











Dans le paysage des opérations commerciales modernes, la distinction entre un diagramme statique et un moteur dynamique est souvent définie par la structure du modèle de processus sous-jacent. Alors que les organisations passent de l’exécution manuelle à des flux de travail automatisés, l’architecture fondamentale du modèle de processus et de notation (BPMN) devient cruciale. Ce guide décrit les exigences structurelles nécessaires pour garantir que les modèles de processus restent viables, évolutifs et prêts aux technologies d’automatisation.
Construire un modèle de processus aujourd’hui exige une vision d’avenir. Un modèle bien structuré agit comme une source unique de vérité, comblant l’écart entre la prise de décision humaine et l’exécution système. Sans une structuration adéquate, les initiatives d’automatisation stagne souvent au niveau de l’intégration, nécessitant des reprises coûteuses. Les sections suivantes détaillent les principes architecturaux, les normes de modélisation et les stratégies de gouvernance nécessaires pour créer des définitions de processus robustes.
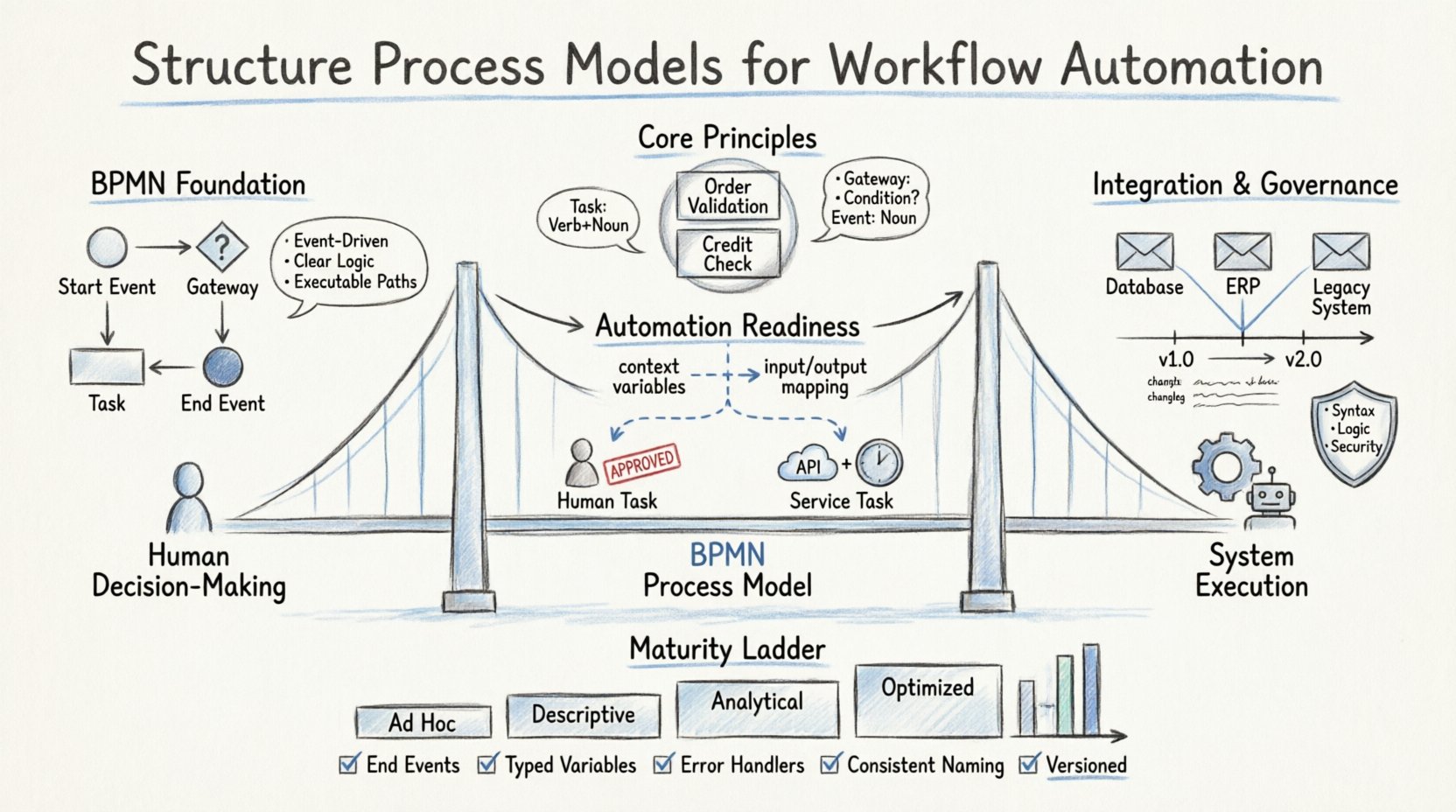
📐 La fondation : Comprendre les normes BPMN
BPMN sert de langue commune pour la documentation des processus. Toutefois, respecter la syntaxe standard n’est que le premier pas. Pour soutenir l’automatisation, le modèle doit strictement suivre les règles d’exécution. Cela signifie comprendre comment les événements, les passerelles et les tâches interagissent au sein d’un moteur d’exécution.
- Architecture pilotée par les événements : Chaque processus doit avoir un début et une fin clairs. Les événements déclenchent le flux. Les automatisations reposent sur ces déclencheurs pour initier des actions.
- Passerelles pour la logique : Les passerelles déterminent le chemin d’exécution. Les passerelles exclusives gèrent les décisions binaires, tandis que les passerelles parallèles gèrent la concurrence. Les moteurs d’automatisation les interprètent comme du code conditionnel.
- Types de tâches : Les tâches humaines nécessitent des interfaces utilisateur. Les tâches de service déclenchent des systèmes externes. Les tâches de message gèrent la communication asynchrone.
Lors de la modélisation pour l’automatisation, la clarté est primordiale. L’ambiguïté dans le modèle entraîne une ambiguïté dans le code. Chaque chemin doit être exécutable. Les culs-de-sac et les boucles inaccessibles sont des erreurs courantes qui rompent la logique d’automatisation.
🚀 Principes fondamentaux pour une modélisation évolutives
L’évolutivité ne concerne pas seulement la gestion du volume ; elle consiste à gérer la complexité sans casser le modèle. Un processus fonctionnant pour une seule transaction échoue souvent lorsqu’il est étendu à des milliers d’opérations. L’intégrité structurelle garantit que la logique reste solide sous charge.
1. Modèles de conception modulaires
Au lieu de créer des diagrammes monolithiques, utilisez des sous-processus pour encapsuler la logique. Cela améliore la lisibilité et permet aux équipes de travailler sur des zones spécifiques sans affecter l’ensemble.
- Sous-processus réutilisables : Créez des blocs standards pour des activités courantes telles que « Validation de commande » ou « Vérification de crédit ».
- Séparation des préoccupations : Maintenez le flux d’orchestration séparé de la logique d’implémentation détaillée.
- Consistance des interfaces : Assurez-vous que les entrées et sorties des sous-processus restent cohérentes à travers différents processus parents.
2. Conventions de nommage
Un nommage cohérent réduit la charge cognitive pour les développeurs et les parties prenantes métiers. Une convention de nommage claire évite toute confusion lors des audits ou des dépannages.
| Type d’élément | Convention de nommage | Exemple |
|---|---|---|
| Pool/Lane | Rôle métier ou système | Service client, Système ERP |
| Tâche | Verbe + Nom (Passé ou Présent) | Approuver la facture, valider l’utilisateur |
| Événement | Nom (Début/Fin) | Commande reçue, paiement effectué |
| Passerelle | Question de condition | Le montant est-il supérieur à 500 ? Le stock est-il disponible ? |
🤖 Conception pour la préparation à l’automatisation
L’automatisation nécessite des structures de données spécifiques et des déclencheurs logiques. Un modèle de processus conçu pour une revue manuelle manque souvent des points d’ancrage nécessaires pour une exécution robotique. Pour préparer les modèles à l’automatisation, des ajustements de conception spécifiques sont requis.
1. Définition du chargement de données
Les moteurs d’automatisation nécessitent des données structurées pour fonctionner. Chaque tâche du modèle doit être associée à des objets de données spécifiques. Cela garantit que lorsque la tâche est déclenchée, le contexte nécessaire est disponible.
- Variables de contexte : Définir des variables au niveau du processus qui persistent tout au long du cycle de vie.
- Mappage Entrée/Sortie : Mapper clairement les réponses des API externes aux variables internes.
- Gestion des erreurs : Définir ce qui se produit lorsque les données sont manquantes ou non valides. L’automatisation ne peut pas deviner ; elle doit suivre des règles définies.
2. Transferts humains versus systèmes
Des frontières claires entre le travail humain et le travail système empêchent les goulets d’étranglement. Lorsqu’une tâche est attribuée à un humain, le système attend. Lorsqu’elle est attribuée à un service, le système continue.
- Tâches de service : Utilisez-les pour les appels d’API, les mises à jour de base de données et le traitement de fichiers.
- Tâches utilisateur : Utilisez-les pour les approbations, la saisie de données et les décisions complexes.
- Événements de minuterie : Utilisez-les pour imposer les SLA ou déclencher des vérifications automatisées récurrentes.
🔗 Flux de données et points d’intégration
Les processus n’existent pas dans le vide. Ils interagissent avec divers systèmes. Le modèle doit représenter explicitement ces points d’intégration pour garantir l’intégrité des données. Une connexion manquante dans le diagramme entraîne souvent une pipeline cassée en production.
1. Références externes
Lorsqu’un processus interagit avec un système externe, modélisez cette interaction sous forme de message ou de tâche de service. Ne l’abstrayez pas. La logique d’intégration fait partie du flux du processus.
- Appels synchrones : Le processus attend une réponse avant de continuer.
- Appels asynchrones : Le processus continue et écoute un événement de rappel.
- Interfaces de fichiers : Représentez les dépôts ou téléchargements de fichiers sous forme d’événements ou de tâches.
2. Gestion d’état
Le maintien de l’état est crucial pour les processus longs. Le modèle doit suivre l’état du processus dans son cycle de vie. Cela permet une récupération en cas de défaillance du système.
| Scénario | Approche de modélisation | Implication de l’automatisation |
|---|---|---|
| Panne du système | Frontières des transactions | Le moteur doit reprendre à partir du dernier point de contrôle |
| Délai d’attente dépassé | Événements intermédiaires temporisés | Déclencher la logique de réessai ou l’escalade |
| Exception | Événements aux limites des erreurs | Gérer les erreurs au niveau de la tâche, et non au niveau du processus |
🛡️ Stratégies de gouvernance et de gestion des versions
Au fur et à mesure que les processus évoluent, les modèles doivent évoluer avec eux. La gouvernance assure que les modifications sont contrôlées et documentées. Sans gestion des versions, il est impossible de savoir quelle logique est actuellement en cours d’exécution en production.
1. Contrôle de version
Chaque modification apportée au modèle de processus doit créer une nouvelle version. Cela permet de tester les modifications de processus en mode A/B et de disposer de fonctionnalités de retour en arrière.
- Numéros de version : Utilisez la version sémantique (Majeur.Mineur.Patch).
- Politiques de dépréciation : Définissez quand les anciennes versions sont abandonnées.
- Documentation :Inclure les journaux de modifications dans les métadonnées du modèle.
2. Règles de validation
Avant qu’un modèle ne soit déployé, il doit passer des vérifications de validation. Cela garantit que le modèle est correct sur le plan syntaxique et logique.
- Vérification syntaxique :Toutes les connexions sont-elles valides ? Tous les éléments sont-ils nommés ?
- Vérification logique :Y a-t-il des boucles infinies ? Toutes les voies sont-elles couvertes ?
- Vérification de sécurité :Les points de données sensibles sont-ils protégés ?
🚫 Pièges courants à éviter
Même les modélisateurs expérimentés peuvent introduire des faiblesses structurelles. Reconnaître ces pièges tôt permet d’économiser un temps considérable pendant la phase de mise en œuvre.
- Surconception :Ne pas modéliser chaque cas limite dans le flux principal. Utilisez des gestionnaires d’erreurs pour les exceptions.
- Valeurs codées en dur :Évitez d’incorporer directement des valeurs spécifiques (comme des dates ou des identifiants) dans le modèle. Utilisez des variables à la place.
- Absence de chemins d’erreur :Chaque tâche doit avoir un chemin défini en cas d’échec. L’automatisation doit savoir comment se rétablir.
- Passerelles complexes :Trop de passerelles imbriquées rendent la logique difficile à déboguer. Simplifiez les conditions lorsque c’est possible.
📊 Mesure de la santé du modèle
Dès qu’un processus est actif, le modèle lui-même devient un indicateur. Vous pouvez analyser les données d’exécution pour identifier des inefficacités structurelles. Cette boucle de retour permet d’affiner progressivement la définition du processus.
- Temps d’exécution :Certaines tâches prennent-elles plus de temps que prévu ? Cela pourrait indiquer un besoin d’optimisation.
- Identification des goulets d’étranglement :Où les processus s’arrêtent-ils ? Les passerelles ou les tâches humaines sont des points critiques fréquents.
- Fréquence des chemins :Certains chemins sont-ils rarement empruntés ? Cela pourrait indiquer une complexité inutile.
🔍 Niveaux de maturité en modélisation des processus
Les organisations évoluent à travers différentes étapes de maturité en modélisation. Comprendre votre niveau actuel aide à fixer des objectifs réalistes pour la préparation à l’automatisation.
| Niveau | Caractéristiques | Potentiel d’automatisation |
|---|---|---|
| Niveau 1 : Ad hoc | Schémas informels, pas de notation standard. | Aucun. Nécessite une refonte complète. |
| Niveau 2 : Descriptif | Notation BPMN utilisée, mais la logique est floue. | Faible. Nécessite un nettoyage important. |
| Niveau 3 : Analytique | Logique claire, flux de données définis, gestion des erreurs. | Moyen. Prêt pour des services de base. |
| Niveau 4 : Optimisé | Modulaire, versionné, contrôlé et surveillé. | Élevé. Prêt pour une orchestration complexe. |
🧩 Liste de contrôle de mise en œuvre
Avant de déployer un modèle de processus dans un environnement d’automatisation, passez en revue cette liste de contrôle pour garantir l’intégrité structurelle.
- ✅ Chaque chemin mène-t-il à un événement de fin ?
- ✅ Toutes les variables sont-elles définies et typées correctement ?
- ✅ Les événements limites d’erreur sont-ils associés aux tâches de service ?
- ✅ Les points d’intégration sont-ils clairement étiquetés ?
- ✅ La convention de nommage est-elle cohérente sur tout le schéma ?
- ✅ Les sous-processus sont-ils utilisés pour gérer la complexité ?
- ✅ Le modèle est-il versionné et documenté ?
- ✅ Toutes les règles métier ont-elles été traduites en passerelles ou en scripts ?
🔄 Amélioration continue
La modélisation des processus n’est pas une activité ponctuelle. C’est un cycle continu de conception, d’exécution et d’analyse. À mesure que les exigences métier évoluent, les modèles doivent s’adapter. La structure que vous construisez aujourd’hui doit pouvoir accueillir ces évolutions futures sans nécessiter une refonte complète.
En vous concentrant sur la modularité, les flux de données clairs et le respect strict des normes BPMN, vous créez une base qui soutient l’automatisation aujourd’hui et à l’avenir. L’objectif n’est pas seulement de documenter ce qui se passe, mais de définir comment cela devrait se produire de manière que les machines puissent le comprendre et l’exécuter de façon fiable.
Commencez par les bases. Assurez-vous que le flux est logique. Ajoutez les données. Définissez les erreurs. Ensuite, automatiser. Cette approche rigoureuse produit les solutions de flux de travail les plus stables et les plus maintenables.

