











現代のビジネス運営の文脈において、静的な図と動的なエンジンの違いは、しばしば基盤となるプロセスモデルの構造によって定義される。組織が手作業による実行から自動化されたワークフローへ移行する中で、ビジネスプロセスモデルと記法(BPMN)の基盤的アーキテクチャが極めて重要になる。本ガイドは、プロセスモデルが持続可能でスケーラブルであり、自動化技術に対応できる状態を保つために必要な構造的要件を概説する。
今日プロセスモデルを構築するには、明日への見通しが必要である。適切に構造化されたモデルは、単一の真実の源として機能し、人的意思決定とシステム実行の間のギャップを埋める。適切な構造化がなければ、自動化プロジェクトはしばしば統合層で頓挫し、高コストな再作業を余儀なくされる。以下のセクションでは、堅牢なプロセス定義を構築するために必要なアーキテクチャ原則、モデリング基準、ガバナンス戦略について詳述する。
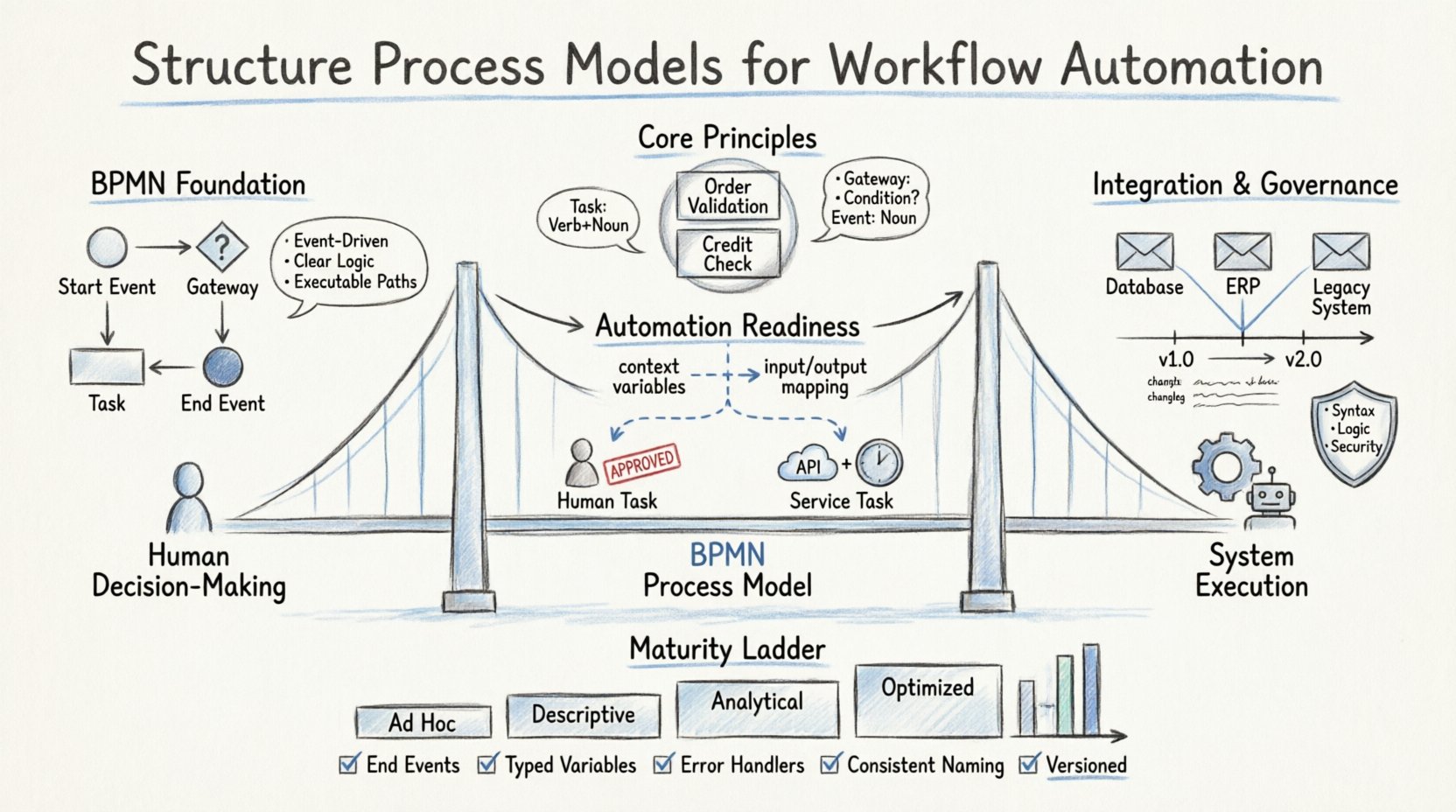
📐 基礎:BPMN標準の理解
BPMNはプロセス文書化の共通語として機能する。しかし、標準的な構文に従うことは第一歩に過ぎない。自動化を支援するためには、モデルが実行のルールを厳密に遵守しなければならない。これは、実行時エンジン内でイベント、ゲートウェイ、タスクがどのように相互作用するかを理解することを意味する。
- イベント駆動型アーキテクチャ:すべてのプロセスには明確な開始と終了が必要である。イベントがフローを開始する。自動化はこれらのトリガーに依存してアクションを開始する。
- 論理制御のためのゲートウェイ:ゲートウェイは実行経路を決定する。排他的ゲートウェイは2値の判断を処理し、並列ゲートウェイは並行処理を管理する。自動化エンジンはこれらを条件付きコードとして解釈する。
- タスクの種類:人間タスクにはユーザーインターフェースが必要である。サービスタスクは外部システムを起動する。メッセージタスクは非同期通信を処理する。
自動化を目的としたモデル作成において、明確さが最も重要である。モデル内の曖昧さはコード内の曖昧さを生む。すべての経路は実行可能でなければならない。死胡同や到達不能なループは、自動化ロジックを破壊する代表的なエラーである。
🚀 スケーラブルなモデリングのための核心原則
スケーラビリティとは単にボリュームを処理することだけではない。モデルが破綻することなく複雑性を扱えることが重要である。単一の取引に適していたプロセスは、数千件にスケーリングするとしばしば失敗する。構造的整合性により、負荷下でもロジックが健全であることが保証される。
1. モジュール型設計パターン
モノリシックな図を作成するのではなく、サブプロセスを使用して論理をカプセル化する。これにより可読性が向上し、チームが全体に影響を与えずに特定の領域に集中して作業できる。
- 再利用可能なサブプロセス:「注文検証」や「クレジットチェック」などの一般的な活動に対して、標準ブロックを作成する。
- 関心の分離:オーケストレーションのフローを、詳細な実装ロジックから分離する。
- インターフェースの一貫性:異なる親プロセス間で、サブプロセスの入力と出力が一貫していることを確認する。
2. 名前付け規則
一貫した名前付けは、開発者とビジネス関係者双方の認知負荷を軽減する。明確な名前付け規則により、監査やトラブルシューティング時の混乱を防ぐことができる。
| 要素の種類 | 名前付け規則 | 例 |
|---|---|---|
| プール/レーン | ビジネス役割またはシステム | カスタマーサービス、ERPシステム |
| タスク | 動詞+名詞(過去形または現在形) | 請求書承認、ユーザー検証 |
| イベント | 名詞(開始/終了) | 注文受領、支払い完了 |
| ゲートウェイ | 条件質問 | 金額は500以上ですか?在庫はありますか? |
🤖 自動化対応設計
自動化には特定のデータ構造と論理トリガーが必要です。手動レビュー用に設計されたプロセスモデルは、ロボット実行に必要なハックを欠いていることがよくあります。自動化に備えるためには、特定の設計調整が必要です。
1. データペイロード定義
自動化エンジンは、機能するために構造化されたデータを必要とします。モデル内のすべてのタスクは、特定のデータオブジェクトに関連付けるべきです。これにより、タスクがトリガーされた際に必要なコンテキストが確保されます。
- コンテキスト変数:プロセスレベルで、ライフサイクル全体にわたって保持される変数を定義する。
- 入力/出力マッピング:外部APIの応答を内部変数に明確にマッピングする。
- エラー処理:データが欠落している場合や無効な場合にどうするかを定義する。自動化は推測できない。明確に定義されたルールに従わなければならない。
2. ヒューマンとシステムの受け渡し
ヒューマン作業とシステム作業の明確な境界は、ボトルネックを防ぎます。タスクがヒューマンに割り当てられると、システムは待機します。サービスに割り当てられると、システムは進行します。
- サービスタスク:API呼び出し、データベース更新、ファイル処理に使用する。
- ユーザー作業:承認、データ入力、複雑な判断判断に使用する。
- タイマーイベント:SLAの遵守や繰り返しの自動チェックのトリガーに使用する。
🔗 データフローと統合ポイント
プロセスは真空状態に存在するものではない。さまざまなシステムと相互作用する。データ整合性を確保するため、モデルはこれらの統合ポイントを明示的に表現しなければならない。図面に接続が欠けていることは、生産環境でパイプラインが破損する原因となることが多い。
1. 外部参照
プロセスが外部システムとやり取りする場合、そのやり取りをメッセージまたはサービスタスクとしてモデル化する。これを抽象化してはならない。統合ロジックはプロセスフローの一部である。
- 同期呼び出し: プロセスは続行する前に応答を待つ。
- 非同期呼び出し: プロセスは続行し、コールバックイベントを待機する。
- ファイルインターフェース: ファイルのドロップやアップロードをイベントまたはタスクとして表現する。
2. 状態管理
長時間実行されるプロセスでは、状態の維持が重要である。モデルはプロセスのライフサイクルにおける位置を追跡しなければならない。これにより、システム障害が発生した場合の回復が可能になる。
| シナリオ | モデル化アプローチ | 自動化の影響 |
|---|---|---|
| システムクラッシュ | トランザクション境界 | エンジンは最後のチェックポイントから再開しなければならない |
| タイムアウト | タイマー中間イベント | 再試行ロジックまたはエスカレーションをトリガーする |
| 例外 | エラー境界イベント | エラーはプロセスレベルではなく、タスクレベルでキャッチする |
🛡️ 治理とバージョン管理戦略
プロセスが進化するにつれて、モデルもそれに合わせて進化しなければならない。ガバナンスにより、変更が制御され、文書化される。バージョン管理がなければ、本番環境で現在実行されているロジックを追跡することは不可能である。
1. バージョン管理
プロセスモデルへのすべての変更は、新しいバージョンを作成するべきである。これにより、プロセス変更のA/Bテストとロールバックが可能になる。
- バージョン番号: 意味的バージョン管理(メジャーバージョン.マイナーバージョン.パッチ)を使用する。
- 非推奨ポリシー: 古いバージョンが非推奨になるタイミングを定義する。
- ドキュメント: モデルメタデータ内に変更履歴を含める。
2. 検証ルール
モデルをデプロイする前に、検証チェックを通過しなければならない。これにより、モデルが文法的に正しく、論理的に整合していることが保証される。
- 構文チェック: すべての接続が有効ですか?すべての要素に名前が付けられていますか?
- 論理チェック: 無限ループはありますか?すべてのパスがカバーされていますか?
- セキュリティチェック: 敏感なデータポイントは保護されていますか?
🚫 避けるべき一般的な落とし穴
経験豊富なモデラーでも構造上の弱点を導入してしまうことがある。これらの落とし穴を早期に認識することで、実装フェーズでの時間を大幅に節約できる。
- 過剰設計: 主要フローにすべてのエッジケースをモデル化しないでください。例外にはエラーハンドラーを使用する。
- ハードコードされた値: 特定の値(日付やIDなど)をモデルに直接埋め込まないでください。代わりに変数を使用する。
- エラー経路の欠如: すべてのタスクには失敗時の明確な経路が必要である。自動化は回復方法を知らなければならない。
- 複雑なゲートウェイ: 過度にネストされたゲートウェイは論理のデバッグを難しくする。可能な限り条件を簡略化する。
📊 モデルの健全性を測る
プロセスが稼働し始めると、モデル自体が指標となる。実行データを分析することで構造的な非効率を特定できる。このフィードバックループにより、時間とともにプロセス定義を改善できる。
- 実行時間: 特定のタスクが予想よりも長くかかっているでしょうか?これは最適化の必要性を示している可能性がある。
- ボトルネックの特定: プロセスはどこで止まるか?ゲートウェイや人的タスクは一般的な混雑ポイントである。
- 経路の頻度: 特定の分岐がほとんど使われていないか?これは不要な複雑さを示している可能性がある。
🔍 プロセスモデリングの成熟度レベル
組織はモデリング成熟度の異なる段階を経て進展する。現在の段階を理解することで、自動化の準備度に関する現実的な目標を設定できる。
| レベル | 特徴 | 自動化可能性 |
|---|---|---|
| レベル1:臨時対応 | 非公式な図式、標準表記なし。 | なし。完全な再設計が必要。 |
| レベル2:記述的 | BPMN表記を使用しているが、論理が不明瞭。 | 低。大幅な整理作業が必要。 |
| レベル3:分析的 | 明確な論理、定義されたデータフロー、エラー処理。 | 中程度。基本的なサービスに備えている。 |
| レベル4:最適化済み | モジュール化され、バージョン管理され、統制され、監視されている。 | 高。複雑なオーケストレーションに備えている。 |
🧩 実装チェックリスト
プロセスモデルを自動化環境にデプロイする前に、このチェックリストを確認して構造的整合性を確保してください。
- ✅ すべての経路が終了イベントに到達していますか?
- ✅ すべての変数が正しく定義され、型が適切に設定されていますか?
- ✅ エラー境界イベントがサービスタスクに接続されていますか?
- ✅ インテグレーションポイントが明確にラベル付けされていますか?
- ✅ 図式全体で命名規則が一貫していますか?
- ✅ 複雑さを管理するためにサブプロセスが使用されていますか?
- ✅ モデルはバージョン管理され、文書化されていますか?
- ✅ すべてのビジネスルールがゲートウェイまたはスクリプトに変換されていますか?
🔄 持続的改善
プロセスモデリングは一度きりの活動ではありません。設計、実行、分析の継続的なサイクルです。ビジネス要件が変化するにつれて、モデルもそれに適応しなければなりません。今日構築する構造は、完全な再構築なしに将来の変化に対応できるようにするべきです。
モジュール性、明確なデータフロー、BPMN標準への厳密な準拠に注力することで、現在も将来も自動化を支える基盤を構築できます。目的は、何が起こるかを記録することではなく、機械が理解し、信頼性高く実行できるように、どう起こるべきかを定義することです。
基本から始めましょう。フローが論理的であることを確認してください。データを追加し、エラーを定義してから、自動化を行いましょう。この規律あるアプローチにより、最も安定性が高く、保守性の高いワークフローソリューションが得られます。

