











Los procesos empresariales rara vez son lineales. En el mundo real, los datos son incompletos, los sistemas se desconectan y la juventud humana varía. Al modelar flujos de trabajo utilizando el Modelo y Notación de Procesos de Negocios (BPMN), asumir que todo siempre tendrá éxito es una receta para el fracaso en producción. El manejo de excepciones y las rutas de error no son características opcionales; son componentes fundamentales de una arquitectura de proceso resiliente. Esta guía detalla cómo estructurar eficazmente la gestión de errores dentro de tus modelos de proceso.
🛑 ¿Por qué el manejo de excepciones es importante en BPMN
Un modelo de proceso sin rutas de error definidas es incompleto. Describe la «ruta feliz»: el escenario en el que cada paso tiene éxito perfectamente. Sin embargo, la realidad operativa es mucho más compleja. Cuando una tarea falla en un entorno en vivo, el motor de flujo de trabajo necesita instrucciones explícitas sobre cómo reaccionar. Sin una modelización clara:
- Instancias bloqueadas:Los procesos pueden quedar detenidos indefinidamente, esperando una condición que nunca se resuelve.
- Pérdida de datos:La información crítica podría descartarse si el flujo se interrumpe bruscamente.
- Puntos ciegos operativos:Los equipos pueden no saber cuáles errores son críticos frente a cuáles son advertencias.
- Intervención manual:Los usuarios podrían verse obligados a reiniciar manualmente las instancias fallidas sin un plan estructurado de recuperación.
Al modelar explícitamente las excepciones, transformas un script frágil en un sistema robusto. Este enfoque garantiza que cuando algo salga mal, el sistema sepa exactamente qué hacer, a quién notificar y cómo registrar el resultado.
🧩 Comprender los tipos de eventos de error en BPMN
BPMN 2.0 proporciona elementos específicos para representar fallas. Comprender la diferencia entre estos elementos es crucial para una modelización precisa. Los errores no son simplemente «paradas»; son eventos que desencadenan comportamientos específicos.
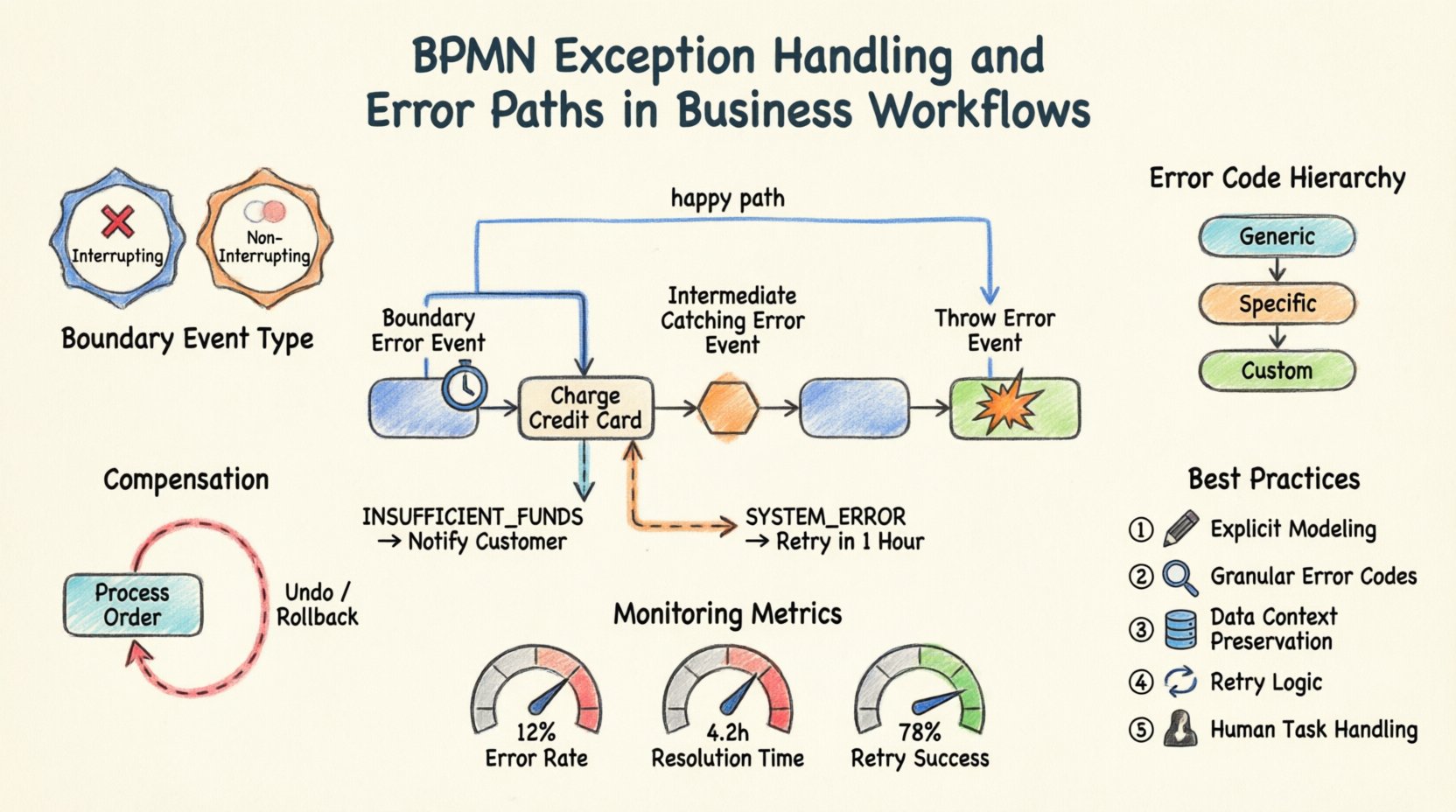
1. Eventos de error en el borde ⏱️
Un evento de error en el borde está unido al borde de una actividad (tarea o subproceso). Representa un fallo que ocurre durante la ejecución de esa actividad. Cuando la actividad lanza un error, el flujo se desvía hacia el evento en el borde, permitiendo una gestión inmediata sin interrumpir prematuramente el flujo principal del proceso.
- Caso de uso: Una tarea de pago falla debido a un tiempo de espera agotado. El evento en el borde lo captura, permitiéndote reintentar el pago o notificar al usuario.
- Comportamiento: La actividad principal se puede configurar para continuar o detenerse. Si continúa, el evento en el borde desencadena una ruta paralela.
2. Eventos intermedios de captura de error 🛑
Estos eventos se sitúan dentro del flujo de un proceso, no unidos al borde de una actividad. Capturan un error que ha sido lanzado por una actividad anterior o un proceso superior. Actúan como un punto de control en el flujo de secuencia.
- Caso de uso:Tras una serie de pasos de validación, un evento de error intermedio captura un fallo de validación antes de proceder a la etapa de cumplimiento.
- Comportamiento: El proceso se detiene en este evento hasta que se maneje el error, y luego pasa al siguiente paso.
3. Eventos de lanzamiento de error 💥
Estos eventos se utilizan dentro de una actividad para indicar que se ha producido un error. Son la fuente de la excepción. Una actividad puede definir una condición específica bajo la cual lanza un error en lugar de completarse normalmente.
- Casos de uso:Una tarea de integración de servicio detecta un error 500 de servidor interno y lanza un token de error específico.
- Comportamiento:Propaga el error hasta el evento de error de borde más cercano o el evento de error intermedio que captura.
⚙️ Análisis profundo: Eventos de error de borde
Los eventos de error de borde son la herramienta más común para manejar errores en BPMN. Permiten mantener el flujo principal del proceso limpio mientras gestionan las excepciones localmente.
Opciones de configuración
Al adjuntar un evento de error de borde a una tarea, debe definir comportamientos específicos:
- Interrumpir frente a no interrumpir:
- Interrumpir:La tarea principal se detiene inmediatamente. No se realiza más trabajo en la tarea.
- No interrumpir:La tarea continúa ejecutándose en segundo plano. La ruta de manejo de errores se ejecuta en paralelo. Esto es útil para registro o notificación sin detener el trabajo.
- Definición de error:Debe especificar el código de error. Esto permite que diferentes eventos de borde capturen tipos diferentes de errores (por ejemplo, “PAYMENT_TIMEOUT” frente a “PAYMENT_DECLINED”).
Escenario práctico: La pasarela de pagos
Considere un proceso para procesar un pedido. Una tarea llamada “Cobrar tarjeta de crédito” es central en este flujo.
- Ruta principal:Si tiene éxito, el proceso pasa a “Enviar pedido”.
- Ruta de error:Adjunte un evento de error de borde a “Cobrar tarjeta de crédito”.
- Lógica:Si el código de error es “INSUFFICIENT_FUNDS”, el flujo va a “Notificar al cliente”.
- Lógica:Si el código de error es “SYSTEM_ERROR”, el flujo va a “Reintentar en 1 hora”.
Esta estructura evita que el proceso se bloquee. Dirige al usuario a la ruta de resolución correcta según la naturaleza específica del fallo.
🔄 Eventos de error intermedios y propagación
No todos los errores se capturan inmediatamente en la fuente. A veces, los errores deben propagarse hacia arriba en la jerarquía del proceso. Los eventos de error intermedios facilitan esto.
Manejo de errores en subprocesos
Al utilizar un subproceso incrustado, los errores que ocurren dentro del subproceso pueden manejarse de dos formas:
- Manejo interno:Los errores se capturan dentro del subproceso utilizando eventos de borde. El subproceso finaliza normalmente (o con un estado de finalización específico) sin lanzar un error al proceso principal.
- Propagación externa:Los errores se lanzan fuera del subproceso. El proceso principal los captura utilizando un evento de borde en el propio subproceso o un evento de error intermedio en el flujo principal.
Códigos de error y jerarquía
Para gestionar la propagación de forma efectiva, define una jerarquía de códigos de error:
- Errores genéricos:Eventos de captura total para fallas inesperadas del sistema.
- Errores específicos:Eventos para fallas conocidas en la lógica de negocio (por ejemplo, «Dirección inválida»).
- Códigos personalizados:Códigos específicos definidos por tu capa de integración.
El uso de códigos específicos garantiza que se active el manejador adecuado. Una captura genérica total debería ser el último recurso, no el primero.
💸 Estrategias de compensación y reversión
A veces, un error se descubre después de que una serie de acciones ya se hayan completado. En estos casos, simplemente detener el proceso no es suficiente. Es posible que necesites deshacer cambios. Es aquí donde entran en juego los eventos de compensación.
¿Qué es la compensación?
La compensación es la acción de revertir una actividad completada. Es distinta del manejo de errores porque aborda las consecuencias de un éxito seguido de un fracaso en un paso posterior.
- Casos de uso:Reservaste con éxito un vuelo, pero la reserva del hotel falla. La reserva del vuelo debe cancelarse para evitar cargos.
- Modelado:Definir una actividad de compensación vinculada a la actividad original.
Cuándo usar la compensación
Usa eventos de compensación cuando:
- El proceso es de larga duración.
- Los sistemas externos no pueden revertirse fácilmente.
- La integridad de los datos debe mantenerse a través de múltiples pasos.
Sin compensación, tu modelo de proceso deja registros huérfanos o estados inconsistentes en el sistema de registro.
📊 Matriz de comparación de manejo de errores
Para aclarar las diferencias entre diversos mecanismos de manejo de errores, consulta esta comparación estructurada.
| Elemento | Ubicación | Disparador | Casos de uso principales |
|---|---|---|---|
| Evento de error en el borde | Adjunto a la tarea | Fallo de la tarea | Reintento inmediato o notificación al usuario |
| Evento de error intermedio | Dentro del flujo | Error de flujo ascendente | Capturar errores después de una secuencia de tareas |
| Evento de lanzamiento de error | Dentro de la tarea | Condición lógica | Indicar el fallo a los controladores de flujo ascendente |
| Evento de compensación | Vinculado a una tarea completada | Fallo posterior | Deshacer acciones anteriores (reversión) |
🗂️ Gestión del contexto de datos durante los errores
Cuando ocurre un error, el estado de los datos es crítico. Conocer simplemente que ocurrió un error a menudo no es suficiente. Necesitas saber por qué y qué datos lo causaron.
Variables de error
Los motores BPMN le permiten pasar variables a los controladores de errores. Asegúrese de que su modelo capture:
- Código de error: Un identificador estandarizado (por ejemplo, “ERR_101”).
- Mensaje de error: Una descripción legible para humanos para los registros.
- Datos de contexto: Datos comerciales relevantes (por ejemplo, ID de pedido, nombre del cliente) para ayudar en la resolución de problemas.
Persistencia de datos
Asegúrese de que los datos recopilados antes del error se persistan. No dependa de la memoria temporal. Si una instancia de proceso se detiene debido a un error, la siguiente instancia debe tener acceso al mismo contexto de datos para continuar el procesamiento.
🧪 Pruebas y validación de rutas de error
Modelar rutas de error es solo la mitad del trabajo. Debe verificar que funcionen correctamente en el entorno de tiempo de ejecución. Probar rutas de error requiere una mentalidad diferente a la de probar rutas exitosas.
Lista de verificación de validación ✅
- Lógica inaccesible: Asegúrese de que las rutas de error no creen bloqueos o nodos inaccesibles.
- Cobertura: Verifique que cada punto potencial de fallo tenga un manejador de errores correspondiente.
- Tiempo de espera: Pruebe lo que sucede cuando una tarea excede su límite de tiempo.
- Fallo de integración: Simule una caída de la API para asegurarse de que el evento de borde se active.
- Integridad de datos: Confirme que no quede ningún dato parcial después de un reintegro.
Herramientas de simulación
Utilice herramientas de simulación de procesos para inyectar fallos en el flujo de trabajo. Esto le permite observar cómo se comporta el proceso bajo estrés sin afectar los datos de producción. Busque:
- Terminación inesperada del proceso.
- Mensajes de error incorrectos que se registran.
- Fallo al notificar a las partes interesadas correctas.
🚧 Peligros comunes que deben evitarse
Incluso los modeladores experimentados cometen errores al diseñar el manejo de errores. Esté atento a estas trampas comunes.
1. Ignorar la ‘ruta feliz’
No ensucie el flujo principal con lógica de manejo de errores. Mantenga el flujo principal limpio. Utilice eventos de borde y subprocesos para aislar la lógica de errores. Esto hace que el modelo sea más fácil de leer y mantener.
2. Exceso de uso de eventos de borde
Adjuntar un evento de borde a cada tarea individual puede hacer que el diagrama sea desordenado y confuso. Solo los adjunte a tareas donde el fallo tenga un impacto significativo o requiera una lógica de manejo específica.
3. Mensajes de error ambiguos
Evite mensajes de error genéricos como «Algo salió mal». Use códigos y mensajes específicos que puedan entender tanto desarrolladores como usuarios de negocio. Esto facilita una resolución más rápida.
4. Falta de lógica de reintento
Los errores transitorios (como fallos de red) deben reintentarse. Modele los mecanismos de reintento explícitamente usando temporizadores o bucles. No permita que un error transitorio se convierta en un fallo permanente.
5. Olvidar tareas humanas
Las tareas humanas también fallan. Un usuario podría ignorar una tarea o ingresar datos inválidos. Defina qué sucede si una tarea humana se abandona o se rechaza. Esto a menudo requiere una ruta de error diferente a la de las tareas del sistema.
🔍 Monitoreo y preparación operativa
Una vez que el proceso está en producción, las rutas de error se convierten en su primera línea de defensa. El monitoreo es esencial para asegurarse de que estas rutas funcionen según lo previsto.
Métricas clave
- Tasa de errores: El porcentaje de instancias de proceso que alcanzan una ruta de error.
- Tiempo de resolución: Cuánto tiempo tarda en recuperarse de un error.
- Tasa de éxito de reintento: Con qué frecuencia los reintentos automáticos resuelven el problema.
Alertas
Configure alertas para rutas de error críticas. Si un código de error específico aumenta repentinamente, indica un problema sistémico que requiere atención inmediata. No trate todos los errores por igual; priorice aquellos que afectan los ingresos o el cumplimiento.
📝 Resumen de las mejores prácticas
Para asegurarse de que sus flujos de trabajo empresariales sean resilientes, adhiera a estos principios fundamentales:
- Modelado explícito: Nunca asuma que un error será manejado por el motor. Defínalo en el diagrama.
- Manejo granular: Use códigos de error específicos para redirigir al manejador correcto.
- Conciencia de datos: Preserve los datos de contexto durante los fallos para auditoría y depuración.
- Compensación: Planee la deshacer de acciones cuando sea necesario.
- Pruebas: Valide las rutas de error con la misma rigurosidad que el flujo principal.
Al invertir tiempo en modelar excepciones, construye procesos que no solo son eficientes, sino también robustos. Un error bien manejado a menudo es mejor que no tener ningún error, ya que mantiene la confianza y la claridad en el sistema. Enfóquese en la claridad, la precisión y la preparación operativa en sus modelos BPMN.
🔗 Siguientes pasos para la implementación
Comience auditando sus procesos existentes. Identifique las tareas de alto riesgo donde un fallo sería costoso. Modele primero los eventos de borde para estas tareas. Amplíe gradualmente a eventos intermedios y lógica de compensación. Este enfoque por fases garantiza estabilidad mientras mejora la resiliencia.
Documente su estrategia de manejo de errores. Cree una guía de referencia para desarrolladores y analistas que explique los códigos de error y los comportamientos esperados. Esta documentación se convierte en un activo fundamental para mantener el proceso con el tiempo.
Recuerde, el objetivo no es eliminar errores, sino gestionarlos de forma efectiva. Cuando modela claramente los caminos de error, permite que el sistema se recupere con elegancia y mantenga el negocio avanzando.

