











In der Landschaft moderner Geschäftsprozesse wird der Unterschied zwischen einem statischen Diagramm und einer dynamischen Engine oft durch die Struktur des zugrundeliegenden Prozessmodells bestimmt. Wenn Organisationen von der manuellen Ausführung zu automatisierten Workflows übergehen, wird die grundlegende Architektur des Business Process Model and Notation (BPMN) entscheidend. Dieser Leitfaden legt die strukturellen Anforderungen fest, die erforderlich sind, um sicherzustellen, dass Prozessmodelle weiterhin tragfähig, skalierbar und für Automatisierungstechnologien bereit sind.
Die Erstellung eines Prozessmodells heute erfordert Weitsicht für morgen. Ein gut strukturierter Modell fungiert als einziges Quellensystem und schließt die Lücke zwischen menschlicher Entscheidungsfindung und Systemausführung. Ohne eine ordnungsgemäße Strukturung bleiben Automatisierungsinitiativen oft auf der Integrationsstufe stecken und erfordern kostspielige Nacharbeiten. Die folgenden Abschnitte erläutern die architektonischen Prinzipien, Modellierungsstandards und Governance-Strategien, die erforderlich sind, um robuste Prozessdefinitionen zu erstellen.
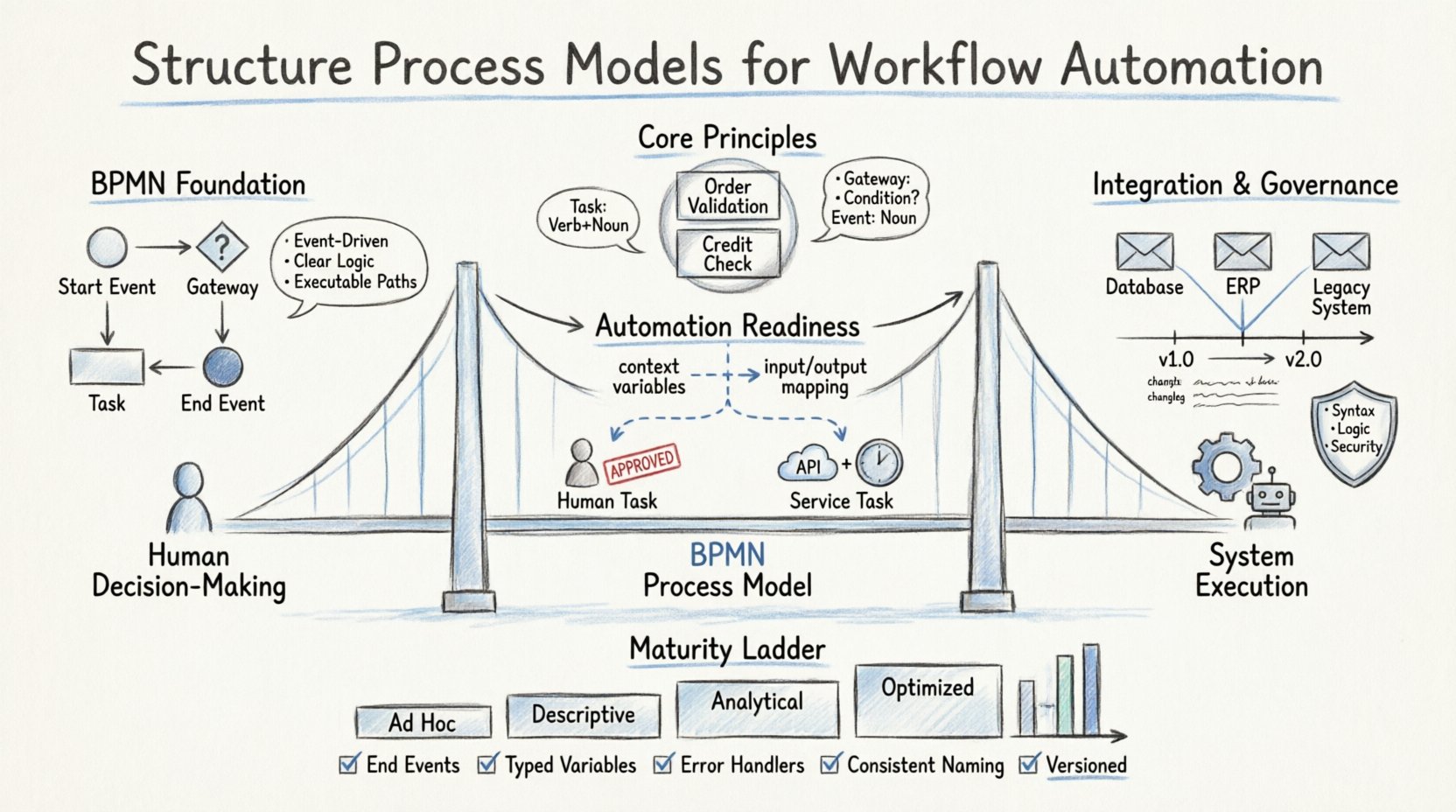
📐 Die Grundlage: Verständnis der BPMN-Standards
BPMN dient als Lingua Franca für die Prozessdokumentation. Die Einhaltung der Standard-Syntax ist jedoch erst der erste Schritt. Um Automatisierung zu unterstützen, muss das Modell strikt den Ausführungsregeln folgen. Das bedeutet, dass verstanden werden muss, wie Ereignisse, Gateways und Aufgaben innerhalb einer Laufzeit-Engine interagieren.
- Ereignisgesteuerte Architektur: Jeder Prozess muss einen klaren Start und eindeutiges Ende haben. Ereignisse lösen die Ablaufsteuerung aus. Automatisierungen setzen auf diese Auslöser, um Aktionen zu starten.
- Gateways für Logik: Gateways bestimmen den Ausführungsverlauf. Exklusive Gateways verarbeiten binäre Entscheidungen, während parallele Gateways die Konkurrenzsteuerung übernehmen. Automatisierungssysteme deuten diese als bedingten Code.
- Aufgabentypen: Menschliche Aufgaben erfordern Benutzeroberflächen. Dienst-Aufgaben lösen externe Systeme aus. Nachrichtenaufgaben verwalten asynchrone Kommunikation.
Beim Modellieren für die Automatisierung ist Klarheit entscheidend. Mehrdeutigkeit im Modell führt zu Mehrdeutigkeit im Code. Jeder Pfad muss ausführbar sein. Sackgassen und unerreichbare Schleifen sind häufige Fehler, die die Automatisierungslogik stören.
🚀 Kernprinzipien für skalierbares Modellieren
Skalierbarkeit geht nicht nur darum, Volumen zu bewältigen; es geht darum, Komplexität zu bewältigen, ohne das Modell zu beschädigen. Ein Prozess, der für eine einzelne Transaktion funktioniert, scheitert oft, wenn er auf Tausende skaliert wird. Die strukturelle Integrität stellt sicher, dass die Logik auch unter Last stabil bleibt.
1. Modulare Gestaltungsprinzipien
Statt monolithische Diagramme zu erstellen, verwenden Sie Unterprozesse, um Logik zu kapseln. Dies verbessert die Lesbarkeit und ermöglicht es Teams, an spezifischen Bereichen zu arbeiten, ohne den gesamten Prozess zu beeinflussen.
- Wiederverwendbare Unterprozesse: Erstellen Sie Standardblöcke für häufige Aktivitäten wie „Bestellprüfung“ oder „Kreditprüfung“.
- Trennung der Verantwortlichkeiten: Halten Sie den Orchestrierungsablauf von der detaillierten Implementierungslogik getrennt.
- Konsistenz der Schnittstellen: Stellen Sie sicher, dass Eingaben und Ausgaben für Unterprozesse in verschiedenen übergeordneten Prozessen konsistent bleiben.
2. Namenskonventionen
Konsistente Namensgebung reduziert die kognitive Belastung sowohl für Entwickler als auch für Geschäftssachverhalte. Eine klare Namenskonvention verhindert Verwirrung bei Audits oder der Fehlerbehebung.
| Elementtyp | Namenskonvention | Beispiel |
|---|---|---|
| Pool/Lane | Geschäftsrolle oder System | Kundenservice, ERP-System |
| Aufgabe | Verb + Substantiv (Vergangenheit oder Gegenwart) | Rechnung genehmigen, Benutzer validieren |
| Ereignis | Substantiv (Start/Ende) | Bestellung erhalten, Zahlung abgeschlossen |
| Gateway | Bedingungsfrage | Ist der Betrag > 500? Ist der Bestand verfügbar? |
🤖 Gestaltung für Automatisierungsfähigkeit
Die Automatisierung erfordert spezifische Datenstrukturen und Logikauslöser. Ein Prozessmodell, das für die manuelle Überprüfung konzipiert wurde, verfügt oft nicht über die notwendigen Anschlüsse für die robotergestützte Ausführung. Um Modelle für die Automatisierung vorzubereiten, sind spezifische Gestaltungsanpassungen erforderlich.
1. Definition des Datenpayloads
Automatisierungsmotoren erfordern strukturierte Daten, um funktionieren zu können. Jede Aufgabe im Modell sollte mit spezifischen Datenobjekten verknüpft sein. Dadurch wird sichergestellt, dass beim Auslösen einer Aufgabe der erforderliche Kontext zur Verfügung steht.
- Kontextvariablen: Definieren Sie Variablen auf Prozessebene, die während der gesamten Lebensdauer erhalten bleiben.
- Eingabe/Ausgabe-Zuordnung: Ordnen Sie externe API-Antworten eindeutig internen Variablen zu.
- Fehlerbehandlung: Definieren Sie, was geschieht, wenn Daten fehlen oder ungültig sind. Die Automatisierung kann nicht raten; sie muss definierten Regeln folgen.
2. Übergabe zwischen Mensch und System
Klare Grenzen zwischen menschlicher und systemischer Arbeit verhindern Engpässe. Wenn eine Aufgabe einem Menschen zugewiesen wird, wartet das System. Wenn sie einer Dienstleistung zugewiesen wird, geht das System weiter.
- Dienstleistungsaufgaben: Verwenden Sie diese für API-Aufrufe, Datenbankaktualisierungen und Dateiverarbeitung.
- Benutzeraufgaben: Verwenden Sie diese für Genehmigungen, Dateneingaben und komplexe Beurteilungsentscheidungen.
- Zeitgeberereignisse: Verwenden Sie diese, um SLAs durchzusetzen oder wiederkehrende automatisierte Prüfungen auszulösen.
🔗 Datenfluss und Integrationspunkte
Prozesse existieren nicht im Vakuum. Sie interagieren mit verschiedenen Systemen. Das Modell muss diese Integrationspunkte explizit darstellen, um die Datenintegrität zu gewährleisten. Ein fehlender Anschluss im Diagramm führt oft zu einer defekten Pipeline in der Produktion.
1. Externe Referenzen
Wenn ein Prozess mit einem externen System interagiert, modellieren Sie diese Interaktion als Nachrichten- oder Dienst-Aufgabe. Vereinfachen Sie dies nicht. Die Integrationslogik ist Teil des Prozessablaufs.
- Synchronisierte Aufrufe: Der Prozess wartet auf eine Antwort, bevor er fortfährt.
- Asynchrone Aufrufe: Der Prozess fährt fort und wartet auf ein Rückrufereignis.
- Dateischnittstellen: Stellen Sie Dateiablagen oder -uploads als Ereignisse oder Aufgaben dar.
2. Zustandsverwaltung
Die Zustandsverwaltung ist entscheidend für langlaufende Prozesse. Das Modell muss verfolgen, wo sich der Prozess in seinem Lebenszyklus befindet. Dadurch ist eine Wiederherstellung möglich, falls ein System ausfällt.
| Szenario | Modellierungsansatz | Auswirkungen auf die Automatisierung |
|---|---|---|
| Systemabsturz | Transaktionsgrenzen | Die Engine muss vom letzten Prüfpunkt aus fortsetzen |
| Zeitüberschreitung | Zeitgeber-Mittlere Ereignisse | Wiederholungslogik oder Eskalation auslösen |
| Ausnahme | Fehlergrenz-Ereignisse | Fehler auf Aufgabenebene, nicht auf Prozessebene abfangen |
🛡️ Governance- und Versionsstrategien
Wenn Prozesse sich weiterentwickeln, müssen auch die Modelle sich weiterentwickeln. Die Governance stellt sicher, dass Änderungen kontrolliert und dokumentiert werden. Ohne Versionsverwaltung ist es unmöglich zu verfolgen, welche Logik aktuell in der Produktion läuft.
1. Versionskontrolle
Jede Änderung am Prozessmodell sollte eine neue Version erzeugen. Dies ermöglicht A/B-Tests von Prozessänderungen und Rollback-Funktionen.
- Versionsnummern: Verwenden Sie semantische Versionsvergabe (Hauptversion.Nebenversion.Patch).
- Ablaufrichtlinien: Definieren Sie, wann alte Versionen eingestellt werden.
- Dokumentation: Fügen Sie Änderungsprotokolle in die Modellmetadaten ein.
2. Überprüfungsregeln
Bevor ein Modell bereitgestellt wird, muss es Überprüfungen bestehen. Dadurch wird sichergestellt, dass das Modell syntaktisch korrekt und logisch einwandfrei ist.
- Syntax-Prüfung: Sind alle Verbindungen gültig? Sind alle Elemente benannt?
- Logik-Prüfung: Gibt es endlose Schleifen? Sind alle Pfade abgedeckt?
- Sicherheitsprüfung: Sind sensible Daten geschützt?
🚫 Häufige Fehler, die vermieden werden sollten
Selbst erfahrene Modellierer können strukturelle Schwächen einführen. Die frühzeitige Erkennung dieser Fehler spart erhebliche Zeit während der Implementierungsphase.
- Überdimensionierung: Modellieren Sie nicht jeden Einzelfall im Hauptablauf. Verwenden Sie Fehlerbehandlungen für Ausnahmen.
- Hartkodierte Werte: Vermeiden Sie es, spezifische Werte (wie Daten oder IDs) direkt im Modell zu verankern. Verwenden Sie stattdessen Variablen.
- Fehlende Fehlerpfade: Jede Aufgabe sollte einen definierten Fehlerpfad haben. Die Automatisierung muss wissen, wie sie sich erholen kann.
- Komplexe Gateways: Zu viele verschachtelte Gateways machen die Logik schwer nachvollziehbar. Vereinfachen Sie Bedingungen, wo immer möglich.
📊 Messung der Modellgesundheit
Sobald ein Prozess aktiv ist, wird das Modell selbst zu einem Metrik. Sie können die Ausführungsdaten analysieren, um strukturelle Ineffizienzen zu identifizieren. Diese Rückkopplungsschleife hilft, die Prozessdefinition im Laufe der Zeit zu verfeinern.
- Ausführungszeit: Dauern bestimmte Aufgaben länger als erwartet? Dies könnte auf einen Optimierungsbedarf hindeuten.
- Identifikation von Engpässen: Wo stoppen Prozesse? Gateways oder menschliche Aufgaben sind häufige Engpässe.
- Pfadhäufigkeit: Werden bestimmte Zweige selten genutzt? Dies könnte auf unnötige Komplexität hindeuten.
🔍 Reifegradstufen im Prozessmodellieren
Organisationen durchlaufen verschiedene Stadien der Modellierungsreife. Das Verständnis Ihres aktuellen Niveaus hilft, realistische Ziele für die Automatisierungsfähigkeit zu setzen.
| Stufe | Eigenschaften | Automatisierungspotenzial |
|---|---|---|
| Stufe 1: Ad Hoc | Informelle Diagramme, keine standardisierte Notation. | Keines. Erfordert eine vollständige Neugestaltung. |
| Stufe 2: Beschreibend | BPMN-Notation verwendet, aber die Logik ist unscharf. | Niedrig. Erfordert erhebliche Aufräumarbeiten. |
| Stufe 3: Analytisch | Klare Logik, definierte Datenflüsse, Fehlerbehandlung. | Mittel. Bereit für grundlegende Dienste. |
| Stufe 4: Optimiert | Modular, versioniert, gemanagt und überwacht. | Hoch. Bereit für komplexe Orchestrierung. |
🧩 Implementierungs-Checkliste
Bevor Sie ein Prozessmodell in eine Automatisierungsumgebung bereitstellen, durchlaufen Sie diese Checkliste, um die strukturelle Integrität zu gewährleisten.
- ✅ Führt jeder Pfad zu einem End-Ereignis?
- ✅ Sind alle Variablen korrekt definiert und typisiert?
- ✅ Sind Fehler-Grenzereignisse an Dienst-Aufgaben angehängt?
- ✅ Sind Integrationspunkte eindeutig gekennzeichnet?
- ✅ Ist die Namenskonvention im gesamten Diagramm konsistent?
- ✅ Werden Unterprozesse eingesetzt, um die Komplexität zu steuern?
- ✅ Ist das Modell versioniert und dokumentiert?
- ✅ Sind alle Geschäftsregeln in Gateways oder Skripte übersetzt worden?
🔄 Kontinuierliche Verbesserung
Prozessmodellierung ist keine einmalige Tätigkeit. Es handelt sich um einen kontinuierlichen Zyklus aus Gestaltung, Ausführung und Analyse. Wenn sich die Geschäftsanforderungen ändern, müssen die Modelle sich anpassen. Die Struktur, die Sie heute aufbauen, sollte diese zukünftigen Änderungen ermöglichen, ohne dass eine vollständige Neugestaltung erforderlich ist.
Durch Fokus auf Modularität, klare Datenflüsse und strikte Einhaltung der BPMN-Standards schaffen Sie eine Grundlage, die die Automatisierung heute und in Zukunft unterstützt. Das Ziel ist nicht nur, das Geschehen zu dokumentieren, sondern zu definieren, wie es auf eine Weise geschehen soll, die Maschinen verstehen und zuverlässig ausführen können.
Beginnen Sie mit den Grundlagen. Stellen Sie sicher, dass der Ablauf logisch ist. Fügen Sie die Daten hinzu. Definieren Sie die Fehler. Dann automatisieren. Dieser disziplinierte Ansatz liefert die stabilsten und wartungsfreundlichsten Workflow-Lösungen.

