In the modern digital landscape, stability is not a luxury; it is a fundamental requirement. Organizations face a constant barrage of disruptions, ranging from cyber threats and infrastructure failures to geopolitical shifts and supply chain interruptions. Resilient Enterprise Architecture stands as the blueprint for navigating these uncertainties. It is the practice of designing systems that do not merely survive shocks but continue to operate effectively during and after adverse events.
This guide explores the core components of building an architecture capable of sustaining business operations. We will move beyond basic redundancy to discuss strategic alignment, risk management, and the integration of continuity planning into the very fabric of technical design. The goal is to create systems that are robust, adaptable, and aligned with long-term organizational objectives.
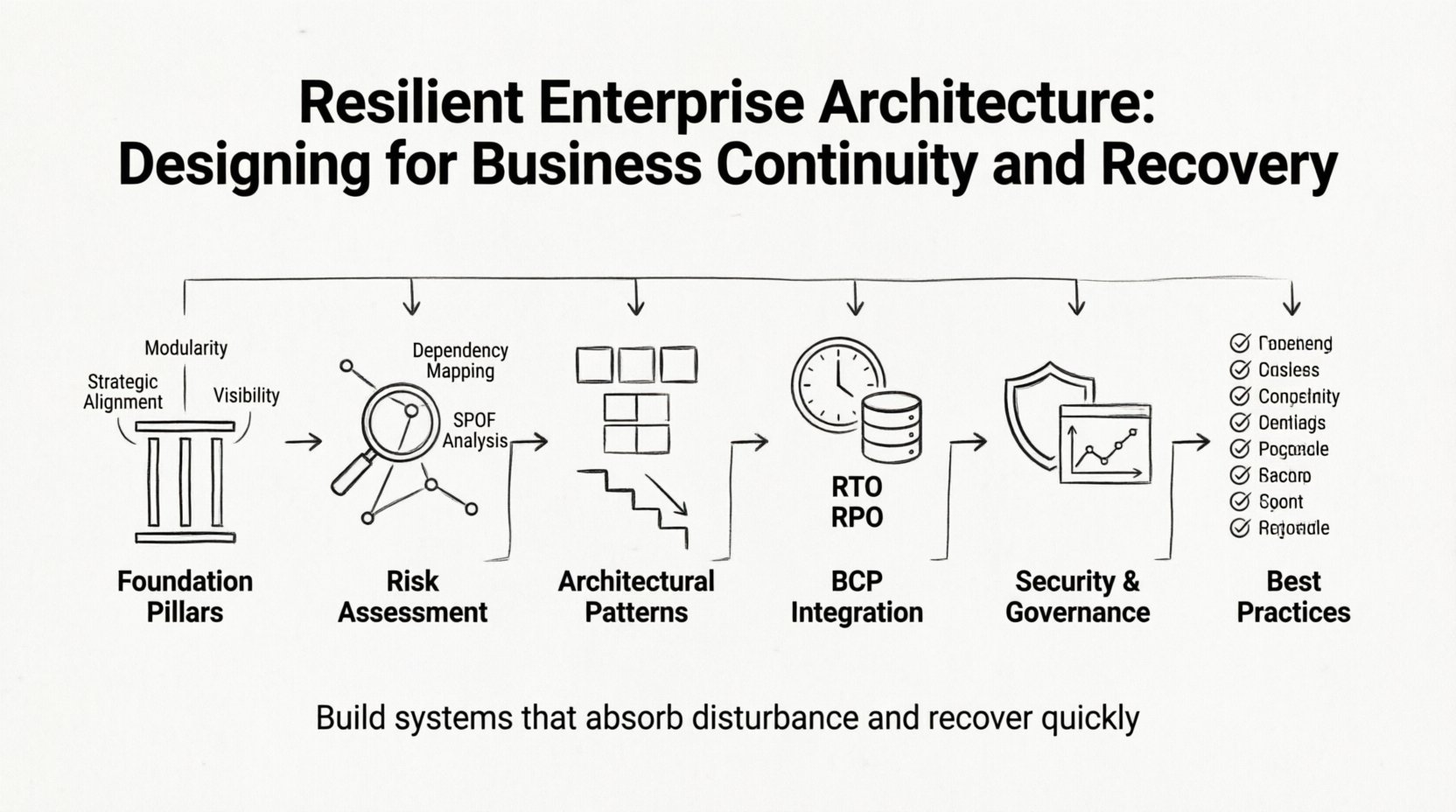
🧱 The Foundations of Resilient Architecture
Resilience differs from reliability. Reliability ensures a system works when it is supposed to. Resilience ensures a system works even when things go wrong. It is the ability to absorb disturbance and recover quickly. To achieve this, architects must look at the organization as a holistic ecosystem rather than a collection of isolated silos.
Core Pillars of Resilience
Building a resilient framework requires attention to three distinct but interconnected areas:
- Strategic Alignment: Technology decisions must support business goals. If the business prioritizes customer trust, the architecture must prioritize data security and availability.
- Modularity: Systems should be broken down into independent components. This prevents a failure in one module from cascading through the entire environment.
- Visibility: You cannot manage what you cannot see. Comprehensive monitoring and logging are essential for detecting anomalies early.
Understanding Risk Appetite
Every organization has a different tolerance for risk. Some sectors require near-zero downtime, while others can tolerate brief interruptions. Defining this risk appetite is the first step in architectural design. It dictates the investment required for redundancy, backup strategies, and recovery time objectives.
| Risk Category | Impact Level | Architectural Response |
|---|---|---|
| Critical Infrastructure Failure | High | Active-Active redundancy across geographies |
| Data Corruption | Medium | Immutable backups with versioning |
| Network Latency | Low | Load balancing and caching strategies |
| Human Error | Medium | Automated guardrails and approval workflows |
📊 Identifying and Assessing Vulnerabilities
Before designing defenses, one must understand the threats. A thorough assessment reveals where the weak points lie. This process involves mapping dependencies and understanding how data flows through the organization.
Dependency Mapping
Complex systems often rely on underlying services that are not immediately obvious. A failure in a third-party API, a specific database instance, or a legacy integration point can halt operations. Architects must create detailed maps of these relationships.
- Upstream Dependencies: What feeds into the system? (e.g., data sources, authentication providers).
- Downstream Dependencies: What relies on the system? (e.g., reporting tools, customer-facing apps).
- Horizontal Dependencies: Other services within the same environment that share resources.
The Single Point of Failure (SPOF) Analysis
A Single Point of Failure is a component whose failure stops the entire process. Identifying SPOFs is a critical exercise in resilience engineering. Common areas of concern include:
- Centralized databases without replication.
- Monolithic applications that cannot scale independently.
- Manual intervention points that introduce human error.
- Network choke points that limit bandwidth or access.
Once identified, these points must be addressed through redundancy, automation, or architectural refactoring. The objective is to distribute risk so that no single failure causes a catastrophic outage.
🛡️ Architectural Patterns for Continuity
Certain design patterns have proven effective in maintaining availability during disruptions. These patterns should be considered during the planning phase to ensure the architecture is inherently resilient.
Decoupling Services
Tight coupling creates fragility. When components depend heavily on each other’s internal implementation details, changes or failures propagate rapidly. Decoupling allows services to function independently. This is often achieved through:
- Message Queues: Asynchronous communication ensures that if a consumer is down, messages wait in the queue rather than being lost.
- API Gateways: These act as intermediaries, handling traffic routing, rate limiting, and authentication without exposing backend logic.
- Event-Driven Architecture: Systems react to state changes rather than waiting for requests, allowing for more flexible processing.
Redundancy and Failover
Redundancy means having backups. Failover is the process of switching to those backups automatically. There are several strategies for implementing this:
- Active-Passive: One system handles traffic while another stands by. This is cost-effective but introduces some delay during a switch.
- Active-Active: Multiple systems handle traffic simultaneously. If one fails, the others absorb the load. This offers higher availability but requires more resources.
- Geo-Redundancy: Deploying infrastructure across different physical locations protects against regional disasters like natural events or power grid failures.
Graceful Degradation
When a system cannot function at full capacity, it should degrade gracefully rather than crashing. This means turning off non-essential features to preserve core functionality. For example, if the recommendation engine fails, the user should still be able to browse products, even if they do not see personalized suggestions.
📋 Integrating Business Continuity Planning (BCP)
Business Continuity Planning is often treated as a separate document, but it must be integrated into the architecture. Technical controls should enforce the business rules defined in the BCP.
Defining RTO and RPO
Two key metrics guide continuity efforts:
- Recovery Time Objective (RTO): The maximum acceptable downtime. How long can the business survive without this system?
- Recovery Point Objective (RPO): The maximum acceptable data loss. How much data can be lost before it impacts operations?
| System Criticality | Target RTO | Target RPO | Strategy |
|---|---|---|---|
| Customer Facing Transaction | < 5 minutes | < 1 minute | Real-time replication, Active-Active |
| Internal Reporting | < 24 hours | < 24 hours | Offsite backup, Scheduled restore |
| Development Environment | < 1 week | < 1 week | Snapshot restore, Manual intervention |
Automation of Recovery
Manual recovery processes are slow and prone to error. In a crisis, stress levels are high, and procedures must be executed quickly. Automating the recovery steps ensures consistency and speed. This includes:
- Automatic failover triggers based on health checks.
- Scripted provisioning of new resources.
- Configuration management to ensure environments are identical.
🔄 Recovery Strategies and Execution
Having a plan is not enough. The ability to execute that plan is what defines resilience. Recovery strategies must be tested regularly to ensure they work as intended.
Testing Protocols
Regular testing validates the architecture’s ability to withstand failure. Different types of tests serve different purposes:
- Tabletop Exercises: Team members discuss scenarios and walk through responses without technical changes.
- Simulation: Simulating a failure in a non-production environment to verify processes.
- Chaos Engineering: Intentionally injecting failures into a production system to observe how it reacts and identify weaknesses.
Communication Channels
During an incident, information flow is critical. Architects must design systems that support communication even when primary channels fail. This includes:
- Out-of-band communication tools (e.g., SMS, dedicated alert channels).
- Pre-defined incident roles and responsibilities.
- Status pages that provide transparency to stakeholders and customers.
🔒 Security as a Pillar of Resilience
Security and resilience are inseparable. A cyberattack is a primary cause of disruption. Therefore, security controls must be designed to support continuity.
Zero Trust Architecture
The traditional perimeter-based security model is insufficient for modern environments. Zero Trust assumes that threats exist both inside and outside the network. Every access request is verified, regardless of origin. This limits the spread of malware or unauthorized access.
- Identity Verification: Multi-factor authentication for all users and services.
- Least Privilege: Users and services only have access to the specific resources they need.
- Micro-segmentation: Dividing the network into small zones to contain breaches.
Data Protection and Encryption
Protecting data ensures that even if systems are compromised, the information remains safe. Encryption should be applied at rest and in transit. Backups must be immutable, meaning they cannot be altered or deleted, protecting against ransomware that targets backup files.
📈 Governance and Lifecycle Management
Resilience is not a one-time project; it is an ongoing discipline. Governance ensures that resilience standards are maintained as the architecture evolves.
Change Management
Changes are the most common cause of outages. A robust change management process reviews every modification for potential impact on resilience. This includes:
- Reviewing dependencies before deployment.
- Ensuring rollback plans are in place.
- Validating configuration changes against security baselines.
Continuous Monitoring
Monitoring provides the data needed to maintain health. It goes beyond uptime checks to include performance metrics, error rates, and security events. Key practices include:
- Real-time Alerts: Notifying teams immediately when thresholds are breached.
- Log Aggregation: Centralizing logs for easier analysis during incidents.
- Performance Baselines: Understanding normal behavior to detect anomalies quickly.
🚀 Future Proofing the Architecture
The landscape changes rapidly. New threats emerge, and technologies evolve. A resilient architecture must be flexible enough to adapt.
Adaptability and Scalability
Design for growth and change. Systems should scale horizontally to handle increased load without requiring a complete redesign. This involves using cloud-native patterns that allow resources to be added or removed dynamically.
- Containerization: Packages applications with their dependencies, ensuring consistency across environments.
- Orchestration: Manages the deployment and scaling of containers automatically.
- Serverless Computing: Removes the burden of server management, allowing focus on logic.
Knowledge Management
People leave organizations. Institutional knowledge must be preserved. Documentation of the architecture, recovery procedures, and decision rationales ensures that new teams can maintain and improve the system without relying on tribal knowledge.
📌 Summary of Best Practices
To summarize the path toward a resilient enterprise architecture, consider the following checklist:
- ✅ Map all dependencies and identify Single Points of Failure.
- ✅ Define clear RTO and RPO targets based on business criticality.
- ✅ Implement redundancy and failover mechanisms appropriate to the risk.
- ✅ Automate recovery processes to reduce human error and downtime.
- ✅ Integrate security controls directly into the design.
- ✅ Test recovery plans regularly through simulations and drills.
- ✅ Monitor systems continuously and alert on anomalies.
- ✅ Document all processes and maintain version control.
Building resilience requires investment, time, and discipline. It is not about preventing every failure, as that is impossible. It is about ensuring that when failures occur, the organization can continue to serve its customers and stakeholders. By embedding these principles into the core of Enterprise Architecture, leaders can ensure their organizations remain stable, secure, and ready for whatever challenges lie ahead.
The journey toward resilience is continuous. As the environment changes, so must the architecture. Regular reviews, updates, and improvements keep the system robust. This proactive approach transforms architecture from a static blueprint into a dynamic asset that drives business value and stability.

