











Procesy biznesowe rzadko są liniowe. W świecie rzeczywistym dane są niekompletne, systemy wyłączają się, a ocena ludzka się różni. Podczas modelowania przepływów pracy za pomocą języka modelowania i notacji procesów biznesowych (BPMN) zakładanie, że wszystko zawsze się powiedzie, to przepis na awarię w środowisku produkcyjnym. Obsługa wyjątków i ścieżki błędów to nie opcjonalne funkcje, lecz podstawowe elementy odpornego architektury procesów. Niniejszy przewodnik szczegółowo wyjaśnia, jak skutecznie strukturyzować zarządzanie błędami w modelach procesów.
🛑 Dlaczego obsługa wyjątków ma znaczenie w BPMN
Model procesu bez zdefiniowanych ścieżek błędów jest niepełny. Opisuje tzw. „ścieżkę szczęścia” – sytuację, w której każdy krok przebiega idealnie. Jednak rzeczywistość operacyjna jest znacznie bardziej złożona. Gdy zadanie zawiedzie w środowisku produkcyjnym, silnik przepływu pracy potrzebuje jasnych instrukcji, jak reagować. Bez jasnego modelowania:
- Zablokowane wystąpienia:Procesy mogą być nieograniczenie zawieszone, czekając na warunek, który nigdy nie zostanie spełniony.
- Przegrane dane:Krytyczne informacje mogą zostać utracone, jeśli przepływ zostanie nagle przerwany.
- Ślepe punkty operacyjne:Zespoły mogą nie wiedzieć, które błędy są krytyczne, a które to tylko ostrzeżenia.
- Wprowadzanie ręczne:Użytkownicy mogą zostać zmuszeni do ręcznego ponownego uruchomienia zawiedzionych wystąpień bez strukturalnego planu odzyskania.
Jasne modelowanie wyjątków przekształca zniszczalny skrypt w odporny system. Ten podejście zapewnia, że w przypadku awarii system wie dokładnie, co zrobić, kto powinien zostać powiadomiony i jak zarejestrować wynik.
🧩 Zrozumienie typów zdarzeń błędów w BPMN
BPMN 2.0 oferuje konkretne elementy do reprezentowania awarii. Zrozumienie różnicy między tymi elementami jest kluczowe dla poprawnego modelowania. Błędy to nie tylko „zatrzymanie”; to zdarzenia, które wywołują określone zachowania.
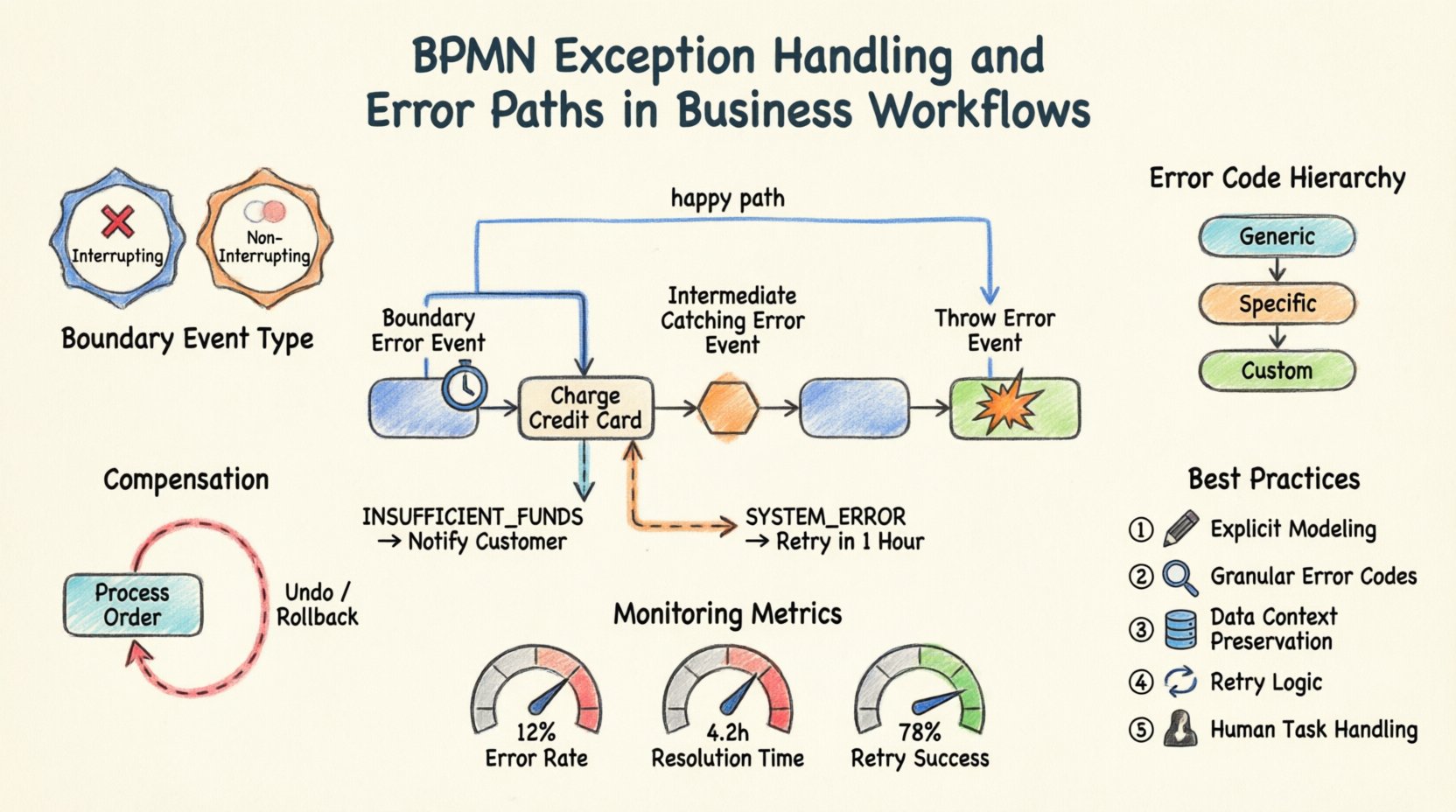
1. Zdarzenia błędów na brzegu ⏱️
Zdarzenie błędu na brzegu jest przypisane do brzegu aktywności (zadania lub podprocesu). Reprezentuje awarię występującą podczaswykonywania tej aktywności. Gdy aktywność zgłasza błąd, przepływ zmienia kierunek w kierunku zdarzenia na brzegu, umożliwiając natychmiastową obsługę bez wcześniejszego przerwania głównego przepływu procesu.
- Przypadek użycia:Zadanie płatności zawiedzie z powodu przekroczenia limitu czasu. Zdarzenie na brzegu przechwytuje ten błąd, umożliwiając ponowną próbę płatności lub powiadomienie użytkownika.
- Zachowanie:Główna aktywność może być skonfigurowana tak, aby kontynuować lub zatrzymać się. Jeśli kontynuuje, zdarzenie na brzegu uruchamia równoległą ścieżkę.
2. Pośrednie zdarzenia przechwytywania błędów 🛑
Te zdarzenia znajdują się wewnątrz przepływu procesu, nie są przypisane do brzegu aktywności. Przechwytują błąd zgłoszony przez poprzednią aktywność lub proces wyższego poziomu. Są punktem kontrolnym w ciągu przepływu.
- Przypadek użycia:Po serii kroków weryfikacji, pośrednie zdarzenie błędu przechwytuje niepowodzenie weryfikacji przed przejściem do etapu realizacji.
- Zachowanie:Proces zawiesza się na tym zdarzeniu, aż błąd zostanie obsłużony, a następnie przechodzi do następnego kroku.
3. Zdarzenia zgłaszania błędów 💥
Te zdarzenia są używane w aktywności, aby sygnalizować, że wystąpił błąd. Są one źródłem wyjątku. Aktywność może zdefiniować określony warunek, w którym rzuca błąd zamiast zakończyć się normalnie.
- Przypadek użycia: Zadanie integracji usługi wykrywa błąd 500 Internal Server Error i rzuca określony token błędu.
- Zachowanie: Przepływa błąd w górę do najbliższego zdarzenia błędu granicznego lub pośredniego zdarzenia przechwytywania błędu.
⚙️ Głęboka analiza: Zdarzenia błędu graniczne
Zdarzenia błędu graniczne to najpowszechniejszy narzędzie do obsługi błędów w BPMN. Pozwalają one zachować główny przebieg procesu czysty, zarazem zarządzając wyjątkami lokalnie.
Opcje konfiguracji
Gdy dołączasz zdarzenie błędu granicznego do zadania, musisz zdefiniować konkretne zachowania:
- Przerywające vs. Nieprzerywające:
- Przerywające: Zadanie główne jest natychmiast zatrzymywane. Na zadaniu nie wykonuje się już żadnej dalszej pracy.
- Nieprzerywające: Zadanie kontynuuje działanie w tle. Ścieżka obsługi błędu działa równolegle. Jest to przydatne do rejestrowania lub powiadamiania bez zatrzymywania pracy.
- Definicja błędu: Musisz określić kod błędu. Pozwala to różnym zdarzeniom błędu granicznych przechwytywać różne typy błędów (np. „PAYMENT_TIMEOUT” vs „PAYMENT_DECLINED”).
Praktyczny scenariusz: Brama płatności
Rozważ proces przetwarzania zamówienia. Zadanie o nazwie „Zdeponuj kartę kredytową” jest kluczowe dla tego przebiegu.
- Główna ścieżka: Jeśli zakończy się sukcesem, proces przechodzi do „Wyslij zamówienie”.
- Ścieżka błędu: Dołącz zdarzenie błędu granicznego do „Zdeponuj kartę kredytową”.
- Logika: Jeśli kod błędu to „INSUFFICIENT_FUNDS”, przepływ przechodzi do „Powiadom klienta”.
- Logika: Jeśli kod błędu to „SYSTEM_ERROR”, przepływ przechodzi do „Ponów za 1 godzinę”.
Ta struktura zapobiega awarii procesu. Kieruje użytkownika do odpowiedniej ścieżki rozwiązywania problemu w zależności od konkretnego rodzaju awarii.
🔄 Pośrednie zdarzenia błędu i propagacja
Nie wszystkie błędy są przechwytywane od razu w źródle. Czasem błędy muszą być propagowane w górę hierarchii procesu. Pośrednie zdarzenia przechwytywania błędów ułatwiają to.
Obsługa błędów w podprocesie
Podczas używania zagnieżdżonego podprocesu błędy występujące wewnątrz podprocesu mogą być obsługiwane na dwa sposoby:
- Wewnętrzna obsługa: Błędy są przechwytywane wewnątrz podprocesu za pomocą zdarzeń brzegowych. Podproces kończy działanie zgodnie z normalnym przebiegiem (lub z określonym stanem zakończenia), nie rzucając błędu do procesu nadrzędnego.
- Zewnętrzne propagowanie: Błędy są rzucone poza podproces. Proces nadrzędny przechwytuje je za pomocą zdarzenia brzegowego na samym podprocesie lub zdarzenia pośredniego błędu w głównym przebiegu.
Kody błędów i hierarchia
Aby skutecznie zarządzać propagacją, zdefiniuj hierarchię kodów błędów:
- Ogólne błędy: Zdarzenia ogólne dla nieoczekiwanych awarii systemu.
- Specyficzne błędy: Zdarzenia dla znanych błędów logiki biznesowej (np. „Nieprawidłowy adres”).
- Niestandardowe kody: Specyficzne kody zdefiniowane przez warstwę integracji.
Używanie konkretnych kodów zapewnia, że zostanie wywołany odpowiedni obsługujący. Ogólny mechanizm przechwytywania powinien być ostatnią opcją, a nie pierwszą.
💸 Strategie kompensacji i cofania
Czasem błąd zostaje wykryty po wykonaniu serii działań. W takich przypadkach po prostu zatrzymanie procesu nie wystarcza. Możliwe, że należy cofnąć zmiany. To właśnie wtedy wchodzą w grę zdarzenia kompensacji.
Czym jest kompensacja?
Kompensacja to działanie odwrócenia wykonanej aktywności. Jest ona odmienna od obsługi błędów, ponieważ dotyczy skutków sukcesu, który został następnie zakończony niepowodzeniem w kolejnym kroku.
- Przykład użycia: Pomyślnie zarezerwowałeś lot, ale rezerwacja hotelu się nie powiodła. Rezerwacja lotu musi zostać anulowana, aby uniknąć opłat.
- Modelowanie: Określasz aktywność kompensacji powiązaną z oryginalną aktywnością.
Kiedy używać kompensacji
Używaj zdarzeń kompensacji, gdy:
- Proces jest długotrwały.
- Systemy zewnętrzne nie mogą być łatwo cofnięte.
- Integralność danych musi być zachowana przez wiele kroków.
Bez kompensacji model procesu pozostawia niezwiązane rekordy lub niezgodne stany w systemie podstawowym.
📊 Macierz porównawcza obsługi błędów
Aby wyjaśnić różnice między różnymi mechanizmami obsługi błędów, odwołaj się do tej uporządkowanej porównawczej analizy.
| Element | Lokalizacja | Wyzwalacz | Główny przypadek użycia |
|---|---|---|---|
| Zdarzenie błędu brzegowego | Przypięte do zadania | Niepowodzenie zadania | Natychmiastowe ponowne próby lub powiadomienie użytkownika |
| Pośrednie zdarzenie błędu | W ramach przepływu | Błąd z przepływu wstecznego | Przechwytywanie błędów po sekwencji zadań |
| Zdarzenie rzucania błędu | Wewnątrz zadania | Warunek logiczny | Sygnalizowanie niepowodzenia handlerom z przepływu wstecznego |
| Zdarzenie kompensacji | Powiązane z zakończonym zadaniem | Następne niepowodzenie | Cofnięcie poprzednich działań (Rollback) |
🗂️ Zarządzanie kontekstem danych podczas błędów
Gdy występuje błąd, stan danych jest krytyczny. Po prostu wiedzieć, że wystąpił błąd, często nie wystarcza. Musisz wiedzieć dlaczego i co dane spowodowały to.
Zmienne błędu
Silniki BPMN pozwalają przekazywać zmienne do obsługi błędów. Upewnij się, że Twój model zapisuje:
- Kod błędu: Standardowy identyfikator (np. „ERR_101”).
- Komunikat błędu: Czytelny dla człowieka opis do dzienników.
- Dane kontekstowe: Odpowiednie dane biznesowe (np. numer zamówienia, imię klienta), które pomagają w rozwiązywaniu problemów.
Trwałość danych
Upewnij się, że dane zebrane przed błędem są trwale zapisane. Nie polegaj na pamięci tymczasowej. Jeśli instancja procesu zostanie przerwana z powodu błędu, następna instancja musi mieć dostęp do tego samego kontekstu danych, aby wznowić przetwarzanie.
🧪 Testowanie i weryfikacja ścieżek błędów
Modelowanie ścieżek błędów to tylko połowa pracy. Musisz zweryfikować, czy działają poprawnie w środowisku uruchomieniowym. Testowanie ścieżek błędów wymaga innego podejścia niż testowanie ścieżek głównych.
Karta weryfikacyjna ✅
- Niedostępna logika: Upewnij się, że ścieżki błędów nie powodują zakleszczeń ani nieosiągalnych węzłów.
- Obejmowanie: Upewnij się, że każdy potencjalny punkt awarii ma odpowiedni obsługę błędu.
- Przekroczenia limitu czasu: Przetestuj, co się dzieje, gdy zadanie przekracza limit czasu.
- Awaria integracji: Symuluj awarię interfejsu API, aby upewnić się, że zdarzenie graniczne zostanie wyzwolone.
- Integralność danych: Potwierdź, że po cofnięciu nie pozostaje żadna niepełna data.
Narzędzia symulacji
Użyj narzędzi symulacji procesów, aby wstrzykiwać błędy do przepływu pracy. Pozwala to obserwować zachowanie procesu pod obciążeniem bez wpływu na dane produkcyjne. Szukaj:
- Nieoczekiwane zakończenie procesu.
- Niepoprawne komunikaty błędów zapisywane w dziennikach.
- Niepowodzenie w powiadomieniu odpowiednich stakeholderów.
🚧 Najczęstsze pułapki do uniknięcia
Nawet doświadczeni modelerzy popełniają błędy podczas projektowania obsługi błędów. Bądź na baczności przed tymi częstymi pułapkami.
1. Ignorowanie „ścieżki głównych”
Nie zanieczyszczaj głównego przebiegu logiką obsługi błędów. Zachowaj główny przebieg czysty. Używaj zdarzeń granicznych i podprocesów do izolowania logiki błędów. Dzięki temu model staje się łatwiejszy do odczytania i utrzymania.
2. Nadmierna liczba zdarzeń granicznych
Przyczepianie zdarzenia granicznego do każdego pojedynczego zadania może spowodować zamieszanie i nieczytelność schematu. Przyczepiaj je tylko do zadań, gdzie awaria ma istotny wpływ lub wymaga specyficznej logiki obsługi.
3. Nieprecyzyjne komunikaty o błędach
Unikaj ogólnych komunikatów o błędach, takich jak „Coś poszło nie tak”. Używaj konkretnych kodów i komunikatów, które mogą zrozumieć deweloperzy i użytkownicy biznesowi. Pomaga to szybciej rozwiązać problem.
4. Brak mechanizmu ponownych prób
Błędy tymczasowe (takie jak problemy z siecią) powinny być ponawiane. Modeluj mechanizmy ponownych prób jawnie, używając timera lub pętli. Nie pozwól, by błąd tymczasowy stał się trwałym błędem.
5. Zapominanie o zadaniach człowieka
Zadania człowieka również mogą się nie powieść. Użytkownik może zignorować zadanie lub wprowadzić nieprawidłowe dane. Zdefiniuj, co się dzieje, jeśli zadanie człowieka zostanie porzucone lub odrzucone. Często wymaga to innego ścieżki błędu niż zadania systemowe.
🔍 Monitorowanie i gotowość operacyjna
Gdy proces jest uruchomiony, ścieżki błędów stają się Twoją pierwszą linią obrony. Monitorowanie jest niezbędne, aby upewnić się, że te ścieżki działają zgodnie z zamysłem.
Kluczowe metryki
- Wskaźnik błędów: Procent instancji procesu, które trafiają do ścieżki błędu.
- Czas rozwiązywania: Ile czasu zajmuje odtworzenie po błędzie.
- Wskaźnik powodzenia ponownych prób: Jak często automatyczne ponowne próby rozwiązują problem.
Powiadomienia
Skonfiguruj powiadomienia dla krytycznych ścieżek błędów. Jeśli konkretny kod błędu gwałtownie wzrasta, oznacza to problem systemowy, który wymaga natychmiastowej uwagi. Nie traktuj wszystkich błędów jako równorzędnych; priorytetem powinny być te, które wpływają na przychód lub zgodność z przepisami.
📝 Podsumowanie najlepszych praktyk
Aby zapewnić odporność swoich przepływów biznesowych, przestrzegaj tych podstawowych zasad:
- Jawne modelowanie: Nigdy nie zakładaj, że błąd zostanie obsłużony przez silnik. Zdefiniuj go na diagramie.
- Dokładne obsługę: Używaj konkretnych kodów błędów, aby skierować do odpowiedniego obsługującego.
- Uwaga na dane: Zachowuj dane kontekstowe podczas awarii w celu audytu i debugowania.
- Kompensacja: Przygotuj się na cofnięcie działań, gdy będzie to konieczne.
- Testowanie: Weryfikuj ścieżki błędów z taką samą starannością, jak główny przepływ.
Inwestując czas w modelowanie wyjątków, budujesz procesy, które są nie tylko wydajne, ale także odporności. Dobrze obsłużony błąd często jest lepszy niż żaden błąd, ponieważ utrzymuje zaufanie i przejrzystość w systemie. Skup się na przejrzystości, precyzji i gotowości operacyjnej w swoich modelach BPMN.
🔗 Następne kroki w implementacji
Zacznij od audytu istniejących procesów. Zidentyfikuj zadania o wysokim ryzyku, gdzie niepowodzenie byłoby kosztowne. Najpierw zamodeluj zdarzenia graniczne dla tych zadań. Stopniowo rozszerzaj na zdarzenia pośrednie i logikę kompensacji. Ten krok po kroku podejście zapewnia stabilność, jednocześnie poprawiając odporność systemu.
Zdokumentuj strategię obsługi błędów. Stwórz przewodnik referencyjny dla programistów i analityków, który wyjaśnia kody błędów i oczekiwane zachowania. Ta dokumentacja staje się kluczowym aktywem do utrzymania procesu w długiej perspektywie.
Pamiętaj, celem nie jest całkowite usunięcie błędów, ale skuteczne zarządzanie nimi. Gdy jasno zamodelujesz ścieżki błędów, nadajesz systemowi możliwość spokojnego odbudowania i utrzymania działalności przedsiębiorstwa.

