











ビジネスプロセスはほとんどが線形ではない。現実世界では、データが不完全であり、システムがオフラインになることもあり、人的判断も異なる。ビジネスプロセスモデルと記法(BPMN)を使ってワークフローをモデル化する際、すべてが常に成功すると仮定するのは、本番環境での失敗を招く原因となる。例外処理とエラー経路はオプションの機能ではなく、耐障害性のあるプロセスアーキテクチャの基盤となる要素である。このガイドでは、プロセスモデル内でエラーマネジメントを効果的に構造化する方法を詳述する。
🛑 BPMNにおける例外処理の重要性
明確なエラー経路が定義されていないプロセスモデルは不完全である。それは「ハッピーパス」、つまりすべてのステップが完璧に成功するシナリオを記述しているだけである。しかし、運用上の現実ははるかに複雑である。ライブ環境でタスクが失敗した場合、ワークフローエンジンは、どのように反応すべきかを明確な指示で受け取る必要がある。明確なモデル化がなければ:
- 停止したインスタンス:プロセスが、決して解決しない条件を待って無期限に停止する可能性がある。
- データ損失:フローが突然終了した場合、重要な情報が破棄される可能性がある。
- 運用上の盲点:チームが、どのエラーが重大なもので、どのエラーが警告であるかを把握できない場合がある。
- 手動介入:ユーザーは、構造化された復旧計画がなければ、失敗したインスタンスを手動で再起動させられる可能性がある。
例外を明確にモデル化することで、脆弱なスクリプトを堅牢なシステムに変えることができる。このアプローチにより、問題が発生した際に、システムが何をすべきか、誰に通知すべきか、結果をどのように記録すべきかを正確に把握できるようになる。
🧩 BPMNのエラーイベントタイプの理解
BPMN 2.0は、失敗を表現するための特定の要素を提供している。これらの要素の違いを理解することは、正確なモデル化にとって不可欠である。エラーは単なる「停止」ではなく、特定の行動をトリガーするイベントである。
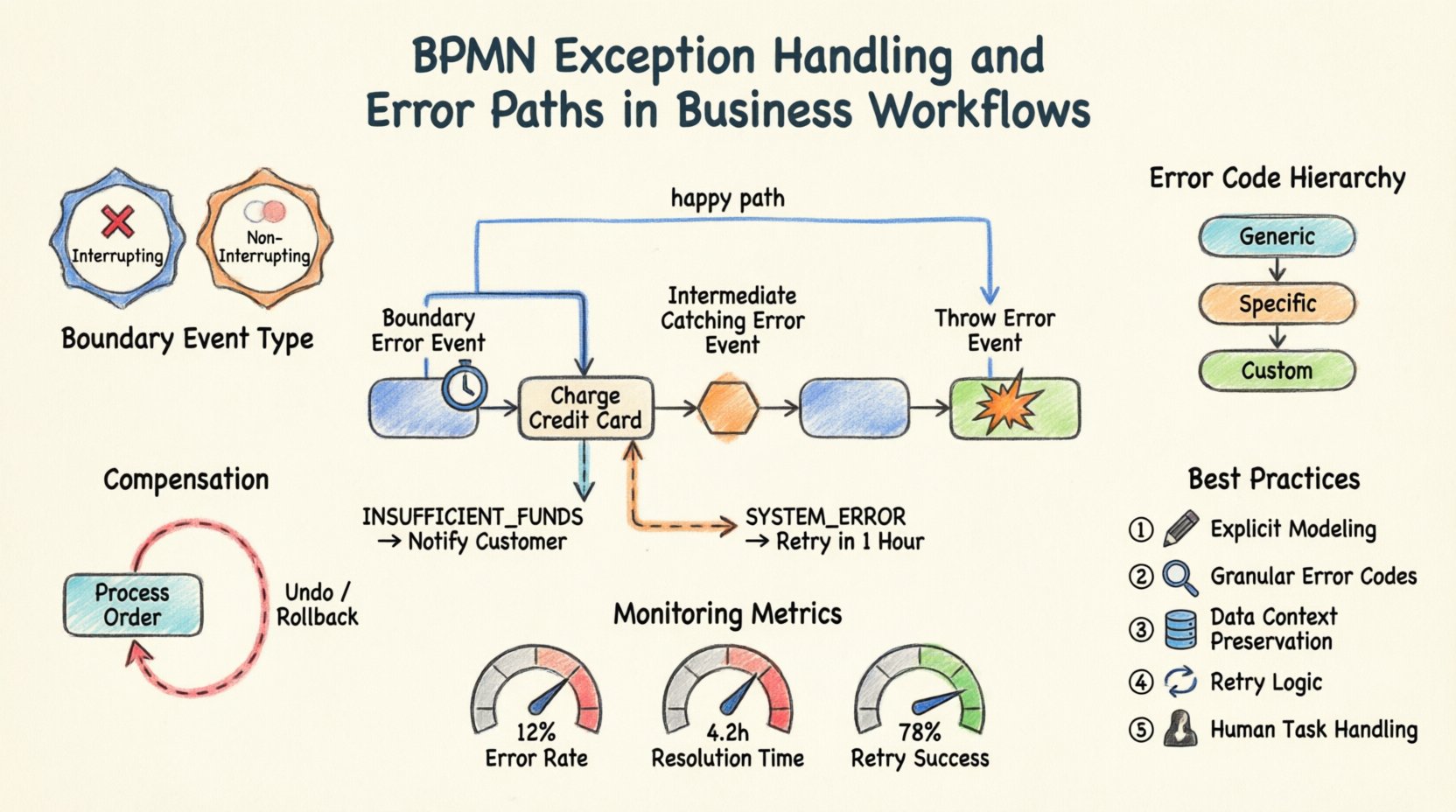
1. バウンダリー・エラーイベント ⏱️
バウンダリー・エラーイベントは、アクティビティ(タスクまたはサブプロセス)の境界に接続される。これは、そのアクティビティの実行中に発生する失敗を表す。実行中そのアクティビティの実行中に発生する。アクティビティがエラーを送出すると、フローはバウンダリー・イベントに分岐し、メインプロセスのフローを過度に中断することなく、即座に処理できる。
- 使用例: 支払いタスクがタイムアウトにより失敗した。バウンダリー・イベントがこれをキャッチし、支払いを再試行するか、ユーザーに通知することができる。
- 動作: メインアクティビティは、続行または停止を設定できる。継続する場合、バウンダリー・イベントは並行パスをトリガーする。
2. 中間受信エラーイベント 🛑
これらのイベントはプロセスのフロー内に位置し、アクティビティの境界に接続されていない。以前のアクティビティまたは上流プロセスによって送出されたエラーをキャッチする。シーケンスフロー内のチェックポイントとして機能する。
- 使用例: 検証ステップの連続の後、中間エラーイベントが、履行ステージに進む前に検証失敗をキャッチする。
- 動作: プロセスは、このイベントで一時停止し、エラーが処理されるまで待機した後、次のステップに進む。
3. エラー送出イベント 💥
これらのイベントは、アクティビティ内でエラーが発生したことを示すために使用されます。これらは例外の発生源です。アクティビティは、通常の完了ではなくエラーをスローする特定の条件を定義できます。
- 使用例: サービス統合タスクが 500 Internal Server Error を検出し、特定のエラートークンをスローします。
- 動作: エラーは、最も近い境界エラーイベントまたは中間キャッチングエラーイベントまで伝播されます。
⚙️ 深掘り:境界エラーイベント
境界エラーイベントは、BPMNにおけるエラー処理で最も一般的なツールです。メインプロセスフローを整理したまま、局所的に例外を管理できます。
構成オプション
タスクに境界エラーイベントをアタッチする際には、特定の動作を定義する必要があります:
- 中断型 vs. 非中断型:
- 中断型: メインタスクは直ちに停止されます。タスクに対してさらなる作業は行われません。
- 非中断型: タスクはバックグラウンドで継続して実行されます。エラーハンドラーパスは並行して実行されます。作業を停止せずにログ記録や通知を行う場合に便利です。
- エラー定義: エラーコードを指定する必要があります。これにより、異なる境界イベントが異なる種類のエラーをキャッチできるようになります(例:「PAYMENT_TIMEOUT」と「PAYMENT_DECLINED」)。
実践的なシナリオ:決済ゲートウェイ
注文処理のプロセスを検討してください。「クレジットカードを請求する」というタスクがこのフローの中心となります。
- メインパス: 成功した場合、プロセスは「注文を発送する」に移行します。
- エラーパス: 「クレジットカードを請求する」に境界エラーイベントをアタッチします。
- ロジック: エラーコードが「INSUFFICIENT_FUNDS」の場合、フローは「顧客に通知する」に移行します。
- ロジック: エラーコードが「SYSTEM_ERROR」の場合、フローは「1時間後に再試行する」に移行します。
この構造により、プロセスのクラッシュを防ぎます。失敗の具体的な性質に基づいて、ユーザーを適切な解決パスにルーティングします。
🔄 中間エラーイベントと伝播
すべてのエラーが発生源で即座にキャッチされるわけではありません。場合によっては、エラーがプロセス階層の上位に伝播する必要があります。中間キャッチングエラーイベントがこれを容易にします。
サブプロセスのエラー処理
埋め込みサブプロセスを使用する場合、サブプロセス内で発生するエラーは2つの方法で処理できます:
- 内部処理: エラーは境界イベントを使用してサブプロセス内で捕捉されます。サブプロセスは親にエラーをスローせずに通常通り完了(または特定の完了状態で)します。
- 外部伝播: エラーはサブプロセスから送出されます。親プロセスはサブプロセス自体の境界イベント、またはメインフロー内の中間エラーイベントを使用してそれらを捕捉します。
エラーコードと階層構造
伝播を効果的に管理するため、エラーコードの階層を定義してください:
- 汎用エラー:予期せぬシステム障害のための万能イベント。
- 特定エラー:既知のビジネスロジック障害のためのイベント(例:「無効な住所」)。
- カスタムコード:統合レイヤーで定義された特定のコード。
特定のコードを使用することで、正しいハンドラがトリガーされることを保証します。汎用の万能ハンドラは最終手段であり、最初の選択肢にしてはいけません。
💸 コンペンセーションとロールバック戦略
場合によっては、一連のアクションがすでに完了した後にエラーが発見されることがあります。このような場合、単にプロセスを停止するだけでは不十分です。変更を元に戻す必要があるかもしれません。これがコンペンセーションイベントが役立つ場面です。
コンペンセーションとは何ですか?
コンペンセーションとは、完了したアクティビティを元に戻す行為です。これはエラー処理とは異なり、成功後に次のステップで失敗が発生した後の結果に対処するものです。
- 使用例: フライトの予約は成功しましたが、ホテルの予約が失敗しました。料金を回避するために、フライトの予約をキャンセルしなければなりません。
- モデリング: 原則的なアクティビティに関連付けられたコンペンセーションアクティビティを定義します。
コンペンセーションを使用するタイミング
以下の状況ではコンペンセーションイベントを使用してください:
- プロセスが長時間実行される場合。
- 外部システムを簡単にロールバックできない場合。
- 複数ステップにわたってデータ整合性を維持しなければならない場合。
コンペンセーションがなければ、プロセスモデルは記録システムに孤立したレコードや整合性の取れない状態を残すことになります。
📊 エラー処理の比較マトリクス
さまざまなエラー処理メカニズムの違いを明確にするために、この構造化された比較を参照してください。
| 要素 | 場所 | トリガー | 主な使用ケース |
|---|---|---|---|
| 境界エラーイベント | タスクに付随 | タスクの失敗 | 即時再試行またはユーザーへの通知 |
| 中間エラーイベント | フロー内 | 上流エラー | タスクの連続処理後にエラーをキャッチ |
| エラーイベントを送出 | タスク内 | 論理条件 | 上流のハンドラに失敗を通知 |
| 補償イベント | 完了したタスクに関連 | 後続の失敗 | 以前のアクションを元に戻す(ロールバック) |
🗂️ エラー発生時のデータコンテキストの管理
エラーが発生したとき、データの状態は非常に重要です。エラーが発生したという事実だけでは、多くの場合不十分です。あなたはなぜそして何どのデータが原因だったのかを知る必要があります。
エラー変数
BPMNエンジンでは、エラー処理に変数を渡すことができます。モデルが以下の情報をキャプチャしていることを確認してください:
- エラーコード: 標準化された識別子(例:「ERR_101」)
- エラーメッセージ:ログ用の読みやすい説明。
- コンテキストデータ:トラブルシューティングを支援するための関連ビジネスデータ(例:注文ID、顧客名)。
データの永続化
エラー発生前に収集されたデータが永続化されていることを確認してください。一時的なメモリに頼ってはいけません。プロセスインスタンスがエラーにより停止した場合、次のインスタンスが同じデータコンテキストにアクセスでき、処理を再開できるようにしなければなりません。
🧪 エラー経路のテストと検証
エラー経路のモデリングは作業の半分にすぎません。実行環境で正しく動作することを確認する必要があります。エラー経路のテストは、正常経路のテストとは異なるマインドセットを必要とします。
検証チェックリスト ✅
- 到達不能なロジック:エラー経路がデッドロックや到達不能なノードを生成しないように確認してください。
- カバレッジ:すべての潜在的な障害ポイントに、対応するエラー処理が存在することを確認してください。
- タイムアウト:タスクの時間制限を超えた場合に何が起こるかをテストしてください。
- 統合障害:境界イベントがトリガーされるか確認するために、APIのダウンタイムをシミュレートしてください。
- データ整合性:ロールバック後に部分的なデータが残っていないことを確認してください。
シミュレーションツール
プロセスシミュレーションツールを使用してワークフローに障害を注入してください。これにより、本番データに影響を与えずに、プロセスがストレス下でどのように振る舞うかを観察できます。以下の点を確認してください:
- 予期しないプロセスの終了。
- 誤ったエラーメッセージがログに記録されている。
- 適切なステークホルダーに通知が行われない。
🚧 避けるべき一般的な落とし穴
経験豊富なモデラーでさえ、エラー処理を設計する際にミスを犯すことがあります。これらの一般的な罠に注意してください。
1. 「ハッピーパス」を無視する
メインフローにエラー処理のロジックを混入しないでください。メインフローを明確に保ってください。境界イベントやサブプロセスを使用してエラー処理のロジックを分離してください。これにより、モデルの可読性と保守性が向上します。
2. 境界イベントの過剰使用
すべてのタスクに境界イベントを付けると、図が複雑でわかりにくくなります。失敗が重大な影響を及ぼす、または特定の処理ロジックが必要なタスクにのみ境界イベントを付けるようにしてください。
3. 不明確なエラーメッセージ
「何らかの問題が発生しました」といった一般的なエラーメッセージを避けてください。開発者やビジネスユーザーが理解できる具体的なコードとメッセージを使用してください。これにより、問題の迅速な解決が可能になります。
4. リトライロジックの欠如
一時的なエラー(ネットワークの不具合など)はリトライすべきです。タイマーまたはループを使用して、明示的にリトライメカニズムをモデル化してください。一時的なエラーが恒久的な失敗にならないようにしてください。
5. ヒューマンタスクの忘れ去り
ヒューマンタスクも失敗します。ユーザーがタスクを無視する、または無効なデータを入力する可能性があります。ヒューマンタスクが放棄されたり拒否された場合にどうするかを定義してください。これは、システムタスクとは異なるエラーパスを必要とする場合が多いです。
🔍 モニタリングと運用準備状態
プロセスが本番稼働した後、エラーパスが最初の防御ラインになります。これらのパスが意図した通りに機能していることを確認するために、モニタリングは不可欠です。
重要な指標
- エラー率: エラーパスに到達するプロセスインスタンスの割合。
- 回復時間: エラーからの回復にかかる時間。
- リトライ成功確率: 自動リトライが問題を解決する頻度。
アラート
重要なエラーパスに対してアラートを設定してください。特定のエラーコードが急増した場合、システム全体に影響する問題が発生している可能性があり、直ちに対応が必要です。すべてのエラーを同等に扱わないでください。収益やコンプライアンスに影響するエラーを優先してください。
📝 最良の実践方法の要約
ビジネスワークフローの耐障害性を確保するため、以下の基本原則に従ってください:
- 明示的なモデル化: エンジンがエラーを処理すると仮定してはいけません。図に明確に定義してください。
- 細粒度の処理: 具体的なエラーコードを使用して、正しいハンドラにルーティングしてください。
- データの認識: オーディットやデバッグのために、障害発生時もコンテキストデータを保持してください。
- 補償: 必要に応じて、アクションを元に戻すための計画を立ててください。
- テスト: メインフローと同様に、エラーパスを徹底的に検証してください。
例外をモデル化する時間に投資することで、効率的であるだけでなく、堅牢なプロセスを構築できます。適切に処理されたエラーは、システム内の信頼性と明確性を維持するため、エラーが全くない状態よりも良い場合があります。BPMNモデルにおいて、明確さ、正確さ、運用準備状態に注力してください。
🔗 実装の次のステップ
まず、既存のプロセスを監査してください。失敗するとコストがかかる高リスクのタスクを特定します。これらのタスクに対して境界イベントを最初にモデル化します。段階的に中間イベントおよび補償ロジックへと拡張していきます。この段階的なアプローチにより、安定性を確保しながら耐障害性を向上させます。
エラー処理戦略を文書化してください。開発者やアナリスト向けのリファレンスガイドを作成し、エラーコードと期待される動作を説明します。この文書は、プロセスを長期的に維持する上で重要な資産になります。
思い出してください。目的はエラーを完全に排除することではなく、効果的に管理することです。エラー経路を明確にモデル化することで、システムがスムーズに回復できるようにし、ビジネスが前進し続けるようにできます。

