







Na paisagem digital moderna, a estabilidade não é um luxo; é uma exigência fundamental. As organizações enfrentam um constante bombardeio de interrupções, variando de ameaças cibernéticas e falhas na infraestrutura até mudanças geopolíticas e interrupções na cadeia de suprimentos.Arquitetura Empresarial Resilienteserve como o plano mestre para navegar essas incertezas. É a prática de projetar sistemas que não apenas sobrevivem a choques, mas continuam operando de forma eficaz durante e após eventos adversos.
Este guia explora os componentes principais para construir uma arquitetura capaz de sustentar as operações do negócio. Avançaremos além da redundância básica para discutir alinhamento estratégico, gestão de riscos e a integração do planejamento de continuidade na própria essência do design técnico. O objetivo é criar sistemas robustos, adaptáveis e alinhados com os objetivos organizacionais de longo prazo.
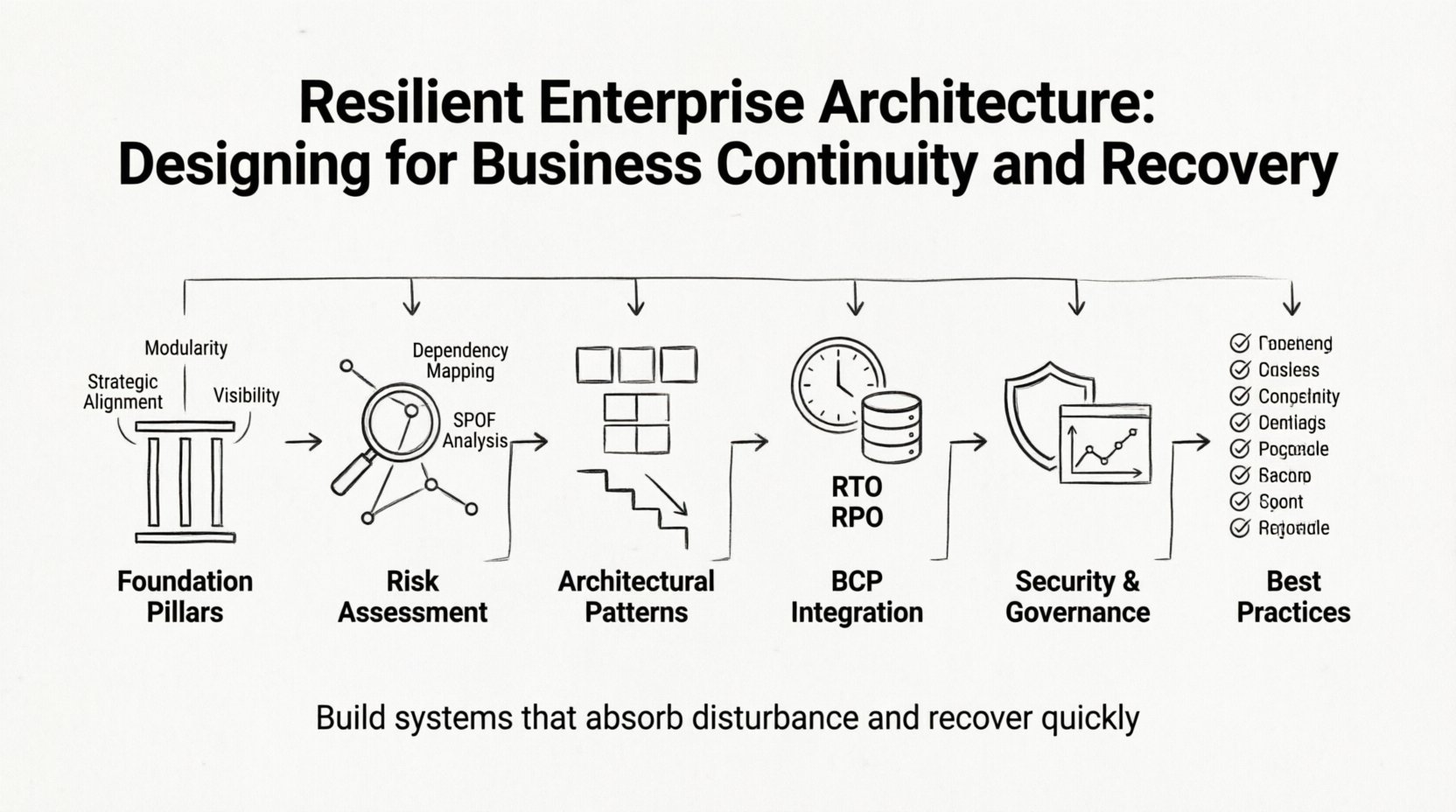
🧱 Os Fundamentos da Arquitetura Resiliente
A resiliência difere da confiabilidade. A confiabilidade garante que um sistema funcione quando deveria. A resiliência garante que um sistema funcione mesmo quando as coisas dão errado. É a capacidade de absorver perturbações e se recuperar rapidamente. Para alcançar isso, os arquitetos devem olhar para a organização como um ecossistema holístico, e não como uma coleção de silos isolados.
Pilares Centrais da Resiliência
Construir um framework resiliente exige atenção a três áreas distintas, mas interconectadas:
- Alinhamento Estratégico:As decisões tecnológicas devem apoiar os objetivos do negócio. Se o negócio prioriza a confiança do cliente, a arquitetura deve priorizar a segurança e a disponibilidade dos dados.
- Modularidade:Os sistemas devem ser divididos em componentes independentes. Isso evita que uma falha em um módulo se propague por todo o ambiente.
- Visibilidade:Você não pode gerenciar o que não consegue ver. Monitoramento e registro abrangentes são essenciais para detectar anomalias precocemente.
Compreendendo a Aparência de Risco
Toda organização tem uma tolerância diferente ao risco. Algumas áreas exigem tempo de inatividade próximo de zero, enquanto outras podem tolerar interrupções breves. Definir esse apetite por riscoé o primeiro passo no design arquitetônico. Ele determina o investimento necessário para redundância, estratégias de backup e objetivos de tempo de recuperação.
| Categoria de Risco | Nível de Impacto | Resposta Arquitetônica |
|---|---|---|
| Falha em Infraestrutura Crítica | Alto | Redundância Active-Active em diferentes geografias |
| Corrupção de Dados | Médio | Backup imutável com versionamento |
| Latência de Rede | Baixo | Estratégias de balanceamento de carga e cache |
| Erro Humano | Médio | Guardas automatizados e fluxos de aprovação |
📊 Identificação e Avaliação de Vulnerabilidades
Antes de projetar defesas, é necessário entender as ameaças. Uma avaliação detalhada revela onde estão os pontos fracos. Esse processo envolve mapear dependências e compreender como os dados fluem pela organização.
Mapeamento de Dependências
Sistemas complexos muitas vezes dependem de serviços subjacentes que não são imediatamente óbvios. Uma falha em uma API de terceiros, uma instância específica de banco de dados ou um ponto de integração legado pode parar as operações. Arquitetos devem criar mapas detalhados dessas relações.
- Dependências de Entrada: O que alimenta o sistema? (por exemplo, fontes de dados, provedores de autenticação).
- Dependências de Saída: O que depende do sistema? (por exemplo, ferramentas de relatórios, aplicativos voltados para o cliente).
- Dependências Horizontais: Outros serviços dentro do mesmo ambiente que compartilham recursos.
Análise do Ponto Único de Falha (SPOF)
Um Ponto Único de Falha é um componente cuja falha interrompe todo o processo. Identificar pontos únicos de falha é um exercício crítico na engenharia de resiliência. Áreas comuns de preocupação incluem:
- Bancos de dados centralizados sem replicação.
- Aplicações monolíticas que não podem escalar de forma independente.
- Pontos de intervenção manual que introduzem erros humanos.
- Pontos de gargalo de rede que limitam a largura de banda ou o acesso.
Uma vez identificados, esses pontos devem ser tratados por meio de redundância, automação ou refatoração arquitetônica. O objetivo é distribuir o risco para que nenhuma falha única cause uma parada catastrófica.
🛡️ Padrões Arquitetônicos para Continuidade
Certos padrões de design provaram ser eficazes na manutenção da disponibilidade durante interrupções. Esses padrões devem ser considerados na fase de planejamento para garantir que a arquitetura seja intrinsecamente resiliente.
Desacoplamento de Serviços
Acoplamento rígido cria fragilidade. Quando os componentes dependem fortemente dos detalhes internos de implementação uns dos outros, mudanças ou falhas se propagam rapidamente. O desacoplamento permite que os serviços funcionem de forma independente. Isso geralmente é alcançado por meio de:
- Filas de Mensagens:A comunicação assíncrona garante que, se um consumidor estiver fora do ar, as mensagens aguardem na fila em vez de serem perdidas.
- Gateways de API: Eles atuam como intermediários, lidando com roteamento de tráfego, limitação de taxa e autenticação sem expor a lógica do backend.
- Arquitetura Baseada em Eventos Os sistemas reagem às mudanças de estado em vez de esperar por solicitações, permitindo um processamento mais flexível.
Redundância e Failover
Redundância significa ter backups. Failover é o processo de alternar automaticamente para esses backups. Existem várias estratégias para implementar isso:
- Ativo-Passivo: Um sistema manipula o tráfego enquanto outro permanece em espera. Isso é economicamente viável, mas introduz alguma demora durante a troca.
- Ativo-Ativo: Vários sistemas manipulam o tráfego simultaneamente. Se um falhar, os outros absorvem a carga. Isso oferece maior disponibilidade, mas exige mais recursos.
- Geo-redundância: A implantação da infraestrutura em locais físicos diferentes protege contra desastres regionais, como eventos naturais ou falhas na rede elétrica.
Degradabilidade Graceful
Quando um sistema não consegue funcionar com capacidade total, ele deve degradar-se de forma graciosa em vez de falhar. Isso significa desativar recursos não essenciais para preservar a funcionalidade principal. Por exemplo, se o motor de recomendação falhar, o usuário ainda deverá conseguir navegar pelos produtos, mesmo que não veja sugestões personalizadas.
📋 Integração do Planejamento de Continuidade de Negócios (BCP)
O Planejamento de Continuidade de Negócios é frequentemente tratado como um documento separado, mas deve ser integrado à arquitetura. Controles técnicos devem aplicar as regras de negócios definidas no BCP.
Definindo RTO e RPO
Dois indicadores-chave orientam os esforços de continuidade:
- Objetivo de Tempo de Recuperação (RTO): O tempo máximo aceitável de inatividade. Quanto tempo o negócio pode sobreviver sem este sistema?
- Objetivo de Ponto de Recuperação (RPO): A perda máxima de dados aceitável. Quanto dados podem ser perdidos antes de afetar as operações?
| Criticialidade do Sistema | RTO Alvo | RPO Alvo | Estratégia |
|---|---|---|---|
| Transação com o Cliente | < 5 minutos | < 1 minuto | Replicação em tempo real, Ativo-Ativo |
| Relatórios Internos | < 24 horas | < 24 horas | Backup remoto, restauração agendada |
| Ambiente de desenvolvimento | < 1 semana | < 1 semana | Restauração de instantâneo, intervenção manual |
Automação da recuperação
Processos de recuperação manual são lentos e propensos a erros. Em uma crise, os níveis de estresse são altos, e os procedimentos devem ser executados rapidamente. Automatizar os passos de recuperação garante consistência e velocidade. Isso inclui:
- Gatilhos de failover automático baseados em verificações de saúde.
- Provisionamento automatizado de novos recursos.
- Gerenciamento de configuração para garantir que os ambientes sejam idênticos.
🔄 Estratégias e Execução de Recuperação
Ter um plano não é suficiente. A capacidade de executar esse plano é o que define a resiliência. As estratégias de recuperação devem ser testadas regularmente para garantir que funcionem conforme o esperado.
Protocolos de Teste
Testes regulares validam a capacidade da arquitetura de resistir a falhas. Tipos diferentes de testes servem propósitos distintos:
- Exercícios em mesa: Os membros da equipe discutem cenários e percorrem as respostas sem alterações técnicas.
- Simulação: Simular uma falha em um ambiente não produtivo para verificar os processos.
- Engenharia de Caos: Intencionalmente injetar falhas em um sistema de produção para observar como ele reage e identificar vulnerabilidades.
Canais de Comunicação
Durante um incidente, o fluxo de informações é crítico. Arquitetos devem projetar sistemas que suportem a comunicação mesmo quando os canais principais falharem. Isso inclui:
- Ferramentas de comunicação fora da banda (por exemplo, SMS, canais dedicados de alerta).
- Funções e responsabilidades de incidente pré-definidas.
- Páginas de status que fornecem transparência para stakeholders e clientes.
🔒 Segurança como um Pilar da Resiliência
Segurança e resiliência são inseparáveis. Um ataque cibernético é uma causa primária de interrupção. Portanto, os controles de segurança devem ser projetados para apoiar a continuidade.
Arquitetura Zero Trust
O modelo tradicional de segurança baseado em perímetro é insuficiente para ambientes modernos. O Zero Trust assume que ameaças existem tanto dentro quanto fora da rede. Cada solicitação de acesso é verificada, independentemente da origem. Isso limita a propagação de malware ou acesso não autorizado.
- Verificação de Identidade: Autenticação multifator para todos os usuários e serviços.
- Menor privilégio: Usuários e serviços têm acesso apenas aos recursos específicos de que precisam.
- Microsegmentação: Dividir a rede em pequenas zonas para conter violações.
Proteção de Dados e Criptografia
Proteger os dados garante que, mesmo que os sistemas sejam comprometidos, as informações permaneçam seguras. A criptografia deve ser aplicada em repouso e em trânsito. Os backups devem ser imutáveis, ou seja, não podem ser alterados ou excluídos, protegendo contra ransomware que ataca arquivos de backup.
📈 Governança e Gestão do Ciclo de Vida
A resiliência não é um projeto pontual; é uma disciplina contínua. A governança garante que os padrões de resiliência sejam mantidos à medida que a arquitetura evolui.
Gestão de Mudanças
Mudanças são a causa mais comum de interrupções. Um processo robusto de gestão de mudanças analisa cada modificação quanto ao seu potencial impacto na resiliência. Isso inclui:
- Revisar dependências antes da implantação.
- Garantir que planos de retorno estejam em vigor.
- Validar alterações de configuração em relação aos padrões de segurança.
Monitoramento Contínuo
O monitoramento fornece os dados necessários para manter a saúde. Vai além das verificações de tempo de atividade para incluir métricas de desempenho, taxas de erro e eventos de segurança. Práticas-chave incluem:
- Alertas em Tempo Real: Notificando as equipes imediatamente quando os limites forem ultrapassados.
- Agregação de Logs: Centralizar logs para facilitar a análise durante incidentes.
- Bases de Desempenho: Compreender o comportamento normal para detectar anomalias rapidamente.
🚀 Preparando a Arquitetura para o Futuro
O cenário muda rapidamente. Novas ameaças surgem e as tecnologias evoluem. Uma arquitetura resiliente deve ser flexível o suficiente para se adaptar.
Adaptabilidade e Escalabilidade
Projetar para crescimento e mudanças. Os sistemas devem escalar horizontalmente para lidar com cargas aumentadas sem exigir uma reestruturação completa. Isso envolve o uso de padrões nativos da nuvem que permitem adicionar ou remover recursos dinamicamente.
- Containerização: Empacota aplicativos com suas dependências, garantindo consistência entre ambientes.
- Orquestração: Gerencia automaticamente a implantação e a escala de containers.
- Computação sem servidor:Remove a carga de gerenciamento de servidores, permitindo foco na lógica.
Gestão do Conhecimento
As pessoas saem das organizações. O conhecimento institucional deve ser preservado. A documentação da arquitetura, dos procedimentos de recuperação e das justificativas das decisões garante que as novas equipes possam manter e aprimorar o sistema sem depender do conhecimento tribal.
📌 Resumo das Melhores Práticas
Para resumir o caminho rumo a uma arquitetura empresarial resiliente, considere a seguinte lista de verificação:
- ✅ Mapeie todas as dependências e identifique pontos únicos de falha.
- ✅ Defina metas claras de RTO e RPO com base na criticidade do negócio.
- ✅ Implemente mecanismos de redundância e failover adequados ao risco.
- ✅ Automatize os processos de recuperação para reduzir erros humanos e tempo de inatividade.
- ✅ Integre controles de segurança diretamente no design.
- ✅ Teste os planos de recuperação regularmente por meio de simulações e exercícios.
- ✅ Monitore os sistemas continuamente e gere alertas para anomalias.
- ✅ Documente todos os processos e mantenha controle de versão.
Construir resiliência exige investimento, tempo e disciplina. Não se trata de impedir toda falha, pois isso é impossível. Trata-se de garantir que, quando falhas ocorrerem, a organização consiga continuar atendendo seus clientes e partes interessadas. Ao incorporar esses princípios ao núcleo da Arquitetura Empresarial, os líderes podem garantir que suas organizações permaneçam estáveis, seguras e preparadas para quaisquer desafios que se apresentem.
A jornada rumo à resiliência é contínua. À medida que o ambiente muda, a arquitetura também deve mudar. Revisões regulares, atualizações e melhorias mantêm o sistema robusto. Essa abordagem proativa transforma a arquitetura de um plano estático em um ativo dinâmico que impulsiona o valor e a estabilidade do negócio.

