











Бизнес-процессы редко бывают линейными. В реальном мире данные неполные, системы выходят из строя, а человеческая оценка различается. При моделировании рабочих процессов с использованием модели и нотации бизнес-процессов (BPMN) предполагать, что всё всегда будет проходить успешно, — это рецепт сбоя в производстве. Обработка исключений и пути ошибок — не опциональные функции, а фундаментальные компоненты устойчивой архитектуры процессов. Это руководство описывает, как эффективно структурировать управление ошибками в ваших моделях процессов.
🛑 Почему обработка исключений важна в BPMN
Модель процесса без определённых путей ошибок является неполной. Она описывает «счастливый путь» — сценарий, при котором каждый шаг проходит без сбоев. Однако операционная реальность гораздо сложнее. Когда задача не выполняется в рабочей среде, движок рабочего процесса должен получать чёткие инструкции о том, как реагировать. Без чёткого моделирования:
- Заблокированные экземпляры:Процессы могут бесконечно останавливаться, ожидая условия, которое никогда не будет выполнено.
- Потеря данных:Критическая информация может быть утеряна, если поток завершится внезапно.
- Операционные слепые зоны:Команды могут не знать, какие ошибки являются критическими, а какие — предупреждениями.
- Ручное вмешательство:Пользователи могут быть вынуждены вручную перезапускать неудачные экземпляры без структурированного плана восстановления.
Явно моделируя исключения, вы превращаете хрупкий скрипт в надёжную систему. Такой подход гарантирует, что при возникновении проблем система точно знает, что делать, кого уведомить и как зафиксировать результат.
🧩 Понимание типов событий ошибок в BPMN
BPMN 2.0 предоставляет специфические элементы для представления сбоев. Понимание различий между этими элементами критически важно для точного моделирования. Ошибки — это не просто «остановки»; это события, запускающие определённое поведение.
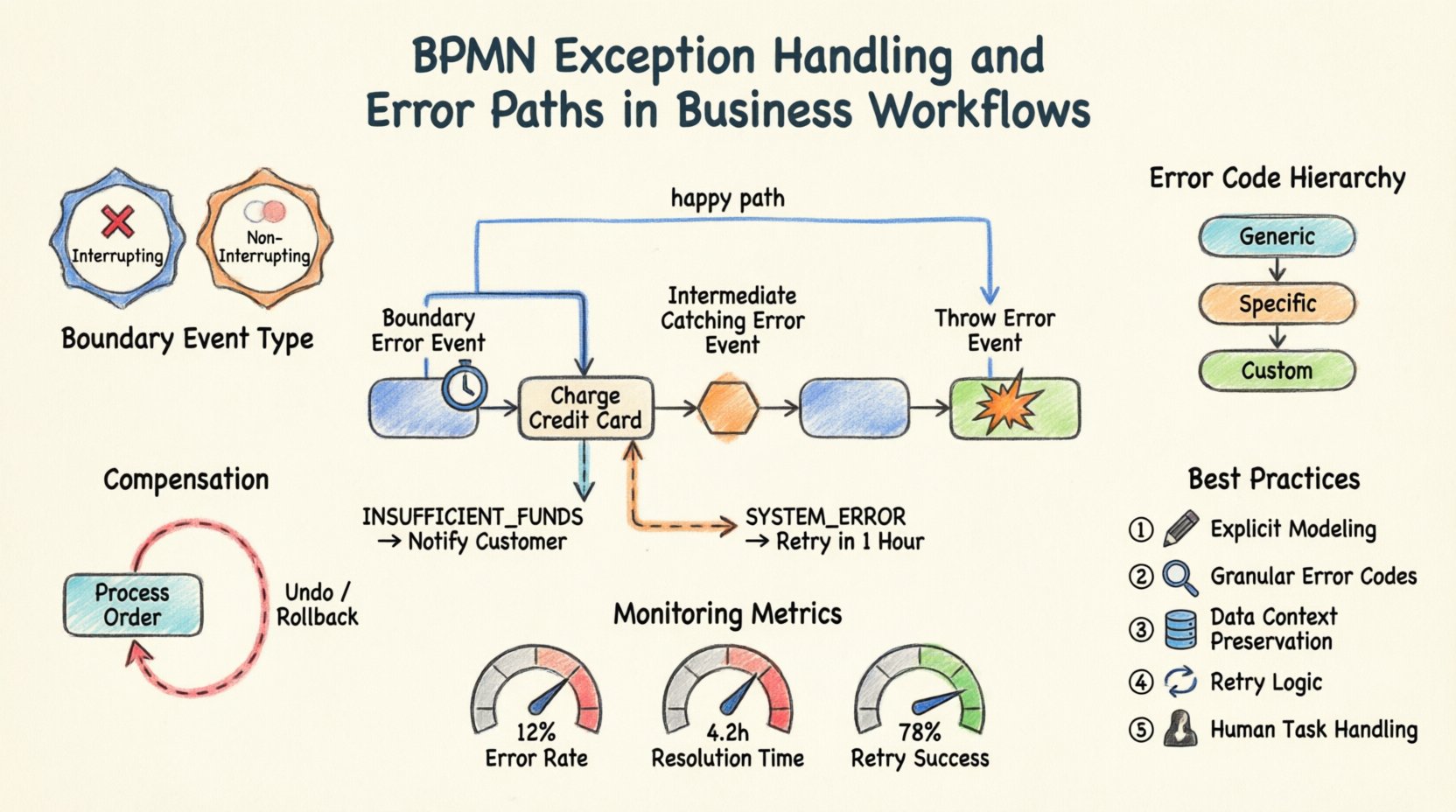
1. События ошибок на границе ⏱️
Событие ошибки на границе привязано к границе действия (задачи или подпроцесса). Оно представляет собой сбой, возникающий в ходевыполнения этого действия. Когда действие генерирует ошибку, поток перенаправляется к событию на границе, что позволяет немедленно обработать ошибку, не прерывая основной поток процесса преждевременно.
- Сценарий использования: Задача оплаты завершается сбоем из-за таймаута. Событие на границе перехватывает эту ситуацию, позволяя повторить оплату или уведомить пользователя.
- Поведение: Основное действие можно настроить на продолжение или остановку. Если оно продолжается, событие на границе запускает параллельный путь.
2. Промежуточные события перехвата ошибок 🛑
Эти события находятся внутри потока процесса, не привязаны к границе действия. Они перехватывают ошибку, сгенерированную предыдущим действием или верхним по потоку процессом. Они выступают контрольной точкой в последовательном потоке.
- Сценарий использования: После серии проверок промежуточное событие перехватывает сбой проверки, прежде чем перейти к этапу выполнения.
- Поведение: Процесс приостанавливается на этом событии до тех пор, пока ошибка не будет обработана, после чего переходит к следующему шагу.
3. События генерации ошибок 💥
Эти события используются в рамках действия для сигнализации о возникновении ошибки. Они являются источником исключения. Действие может определить конкретное условие, при котором оно генерирует ошибку вместо обычного завершения.
- Сценарий использования: Задача интеграции службы обнаруживает ошибку 500 Internal Server Error и генерирует специфический токен ошибки.
- Поведение: Он передает ошибку вверх до ближайшего граничного события ошибки или промежуточного события перехвата ошибки.
⚙️ Подробный разбор: граничные события ошибок
Граничные события ошибок — наиболее распространенный инструмент обработки ошибок в BPMN. Они позволяют сохранить основной поток процесса чистым, одновременно обрабатывая исключения локально.
Варианты конфигурации
При присоединении граничного события ошибки к задаче необходимо определить конкретное поведение:
- Прерывающее vs. Непрерывающее:
- Прерывающее: Основная задача останавливается немедленно. Дальнейшая работа над задачей не выполняется.
- Непрерывающее: Задача продолжает выполняться в фоновом режиме. Путь обработчика ошибок выполняется параллельно. Это полезно для ведения журнала или уведомлений без остановки работы.
- Определение ошибки: Необходимо указать код ошибки. Это позволяет различным граничным событиям перехватывать разные типы ошибок (например, «PAYMENT_TIMEOUT» против «PAYMENT_DECLINED»).
Практический сценарий: шлюз оплаты
Рассмотрим процесс обработки заказа. Задача с названием «Списать с кредитной карты» является центральной в этом потоке.
- Основной путь: Если успешно, процесс переходит к «Отправить заказ».
- Путь ошибки: Присоедините граничное событие ошибки к «Списать с кредитной карты».
- Логика: Если код ошибки — «INSUFFICIENT_FUNDS», поток переходит к «Уведомить клиента».
- Логика: Если код ошибки — «SYSTEM_ERROR», поток переходит к «Повторить через 1 час».
Эта структура предотвращает сбой процесса. Она направляет пользователя по правильному пути решения в зависимости от конкретной природы сбоя.
🔄 Промежуточные события ошибок и распространение
Не все ошибки перехватываются немедленно на источнике. Иногда ошибки должны распространяться вверх по иерархии процесса. Промежуточные события перехвата ошибок способствуют этому.
Обработка ошибок в подпроцессе
При использовании встроенного подпроцесса ошибки, возникающие внутри подпроцесса, могут обрабатываться двумя способами:
- Внутренняя обработка: Ошибки перехватываются внутри подпроцесса с помощью граничных событий. Подпроцесс завершается обычным образом (или с определённым состоянием завершения) без выброса ошибки в родительский процесс.
- Внешнее распространение: Ошибки выбрасываются из подпроцесса. Родительский процесс перехватывает их с помощью граничного события на самом подпроцессе или промежуточного события ошибки в основном потоке.
Коды ошибок и иерархия
Для эффективного управления распространением определите иерархию кодов ошибок:
- Общие ошибки: События-ловушки для неожиданных сбоев системы.
- Конкретные ошибки: События для известных сбоев бизнес-логики (например, «Неверный адрес»).
- Пользовательские коды: Конкретные коды, определённые вашим слоем интеграции.
Использование конкретных кодов гарантирует, что будет вызван правильный обработчик. Общая ловушка должна быть последним средством, а не первым.
💸 Стратегии компенсации и отката
Иногда ошибка обнаруживается после того, как серия действий уже завершена. В таких случаях просто остановка процесса недостаточна. Возможно, потребуется отменить изменения. Именно здесь и приходят на помощь события компенсации.
Что такое компенсация?
Компенсация — это действие по отмене завершённой операции. Она отличается от обработки ошибок, поскольку решает последствия успешного завершения, за которым последовал сбой на последующем этапе.
- Сценарий использования: Вы успешно забронировали рейс, но бронирование отеля не удалось. Бронирование рейса необходимо отменить, чтобы избежать оплаты.
- Моделирование: Вы определяете компенсационную активность, связанную с исходной активностью.
Когда использовать компенсацию
Используйте события компенсации, когда:
- Процесс длительный.
- Внешние системы нельзя легко откатить.
- Целостность данных должна поддерживаться на нескольких этапах.
Без компенсации ваша модель процесса оставляет несвязанные записи или несогласованные состояния в системе основных данных.
📊 Матрица сравнения обработки ошибок
Чтобы прояснить различия между различными механизмами обработки ошибок, обратитесь к этой структурированной сравнительной таблице.
| Элемент | Местоположение | Событие | Основной сценарий использования |
|---|---|---|---|
| Событие ошибки на границе | Привязано к задаче | Сбой задачи | Немедленная повторная попытка или уведомление пользователя |
| Промежуточное событие ошибки | Внутри потока | Ошибка в上游 | Перехват ошибок после последовательности задач |
| Событие выброса ошибки | Внутри задачи | Логическое условие | Сигнализация о сбое обработчикам верхнего уровня |
| Событие компенсации | Связано с завершенной задачей | Последующий сбой | Отмена предыдущих действий (откат) |
🗂️ Управление контекстом данных при ошибках
Когда возникает ошибка, состояние данных имеет критическое значение. Просто знать, что произошла ошибка, часто недостаточно. Вам нужно знать почему и что данные вызвали это.
Переменные ошибки
Движки BPMN позволяют передавать переменные обработчикам ошибок. Убедитесь, что ваша модель фиксирует:
- Код ошибки: Стандартизированный идентификатор (например, «ERR_101»).
- Сообщение об ошибке: Человекочитаемое описание для журналов.
- Данные контекста: Связанные бизнес-данные (например, ID заказа, имя клиента), которые помогут в устранении неполадок.
Сохранение данных
Убедитесь, что данные, собранные до возникновения ошибки, сохраняются. Не полагайтесь на временную память. Если экземпляр процесса останавливается из-за ошибки, следующий экземпляр должен иметь доступ к тому же контексту данных для возобновления обработки.
🧪 Тестирование и проверка путей ошибок
Моделирование путей ошибок — это лишь половина работы. Вам необходимо проверить, что они корректно функционируют в среде выполнения. Тестирование путей ошибок требует иного подхода, чем тестирование путей успеха.
Чек-лист проверки ✅
- Недостижимый код: Убедитесь, что пути ошибок не создают взаимоблокировок или недостижимых узлов.
- Покрытие: Убедитесь, что каждый потенциальный пункт отказа имеет соответствующий обработчик ошибок.
- Тайм-ауты: Протестируйте, что происходит, когда задача превышает свой лимит времени.
- Сбой интеграции: Имитируйте простои API, чтобы убедиться, что срабатывает граничное событие.
- Целостность данных: Убедитесь, что после отката не остается частичных данных.
Инструменты моделирования
Используйте инструменты моделирования процессов для внесения сбоев в рабочий процесс. Это позволяет наблюдать за поведением процесса под нагрузкой, не затрагивая производственные данные. Обратите внимание на:
- Неожиданное завершение процесса.
- Некорректные сообщения об ошибках, записанные в журнал.
- Неудача в уведомлении соответствующих заинтересованных сторон.
🚧 Распространённые ошибки, которые следует избегать
Даже опытные моделисты допускают ошибки при проектировании обработки ошибок. Будьте внимательны к этим распространённым ловушкам.
1. Пренебрежение «пути успеха»
Не загромождайте основной поток логикой обработки ошибок. Держите основной поток чистым. Используйте граничные события и подпроцессы для изоляции логики ошибок. Это делает модель проще для чтения и поддержки.
2. Чрезмерное использование граничных событий
Присоединение граничного события к каждой отдельной задаче может сделать диаграмму запутанной и непонятной. Присоединяйте их только к задачам, сбой в которых оказывает значительное влияние или требует специальной логики обработки.
3. Неясные сообщения об ошибках
Избегайте общих сообщений об ошибках, таких как «Что-то пошло не так». Используйте конкретные коды и сообщения, которые понятны разработчикам и бизнес-пользователям. Это способствует более быстрому устранению проблем.
4. Отсутствие логики повторных попыток
Временные ошибки (например, сбои в сети) должны повторяться. Явно моделируйте механизмы повторных попыток с использованием таймеров или циклов. Не позволяйте временной ошибке превратиться в постоянную.
5. Забывание о человеческих задачах
Человеческие задачи также могут завершиться неудачно. Пользователь может проигнорировать задачу или ввести недопустимые данные. Определите, что происходит, если человеческая задача была оставлена или отклонена. Часто для этого требуется другой путь обработки ошибок, чем для системных задач.
🔍 Мониторинг и готовность к эксплуатации
Как только процесс запущен, пути обработки ошибок становятся вашей первой линией обороны. Мониторинг необходим для обеспечения того, чтобы эти пути работали так, как задумано.
Ключевые метрики
- Уровень ошибок: Процент экземпляров процесса, которые попадают в путь ошибки.
- Время устранения: Сколько времени требуется для восстановления после ошибки.
- Успешность повторных попыток: Насколько часто автоматические повторные попытки устраняют проблему.
Оповещения
Настройте оповещения для критических путей ошибок. Если определенный код ошибки резко возрастает, это указывает на системную проблему, требующую немедленного внимания. Не рассматривайте все ошибки одинаково; приоритеты должны быть у тех, которые влияют на доход или соответствие требованиям.
📝 Обобщение лучших практик
Чтобы обеспечить устойчивость ваших бизнес-процессов, придерживайтесь этих основных принципов:
- Явное моделирование: Никогда не предполагайте, что ошибка будет обработана движком. Определите её на диаграмме.
- Детализированная обработка: Используйте конкретные коды ошибок для направления в соответствующий обработчик.
- Сознание данных: Сохраняйте контекстные данные при сбоях для аудита и отладки.
- Компенсация: Планируйте отмену действий при необходимости.
- Тестирование: Проверяйте пути обработки ошибок так же тщательно, как и основной поток.
Вложив время в моделирование исключений, вы создаете процессы, которые не только эффективны, но и устойчивы. Хорошо обработанная ошибка часто лучше, чем отсутствие ошибки, поскольку она сохраняет доверие и ясность в системе. Сосредоточьтесь на ясности, точности и готовности к эксплуатации в ваших моделях BPMN.
🔗 Следующие шаги по внедрению
Начните с аудита ваших существующих процессов. Определите задачи с высоким риском, где сбой будет дорогостоящим. Сначала моделируйте граничные события для этих задач. Постепенно расширяйте до промежуточных событий и логики компенсации. Такой поэтапный подход обеспечивает стабильность при повышении устойчивости.
Документируйте свою стратегию обработки ошибок. Создайте справочное руководство для разработчиков и аналитиков, объясняющее коды ошибок и ожидаемое поведение. Эта документация становится ценным активом для поддержки процесса в долгосрочной перспективе.
Помните, цель не в полном устранении ошибок, а в их эффективном управлении. Когда вы чётко моделируете пути ошибок, вы обеспечиваете системе возможность гладкого восстановления и продолжения движения бизнеса.

