzustellen, dass Ihre Geschäftsabläufe widerstandsfähig sind, halten Sie sich an diese Kernprinzipien:
- Explizites Modellieren: Nehmen Sie niemals an, dass ein Fehler vom Engine automatisch behandelt wird. Definieren Sie ihn im Diagramm.
- Fein granulare Behandlung: Verwenden Sie spezifische Fehlercodes, um den richtigen Handler zu erreichen.
- Datenaufmerksamkeit: Bewahren Sie Kontextdaten während eines Fehlers für Audits und Debugging auf.
- Kompensation: Planen Sie die Rückgängigmachung von Aktionen, wenn nötig.
- Testen: Validieren Sie Fehlerpfade ebenso gründlich wie den Hauptablauf.
Durch die Investition von Zeit in die Modellierung von Ausnahmen bauen Sie Prozesse auf, die nicht nur effizient, sondern auch robust sind. Ein gut behandeltes Fehlerereignis ist oft besser als gar kein Fehler, da es Vertrauen und Klarheit im System bewahrt. Konzentrieren Sie sich auf Klarheit, Präzision und Betriebsbereitschaft in Ihren BPMN-Modellen.
🔗 Nächste Schritte zur Umsetzung
Beginnen Sie mit der Überprüfung Ihrer bestehenden Prozesse. Identifizieren Sie hochriskante Aufgaben, bei denen ein Ausfall kostspielig wäre. Modellieren Sie zunächst Grenzereignisse für diese Aufgaben. Erweitern Sie schrittweise auf Zwischenereignisse und Kompensationslogik. Dieser schrittweise Ansatz gewährleistet Stabilität, während die Resilienz verbessert wird.
Dokumentieren Sie Ihre Fehlerbehandlungsstrategie. Erstellen Sie eine Referenzanleitung für Entwickler und Analysten, die die Fehlercodes und erwarteten Verhaltensweisen erklärt. Diese Dokumentation wird im Laufe der Zeit zu einem entscheidenden Vermögen für die Pflege des Prozesses.
Denken Sie daran, das Ziel ist nicht, Fehler zu eliminieren, sondern sie effektiv zu managen. Wenn Sie Fehlerpfade klar modellieren, befähigen Sie das System, sich reibungslos zu erholen und das Geschäft weiterlaufen zu lassen.

