











Les processus métiers sont rarement linéaires. Dans le monde réel, les données sont incomplètes, les systèmes tombent en panne et le jugement humain varie. En modélisant des flux de travail à l’aide du Business Process Model and Notation (BPMN), supposer que tout réussira toujours est une recette de défaillance en production. La gestion des exceptions et les chemins d’erreur ne sont pas des fonctionnalités facultatives ; ce sont des composants fondamentaux d’une architecture de processus résiliente. Ce guide détaille comment structurer efficacement la gestion des erreurs au sein de vos modèles de processus.
🛑 Pourquoi la gestion des exceptions est-elle importante dans BPMN
Un modèle de processus sans chemins d’erreur définis est incomplet. Il décrit le « chemin heureux » — la situation où chaque étape réussit parfaitement. Toutefois, la réalité opérationnelle est bien plus complexe. Lorsqu’une tâche échoue dans un environnement en production, le moteur de flux de travail a besoin d’instructions explicites sur la manière de réagir. Sans modélisation claire :
- Instances bloquées :Les processus peuvent rester bloqués indéfiniment, en attendant une condition qui ne sera jamais résolue.
- Perte de données :Des informations critiques pourraient être perdues si le flux se termine brusquement.
- Points aveugles opérationnels :Les équipes ne savent pas toujours si une erreur est critique ou simplement un avertissement.
- Intervention manuelle :Les utilisateurs pourraient être obligés de redémarrer manuellement les instances défaillantes sans plan de récupération structuré.
En modélisant explicitement les exceptions, vous transformez un script fragile en un système robuste. Cette approche garantit que lorsque quelque chose va mal, le système sait exactement quoi faire, à qui notifier et comment enregistrer le résultat.
🧩 Comprendre les types d’événements d’erreur BPMN
BPMN 2.0 fournit des éléments spécifiques pour représenter les échecs. Comprendre la distinction entre ces éléments est crucial pour une modélisation précise. Les erreurs ne sont pas simplement des « arrêts » ; ce sont des événements qui déclenchent des comportements spécifiques.
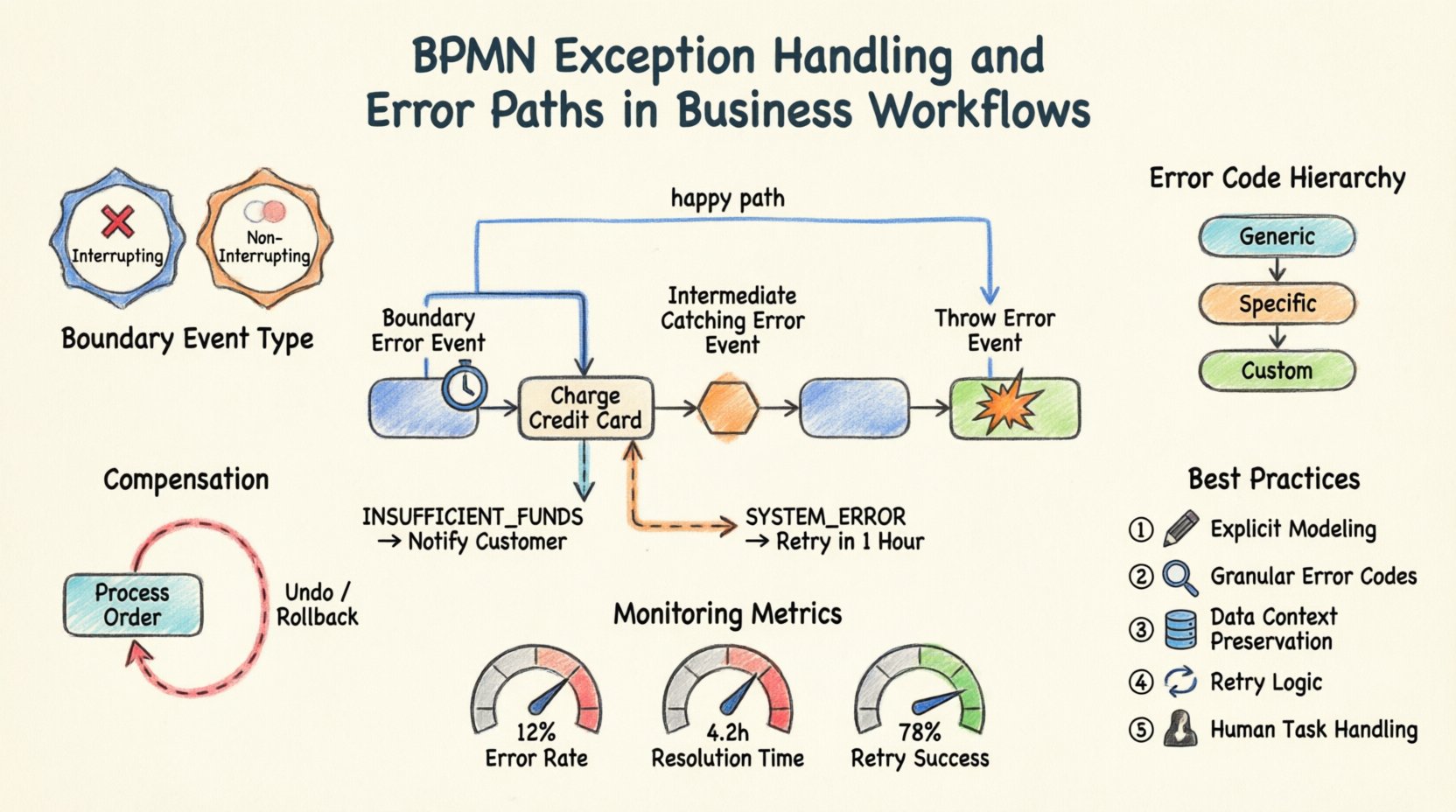
1. Événements d’erreur à la limite ⏱️
Un événement d’erreur à la limite est attaché à la limite d’une activité (tâche ou sous-processus). Il représente une erreur survenue pendant l’exécution de cette activité. Lorsque l’activité lance une erreur, le flux est redirigé vers l’événement à la limite, permettant une gestion immédiate sans interrompre prématurément le flux principal du processus.
- Cas d’utilisation : Une tâche de paiement échoue en raison d’un timeout. L’événement à la limite le détecte, permettant de réessayer le paiement ou d’avertir l’utilisateur.
- Comportement : L’activité principale peut être configurée pour continuer ou s’arrêter. Si elle continue, l’événement à la limite déclenche un chemin parallèle.
2. Événements d’erreur intermédiaires de capture 🛑
Ces événements se situent dans le flux d’un processus, sans être attachés à la limite d’une activité. Ils captent une erreur lancée par une activité précédente ou un processus amont. Ils agissent comme un point de contrôle dans le flux de séquence.
- Cas d’utilisation : Après une série d’étapes de validation, un événement d’erreur intermédiaire détecte un échec de validation avant de passer à l’étape de traitement.
- Comportement : Le processus s’arrête à cet événement jusqu’à ce que l’erreur soit traitée, puis passe à l’étape suivante.
3. Événements de lancement d’erreur 💥
Ces événements sont utilisés au sein d’une activité pour signaler qu’une erreur s’est produite. Ils sont à l’origine de l’exception. Une activité peut définir une condition spécifique dans laquelle elle lance une erreur au lieu de se terminer normalement.
- Cas d’utilisation :Une tâche d’intégration de service détecte une erreur 500 Serveur interne et lance un jeton d’erreur spécifique.
- Comportement :Il propage l’erreur jusqu’à l’événement d’erreur à la limite le plus proche ou à l’événement d’erreur intermédiaire de capture.
⚙️ Approfondissement : Événements d’erreur à la limite
Les événements d’erreur à la limite sont l’outil le plus courant pour gérer les erreurs dans BPMN. Ils vous permettent de maintenir le flux principal du processus propre tout en gérant les exceptions localement.
Options de configuration
Lorsque vous attachez un événement d’erreur à la limite à une tâche, vous devez définir des comportements spécifiques :
- Interrompre vs. Ne pas interrompre :
- Interrompre :La tâche principale est arrêtée immédiatement. Aucun autre travail n’est effectué sur la tâche.
- Ne pas interrompre :La tâche continue de s’exécuter en arrière-plan. Le chemin de gestion des erreurs s’exécute en parallèle. Cela est utile pour la journalisation ou la notification sans interrompre le travail.
- Définition de l’erreur :Vous devez préciser le code d’erreur. Cela permet à différents événements à la limite de capturer différents types d’erreurs (par exemple, « PAYMENT_TIMEOUT » vs « PAYMENT_DECLINED »).
Scénario pratique : La passerelle de paiement
Pensez à un processus de traitement d’une commande. Une tâche appelée « Débiter la carte de crédit » est centrale dans ce flux.
- Chemin principal :Si elle réussit, le processus passe à « Expédier la commande ».
- Chemin d’erreur :Attachez un événement d’erreur à la limite à « Débiter la carte de crédit ».
- Logique :Si le code d’erreur est « INSUFFICIENT_FUNDS », le flux va vers « Aviser le client ».
- Logique :Si le code d’erreur est « SYSTEM_ERROR », le flux va vers « Réessayer dans 1 heure ».
Cette structure empêche le processus de planter. Elle redirige l’utilisateur vers le chemin de résolution approprié en fonction de la nature spécifique de l’échec.
🔄 Événements d’erreur intermédiaires et propagation
Toutes les erreurs ne sont pas capturées immédiatement à la source. Parfois, les erreurs doivent remonter dans la hiérarchie du processus. Les événements d’erreur intermédiaires de capture facilitent cela.
Gestion des erreurs dans les sous-processus
Lorsqu’on utilise un sous-processus intégré, les erreurs survenant à l’intérieur du sous-processus peuvent être gérées de deux manières :
- Gestion interne :Les erreurs sont capturées à l’intérieur du sous-processus à l’aide d’événements de limite. Le sous-processus se termine normalement (ou dans un état de complétion spécifique) sans lever d’erreur vers le processus parent.
- Propagation externe :Les erreurs sont levées en dehors du sous-processus. Le processus parent les capture à l’aide d’un événement de limite sur le sous-processus lui-même ou d’un événement d’erreur intermédiaire dans le flux principal.
Codes d’erreur et hiérarchie
Pour gérer efficacement la propagation, définissez une hiérarchie de codes d’erreur :
- Erreurs génériques :Événements d’attente générale pour les défaillances système imprévues.
- Erreurs spécifiques :Événements pour les échecs connus de la logique métier (par exemple, « Adresse non valide »).
- Codes personnalisés :Codes spécifiques définis par votre couche d’intégration.
L’utilisation de codes spécifiques garantit que le gestionnaire approprié est déclenché. Un gestionnaire générique d’attente générale ne doit être utilisé qu’en dernier recours, et non en premier.
💸 Stratégies de compensation et d’annulation
Parfois, une erreur est découverte après qu’une série d’actions se soit déjà terminée. Dans ces cas, il ne suffit pas de simplement arrêter le processus. Vous devrez peut-être annuler les modifications. C’est là que les événements de compensation entrent en jeu.
Qu’est-ce que la compensation ?
La compensation est l’acte d’inverser une activité terminée. Elle se distingue de la gestion des erreurs car elle traite les conséquences d’un succès suivi d’une échec dans une étape ultérieure.
- Cas d’utilisation :Vous avez réussi à réserver un vol, mais la réservation d’hôtel échoue. La réservation du vol doit être annulée afin d’éviter des frais.
- Modélisation :Vous définissez une activité de compensation liée à l’activité d’origine.
Quand utiliser la compensation
Utilisez les événements de compensation lorsque :
- Le processus est long à exécuter.
- Les systèmes externes ne peuvent pas être facilement annulés.
- L’intégrité des données doit être maintenue sur plusieurs étapes.
Sans compensation, votre modèle de processus laisse des enregistrements orphelins ou des états incohérents dans le système d’origine.
📊 Matrice de comparaison des gestion des erreurs
Pour clarifier les différences entre divers mécanismes de gestion des erreurs, reportez-vous à cette comparaison structurée.
| Élément | Emplacement | Déclencheur | Cas d’utilisation principal |
|---|---|---|---|
| Événement d’erreur à la limite | Attaché à une tâche | Échec de la tâche | Réessai immédiat ou notification de l’utilisateur |
| Événement d’erreur intermédiaire | Dans le flux | Erreur en amont | Capturer les erreurs après une séquence de tâches |
| Lancer un événement d’erreur | À l’intérieur de la tâche | Condition logique | Signaler l’échec aux gestionnaires en amont |
| Événement de compensation | Lié à une tâche terminée | Échec ultérieur | Annuler les actions précédentes (retour arrière) |
🗂️ Gestion du contexte des données lors des erreurs
Lorsqu’une erreur se produit, l’état des données est crucial. Savoir simplement qu’une erreur s’est produite est souvent insuffisant. Vous devez savoir pourquoietquoi des données ont causé cela.
Variables d’erreur
Les moteurs BPMN vous permettent de passer des variables aux gestionnaires d’erreurs. Assurez-vous que votre modèle capture :
- Code d’erreur : Un identifiant standardisé (par exemple, « ERR_101 »).
- Message d’erreur : Une description lisible par l’humain destinée aux journaux d’activité.
- Données de contexte : Données commerciales pertinentes (par exemple, ID de commande, nom du client) pour faciliter le dépannage.
Persistance des données
Assurez-vous que les données collectées avant l’erreur sont conservées. Ne comptez pas sur la mémoire temporaire. Si une instance de processus s’arrête en raison d’une erreur, la prochaine instance doit avoir accès au même contexte de données pour reprendre le traitement.
🧪 Tests et validation des chemins d’erreur
Modéliser les chemins d’erreur n’est que la moitié du travail. Vous devez vérifier qu’ils fonctionnent correctement dans l’environnement d’exécution. Tester les chemins d’erreur nécessite une mentalité différente de celle utilisée pour tester les chemins normaux.
Liste de contrôle de validation ✅
- Logique inatteignable : Assurez-vous que les chemins d’erreur ne créent pas de blocages ou de nœuds inaccessibles.
- Couverture : Vérifiez que chaque point potentiel de défaillance dispose d’un gestionnaire d’erreur correspondant.
- Délais d’attente : Testez ce qui se produit lorsque une tâche dépasse sa limite de temps.
- Échec d’intégration : Simulez une indisponibilité de l’API pour vous assurer que l’événement limite est déclenché.
- Intégrité des données : Confirmez qu’aucune donnée partielle n’est laissée derrière après un retour arrière.
Outils de simulation
Utilisez des outils de simulation de processus pour injecter des erreurs dans le flux de travail. Cela vous permet d’observer le comportement du processus sous charge sans affecter les données de production. Recherchez :
- Terminaison inattendue du processus.
- Messages d’erreur incorrects enregistrés dans les journaux.
- Échec de la notification des parties prenantes concernées.
🚧 Pièges courants à éviter
Même les modélisateurs expérimentés commettent des erreurs lors de la conception de la gestion des erreurs. Soyez attentif à ces pièges courants.
1. Ignorer le « chemin normal »
Ne pas encombrer le flux principal avec la logique de gestion des erreurs. Gardez le flux principal propre. Utilisez des événements limites et des sous-processus pour isoler la logique d’erreur. Cela rend le modèle plus facile à lire et à maintenir.
2. Surutilisation des événements limites
Attacher un événement limite à chaque tâche individuelle peut rendre le diagramme désordonné et confus. Attachez-les uniquement aux tâches où l’échec a un impact significatif ou nécessite une logique de traitement spécifique.
3. Messages d’erreur vagues
Évitez les messages d’erreur génériques comme « Quelque chose s’est mal passé ». Utilisez des codes et des messages précis que les développeurs et les utilisateurs métiers peuvent comprendre. Cela facilite une résolution plus rapide.
4. Absence de logique de réessai
Les erreurs temporaires (comme les perturbations réseau) doivent être réessayées. Modélisez les mécanismes de réessai de manière explicite en utilisant des temporisateurs ou des boucles. Ne laissez pas une erreur temporaire devenir une erreur permanente.
5. Oublier les tâches humaines
Les tâches humaines échouent également. Un utilisateur peut ignorer une tâche ou saisir des données non valides. Définissez ce qui se produit si une tâche humaine est abandonnée ou rejetée. Cela nécessite souvent un chemin d’erreur différent de celui des tâches système.
🔍 Surveillance et préparation opérationnelle
Une fois le processus en production, les chemins d’erreur deviennent votre première ligne de défense. La surveillance est essentielle pour garantir que ces chemins fonctionnent comme prévu.
Indicateurs clés
- Taux d’erreur : Le pourcentage des instances de processus qui atteignent un chemin d’erreur.
- Temps de résolution : Le temps nécessaire pour se remettre d’une erreur.
- Taux de réussite du réessai : Avec quelle fréquence les réessais automatiques résolvent le problème.
Alertes
Configurez des alertes pour les chemins d’erreur critiques. Si un code d’erreur spécifique augmente soudainement, cela indique un problème systémique qui nécessite une attention immédiate. Ne traitez pas toutes les erreurs de la même manière ; priorisez celles qui ont un impact sur les revenus ou la conformité.
📝 Résumé des meilleures pratiques
Pour garantir que vos flux de travail métiers soient résilients, respectez ces principes fondamentaux :
- Modélisation explicite : Ne supposez jamais qu’une erreur sera traitée par le moteur. Définissez-la dans le diagramme.
- Gestion fine : Utilisez des codes d’erreur spécifiques pour acheminer vers le gestionnaire approprié.
- Connaissance des données : Préservez les données de contexte en cas d’échec pour l’audit et le débogage.
- Compensation : Prévoyez l’annulation des actions lorsque cela est nécessaire.
- Tests : Validez les chemins d’erreur avec autant de rigueur que le flux principal.
En investissant du temps à modéliser les exceptions, vous construisez des processus qui sont non seulement efficaces mais aussi robustes. Une erreur bien gérée est souvent préférable à l’absence d’erreur, car elle maintient la confiance et la clarté dans le système. Concentrez-vous sur la clarté, la précision et la préparation opérationnelle dans vos modèles BPMN.
🔗 Étapes suivantes pour la mise en œuvre
Commencez par auditer vos processus existants. Identifiez les tâches à haut risque où un échec serait coûteux. Modélisez d’abord les événements limites pour ces tâches. Puis étendez progressivement à des événements intermédiaires et à la logique de compensation. Cette approche par étapes garantit la stabilité tout en améliorant la résilience.
Documentez votre stratégie de gestion des erreurs. Créez un guide de référence pour les développeurs et les analystes qui explique les codes d’erreur et les comportements attendus. Cette documentation devient un atout essentiel pour maintenir le processus dans le temps.
Souvenez-vous, l’objectif n’est pas d’éliminer les erreurs, mais de les gérer efficacement. Lorsque vous modélisez clairement les chemins d’erreur, vous donnez à système la capacité de se rétablir de manière fluide et de maintenir l’activité métier.

