






ソフトウェア開発およびプロダクトマネジメントの急速な環境において、スクラムフレームワークはスピードと適応性を向上させるためにしばしば採用される。しかし、スプリントの反復サイクルが勢いを失い始めると、チームは大きな課題に直面する。停滞したスプリントは単なる遅延以上のものであり、プロセス、コミュニケーション、または範囲に関する根本的な問題を示唆している。締切が繰り返しずれると、チームの信頼は失われ、モチベーションが低下し、製品納品の価値も低下する。このガイドは、外部ツールやソフトウェアプラットフォームに依存せずに、これらの問題を診断し解決する包括的で権威あるアプローチを提供する。
スプリントの停滞に対処するには、反応的な対応から予防的なプロセス最適化へのシフトが必要である。これは、完了の定義(Definition of Done)の見直し、バックログの精査、役割が意図した通りに機能しているかの確認を含む。以下では、症状、根本原因、そしてアジャイルワークフローの速度と信頼性を回復させるための実行可能な戦略を詳しく説明する。
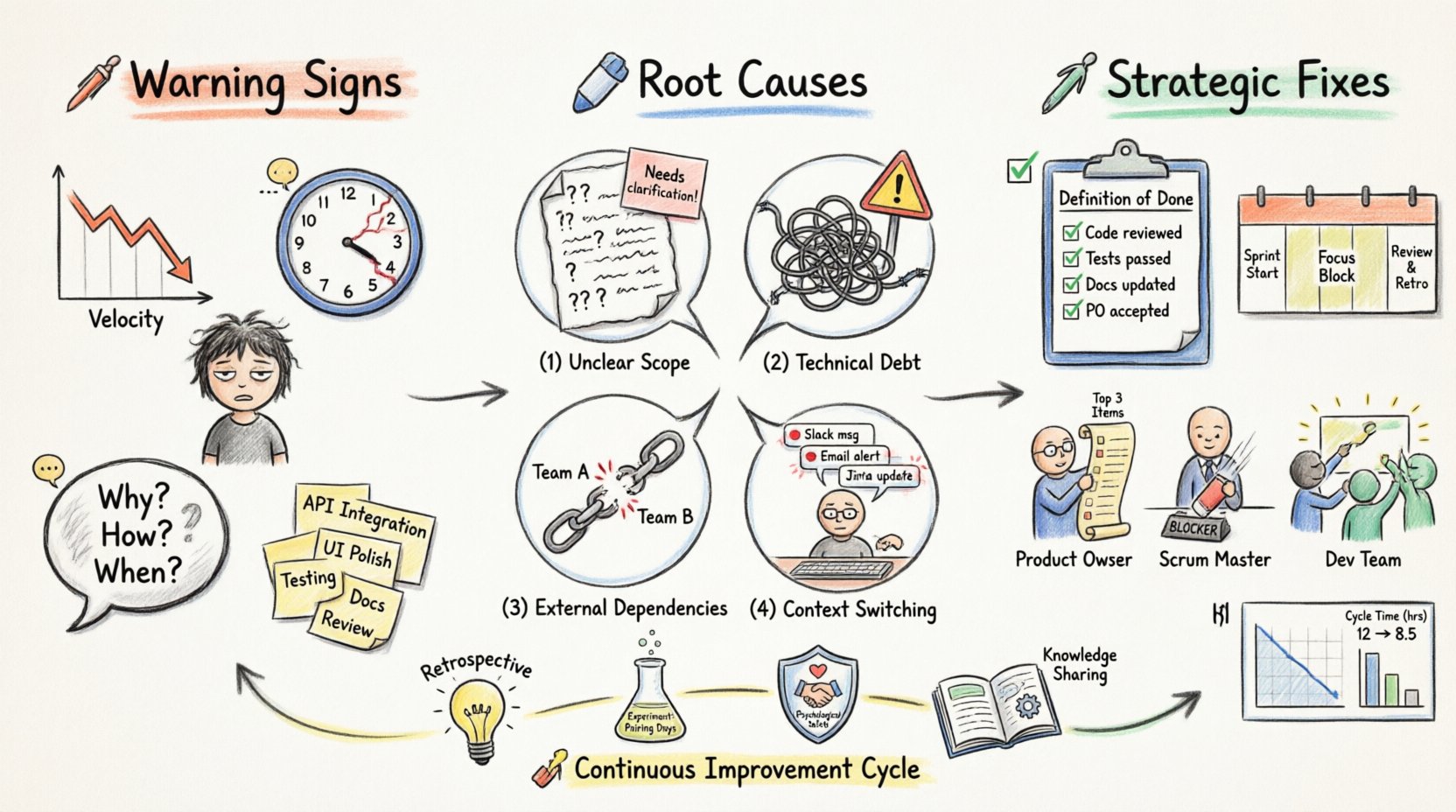
停滞したスプリントの兆候を認識する 📉
問題を修正する前に、正確にその原因を特定する必要がある。停滞は一夜にして起こることはない。多くの場合、計画された作業と完了した作業の間のギャップが徐々に広がる緩やかな流れである。チームは、未完了の項目を抱えたスプリントレビューが到来するまで、自分が苦戦していることに気づかないことがある。以下の具体的な兆候に注目しよう:
- 継続的な約束の不履行: チームがスプリント計画で約束した項目を、20%以上の頻度で完了できない。
- ゼロベロシティ日: 「進行中」から「完了」に新しい作業が進まない日が続く。
- 長時間化したデイリースタンドアップ: 会議が45分以上にわたって長引くことで、集中力の欠如や未解決のブロッカーが示唆される。
- 高い進行中作業数(WIP): 複数の項目が開始されるが、完成するのは少数で、ボトルネックを生じる。
- リトロスペクティブの疲労: 同じ問題が毎回リトロスペクティブで指摘され、プロセスに実質的な変化がない。
これらの症状を理解することで、一時的な困難と構造的な失敗の違いを明確にできる。以下の表は、健全なスプリントサイクルと停滞したスプリントを比較し、違いを明確にする。
| 指標 | 健全なスプリント | 停滞したスプリント |
|---|---|---|
| ベロシティの傾向 | 安定またはゆっくり増加 | 予測不能または減少 |
| ブロッカーの解決 | 24時間以内に解決 | 数週間放置されたまま |
| チームのモチベーション | 高い関与度と自信 | エネルギー不足、会議の回避 |
| 完了の定義 | 厳密に遵守されている | 無視されたり、一貫性なく適用されたり |
| ステークホルダーからのフィードバック | 定期的で実行可能な | 遅延または重大な |
スプリント停滞の一般的な根本原因 🔍
スプリントが停滞する原因は、ほとんどが単一の要因によるものではない。通常は、計画ミス、技術的負債、チームのダイナミクスの複合的な要因である。永続的な解決策を講じるためには、具体的な根本原因を特定することが不可欠である。
1. 明確でないまたは誇張された範囲
最も頻繁な原因の一つは、スプリント計画の段階で過剰な作業を抱え込むことである。プロダクトオーナーが明確な受入基準を提供しない場合、開発者は貴重な時間を要件の推測に費やす。これにより再作業や遅延が生じる。さらに、バックログの精査が事前に行われていないと、計画会議中に細部の議論に時間を費やし、作業のコミットに集中できなくなる。
- 症状:ストーリーが「進行中」に移動するが、決して完了しない。
- 影響:チームが能力を正確に見積もりできなくなるため、ベロシティが低下する。
- 修正:計画の前に厳格な「バックログ精査」セッションを実施する。すべてのストーリーが明確な「準備完了定義」を持っていることを確認する。
2. 技術的負債の蓄積
チームが納期を守るために新機能の開発にのみ注力すると、しばしば基盤となるコードの品質を無視してしまう。時間とともに、この負債は重い荷物となる。バグが増加し、システムは脆くなる。新しい機能を修正するには、悪質なコードの層をかき分ける必要があり、開発が著しく遅れる。
- 症状:新しい機能の構築よりも、バグの修正に多くの時間が割かれる。
- 影響:品質が低下し、テストに必要な時間が増加する。
- 修正:スプリントの能力の特定割合(例:20%)を技術的改善および負債削減に割り当てる。
3. 外部依存関係とブロッカー
チームは、直近のグループ外からの情報、リソース、承認を待って動けなくなることがよくある。別の部門がAPIアクセスやデザイン資産を提供する必要がある場合、その外部プロセスの遅延は、チームの進捗を完全に停止させる。これはチームのコントロール外に感じられ、よくある不満の原因である。
- 症状:作業項目が長期間にわたり「ブロッカー」状態のままになる。
- 影響:スプリントのバーンダウンチャートが平坦化し、進捗が見られない。
- 修正:スプリント開始前に依存関係を明確にし、毎日これらの外部タスクの追跡とブロッカー解除を担当する特定の責任者を割り当てる。
4. 注力の欠如とコンテキスト切り替え
アジャイルチームは生産的になるために深い作業が必要です。開発者が一日中会議や即時要請、サポートチケットに巻き込まれると、集中力が途切れます。コンテキストを切り替えるたびに、思考の流れを取り戻すのに時間がかかります。この断片化は、誰もすぐに気づかないまま生産性を奪います。
- 症状:会議への参加率は高いのに、出力は低い。
- 影響:誰も十分な中断のない時間を持てなかったため、スプリント目標を達成できなかった。
- 対策:会議が予定されていない「集中時間」を導入する。チームが緊急でない中断から守られるようにする。
プロセスのずれに対する戦略的対策 🛠️
根本原因が特定されたら、チームはプロセスを調整しなければなりません。フレームワークを変えるのではなく、チームの具体的な状況の中でスクラムの実装を最適化することです。
完了の定義(DoD)の見直し
完了の定義(DoD)は、ストーリーが実際に完了したかどうかを判断するチェックリストです。このリストが曖昧だと、テストされていないコードだけの状態でストーリーを完了とマークしてしまうことがあります。これにより、誤った進捗感が生じます。強固なDoDには、テスト、ドキュメント、コードレビュー、デプロイ準備が含まれるべきです。
- 見直し:チームが現在のDoDを見直す。難しすぎるのはないか?易しすぎるのはないか?
- 標準化:全員が「完了」とは何かに合意していることを確認する。ストーリーはユーザーの手に渡るか、リリース可能になるまで完了とは言えない。
- 可視化:すべてのタスクカードやボードにDoDを可視化し、『完了』に移動する前にチェックされていることを確認する。
スプリント期間の調整
標準的なスクラムでは2週間のスプリントを推奨しています。しかし、チームが常に過負荷状態にある場合は、短いスプリントの方がより良いフィードバックループを提供するかもしれません。逆に、チームが小さすぎて安定する時間が要る場合は、長いスプリントの方が計画の事務的負担を減らすかもしれません。目標は、燃え尽きることなく完了できるリズムを見つけることです。
- 短いスプリント:フィードバックの頻度を増やし、リスクを低減する。
- 長いスプリント:複雑な項目に対してより深い作業を可能にする。
- 一貫性:どの期間を選んでも、一貫して維持して予測可能なリズムを築く。
スプリント計画の改善
計画は多くのチームが間違えるポイントです。計画会議が急かされると、コミットメントに欠陥が生じます。チームはステークホルダーを喜ばせるためにすべてに「はい」と言ってしまう罠に陥りがちです。これにより失敗の原因が生まれます。計画は願望リストではなく、実際の能力に基づくべきです。
- 能力計画:スプリント中に休日、会議、休暇を考慮する。
- ストーリーの分割:大きなストーリーを、スプリント内で完了できる小さなテスト可能な単位に分割する。
- コミットメント vs. 予測:計画を予測として扱う。チームが100%の作業にコミットできない場合は、予期せぬ問題に対応できるよう80%を目標とする。
危機時の役割別責任 🎯
スクラムフレームワークにおける各役割は、チームが苦境に陥った際に明確な責任を持つ。責めるのではなく、明確さが解決策である。
プロダクトオーナー(PO)
POは製品の価値に対して責任を持つ。スプリントが停滞している場合は、正しい作業が行われているかを評価する必要がある。
- 再優先順位付け:低優先度の項目をスプリントから削除し、重要なパスに集中する。
- 明確化:開発者の停止を防ぐために、質問に即座に対応できる状態を保つ。
- ステークホルダーの管理:チームを外部のプレッシャーから守り、納期に関する期待を適切に管理する。
スクラムマスター(SM)
SMは障害の除去とプロセスの遵守を通じてチームを支援する。停滞したスプリントでは、通常よりも積極的に行動しなければならない。
- 調整:デイリースタンドアップが効果的で、障害に集中していることを確保する。
- コーチング:チームがコミットメントを果たせない理由を理解し、自己修正へ導く支援を行う。
- 保護:現在のバックログが未完了の間、チームが新しい作業を引き受けないようにする。
開発チーム
開発者は作業の品質と量に対して責任を持つ。プロセスを自らのものとしなければならない。
- 集中作業:サイロで作業するのではなく、チームメンバーは一つのアイテムを完了してから次の作業を始めるように協力する。
- 透明性:タスクが遅れる可能性がある場合は早期に認めること。悪いニュースを隠すと問題が悪化する。
- 同僚レビュー:欠陥が蓄積しないように、コードレビューを即座に実施する。
外部の依存関係と関係者を管理する 🤝
ときには停滞はチームの外側から来る。これらの外部要因を管理することは、前進を維持するために不可欠である。
- 依存関係のマッピング:スプリントに必要なすべての外部入力を視覚的にマップする。どの要素がリスクを伴うかを特定する。
- 定期的な確認:依存しているチームや部門と、短い同期をスケジュールする。スプリントレビューまで待って更新を求めるべきではない。
- バッファ時間:計画に余裕を持たせる。外部タスクが5日目に完了する場合、3日目までに利用可能になるように計画する。
- 上申経路:チームレベルでブロッカーが解決できない場合、誰に連絡すべきかを明確にする。単一のブロッカーが数週間もスプリント全体を停止させないよう注意する。
プレッシャーをかけずにメトリクスを活用する 📊
データは有用だが、チームを罰するために使われると損害を及ぼす可能性がある。メトリクスは個人を評価するためではなく、システムを理解するために使うべきである。
- ばらつき:時間の経過とともにベロシティを観察する。単一の低調なスプリントはノイズに過ぎないが、トレンドはシグナルである。
- バーンダウンチャート:チームが計画通りに進んでいるかを確認するために使用する。直線が平坦な場合、直ちに原因を調査する。
- サイクルタイム:アイテムが「進行中」から「完了」に移行するまでの時間を測定する。これが増加すれば、プロセスが遅くなっている証拠である。
- 欠陥率:リリース後に発見されたバグの数を追跡する。高い率は、作業が急がれていたり、テストが不十分だったりすることを示す。
継続的改善の文化を構築する 🌱
最終的な目標は、現在のスプリントを修正することだけでなく、将来の停滞を防ぐことである。そのためには、改善が常に継続され、心理的安全性が高い文化が必要となる。
- 効果的なリトロスペクティブ:リトロスペクティブは改善の原動力である。ただの不満の場にしてはならない。明確なアクションアイテム、責任者、期限を伴う結果を出すべきである。
- 実験:チームに小さなプロセスの変更を試すことを奨励する。変更が失敗した場合は、その理由を分析し、別の方法を試す。
- 心理的安全性:チームメンバーは、『分からない』や『ミスをした』と述べても、報復を恐れずに済む安心感を持つべきである。この誠実さはトラブルシューティングに不可欠である。
- 知識共有:一般的な問題の解決策を文書化する。これにより、チームが同じ壁に二度とぶつかるのを防ぐことができる。
いつパラメータを変更するか、または再スタートするか 🔄
現在のスプリントを回復できない場合がある。これは失敗ではなく、価値を守るために取られる戦略的判断である。
- 範囲の縮小: デッドラインが変更できない場合、最低優先度の項目を削除して、核心的な目標を達成することを確保する。
- スプリントのキャンセル: 市場の変化によりスプリントの目標が陳腐化した場合、プロダクトオーナーはスプリントをキャンセルできる。これによりチームはより価値のある作業に集中できる。
- リセット: チームが燃え尽きている場合、短い休止期間や、休息と計画に専念するスプリントが必要になることがある。
持続可能な納品についての最終的な考察 💡
停滞したスプリントは、あらゆるアジャイルな旅路において学びの過程の自然な一部である。避けようとするのではなく、そこから学ぶことが鍵である。原因を体系的に分析し、プロセスを調整し、オープンなコミュニケーションを維持することで、チームは再びリズムを取り戻すことができる。任意の日付を守ることよりも、継続的に価値を提供することに注力すべきである。プロセスがチームを支えるとき、チームは製品を支える。この調和こそが、成功したスクラムの実装の基盤である。
思い出そう。目標は持続可能なペースである。技術的負債を抱えたまま早期に終了するスプリントよりも、時間通りに高品質で終了するスプリントの方が良い。プロセスを信じ、チームを信じ、より良いパフォーマンスに向けて繰り返し改善を続けていこう。

